深度解析:模式分类的关键技术与挑战
本资源主要围绕"模式分类"这一主题展开,涵盖了机器感知、模式识别和机器学习的广泛内容。在第一章"Introduction"中,作者首先强调了模式识别在日常生活中所扮演的重要角色,如人脸识别、语音理解、手写字符识别等复杂任务。这些任务揭示了隐藏在其背后的极其复杂的认知过程。
章节详细探讨了一系列模式分类中的关键子问题:
1. **机器感知(Machine Perception)**:这是基础,指计算机如何通过传感器接收并解析环境中的信息,以形成对周围世界的理解。
2. **实例分析(An Example)**:通过具体例子来阐述模式分类的概念和应用,使读者能更好地理解其实际操作。
3. **子问题与挑战**:
- **特征提取(Feature Extraction)**:指从原始数据中挑选出对模式识别有用的特征,这直接影响到模型的性能。
- **噪声(Noise)**:处理数据中的不准确或随机干扰,保证模型的鲁棒性。
- **过拟合(Overfitting)**:当模型过于复杂,过度适应训练数据,导致在新数据上的泛化能力下降。
- **模型选择(Model Selection)**:确定最适合特定任务的模型,避免简单或复杂度过高。
- **先验知识(Prior Knowledge)**:利用已知的信息或假设指导模型设计,提升学习效率。
- **缺失特征(Missing Features)**:处理数据中缺失的数据点,可能需要通过插补或其他方法进行处理。
- **mereology(部分-整体关系)**:理解事物由哪些部分组成,对整体进行分类。
- **分割(Segmentation)**:将图像或信号分解成更小的有意义的部分。
- **上下文(Context)**:考虑环境因素对模式识别的影响,如语境信息。
- **不变性(Invariances)**:确保模型在不同情况下仍能正确识别。
- **证据融合(Evidence Pooling)**:整合多个来源的信息以做出更准确的判断。
- **成本与风险(Costs and Risks)**:评估决策过程中的代价和潜在错误。
- **计算复杂度(Computational Complexity)**:权衡模型的效率和性能。
4. **学习与适应(Learning and Adaptation)**:
- **监督学习(Supervised Learning)**:基于标记数据训练模型,是最常见的学习方式。
- **无监督学习(Unsupervised Learning)**:在无标签数据中寻找结构或模式,如聚类或降维。
- **强化学习(Reinforcement Learning)**:通过与环境互动,学习最优策略。
5. **结论**:总结章节内容,强调模式分类在实际应用中的核心地位和不断发展的技术趋势。
此外,资源还包含章节概览、历史和文献评论、参考文献列表以及索引,为深入研究提供了丰富的背景资料和学术支持。整个文档旨在为读者提供一个全面而深入的理解模式分类及其在现代信息技术中的作用。

