Hadoop 2.x 学习指南:核心模块与生态详解
Hadoop2.x 是一个强大的开源分布式计算框架,用于处理海量数据。这份学习资料详尽介绍了Hadoop2.x 的核心组件以及相关的技术应用,对于深入理解Hadoop 的工作原理和实际操作具有很高的价值。
首先,关于处理大文件中的重复行问题,作者提出了两种思路。思路1 采用迭代和内存操作的方式,通过逐行比较实现,类似于冒泡排序,适合于内存足够处理部分数据的情况。而思路2 则利用Hadoop 的特点,将大文件切分成小文件,并通过哈希