4 CHAPTER 1. INTRODUCTION
images — variations in lighting, position of the fish on the conveyor, even “static”
due to the electronics of the camera itself.
Given that there truly are differences between the population of sea bass and that
of salmon, we view them as having different models — different descriptions, whichmodel
are typically mathematical in form. The overarching goal and approach in pattern
classification is to hypothesize the class of these models, process the sensed data
to eliminate noise (not due to the models), and for any sensed pattern choose the
model that corresponds best. Any techniques that further this aim should be in the
conceptual toolbox of the designer of pattern recognition systems.
Our prototype system to perform this very specific task might well have the form
shown in Fig. 1.1. First the camera captures an image of the fish. Next, the camera’s
signals are preprocessed to simplify subsequent operations without loosing relevantpre-
processing information. In particular, we might use a segmentation operation in which the images
segmentation
of different fish are somehow isolated from one another and from the background. The
information from a single fish is then sent to a feature extractor, whose purpose is to
feature
extraction
reduce the data by measuring certain “features” or “properties.” These features
(or, more precisely, the values of these features) are then passed to a classifier that
evaluates the evidence presented and makes a final decision as to the species.
The preprocessor might automatically adjust for average light level, or threshold
the image to remove the background of the conveyor belt, and so forth. For the
moment let us pass over how the images of the fish might be segmented and consider
how the feature extractor and classifier might be designed. Suppose somebody at the
fish plant tells us that a sea bass is generally longer than a salmon. These, then,
give us our tentative models for the fish: sea bass have some typical length, and this
is greater than that for salmon. Then length becomes an obvious feature, and we
might attempt to classify the fish merely by seeing whether or not the length l of
a fish exceeds some critical value l
∗
. To choose l
∗
we could obtain some design or
training samples of the different types of fish, (somehow) make length measurements,training
samples and inspect the results.
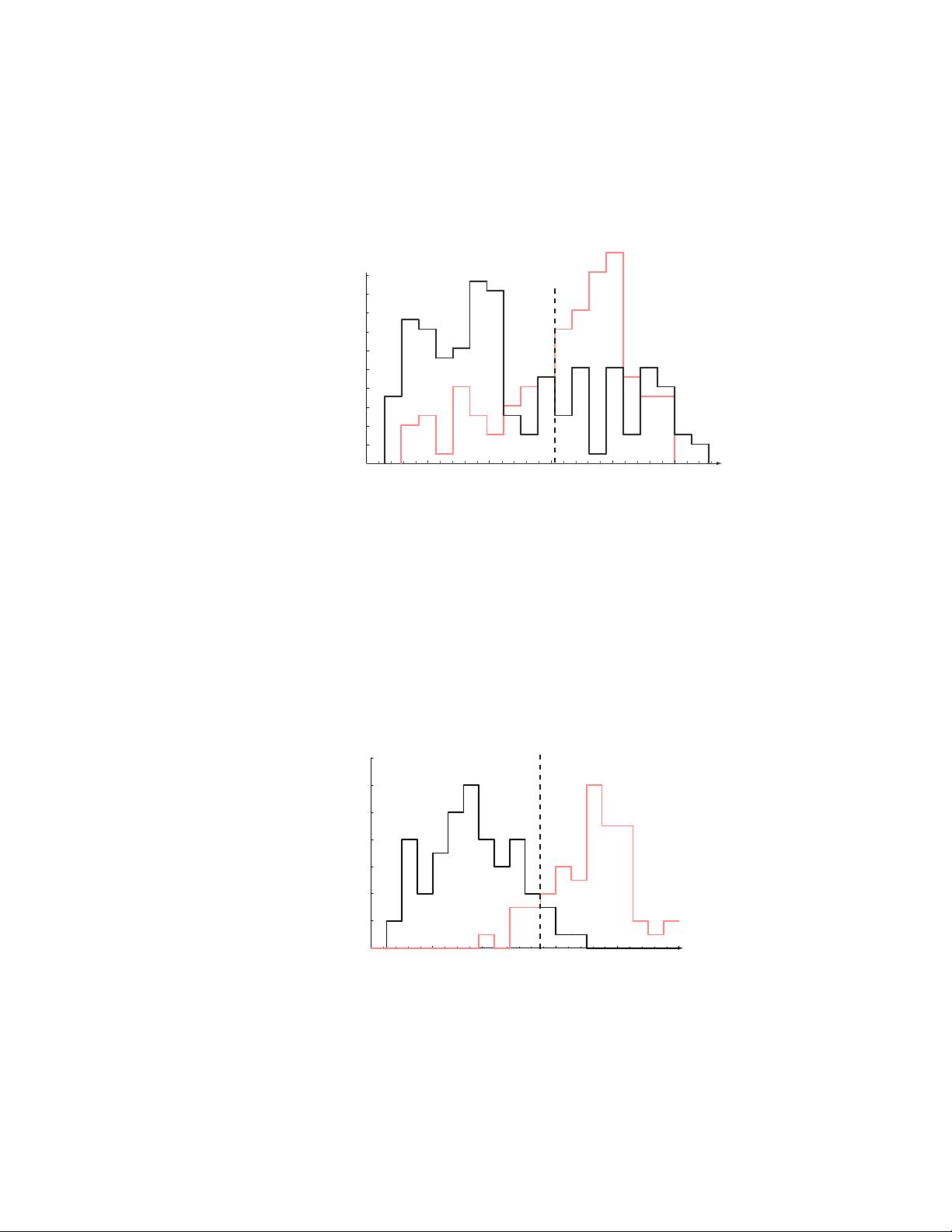
Suppose that we do this, and obtain the histograms shown in Fig. 1.2. These
disappointing histograms bear out the statement that sea bass are somewhat longer
than salmon, on average, but it is clear that this single criterion is quite poor; no
matter how we choose l
∗
, we cannot reliably separate sea bass from salmon by length
alone.
Discouraged, but undeterred by these unpromising results, we try another feature
— the average lightness of the fish scales. Now we are very careful to eliminate
variations in illumination, since they can only obscure the models and corrupt our
new classifier. The resulting histograms, shown in Fig. 1.3, are much more satisfactory
— the classes are much better separated.
So far we have tacitly assumed that the consequences of our actions are equally
costly: deciding the fish was a sea bass when in fact it was a salmon was just as
undesirable as the converse. Such a symmetry in the cost is often, but not invariablycost
the case. For instance, as a fish packing company we may know that our customers
easily accept occasional pieces of tasty salmon in their cans labeled “sea bass,” but
they object vigorously if a piece of sea bass appears in their cans labeled “salmon.”
If we want to stay in business, we should adjust our decision boundary to avoid
antagonizing our customers, even if it means that more salmon makes its way into
the cans of sea bass. In this case, then, we should move our decision boundary x
∗
to
smaller values of lightness, thereby reducing the number of sea bass that are classified
as salmon (Fig. 1.3). The more our customers object to getting sea bass with their



剩余737页未读,继续阅读
2023-10-30 上传
2023-08-08 上传
2023-06-10 上传
2023-05-13 上传
2023-05-10 上传
2023-06-09 上传

思考熊
- 粉丝: 92
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
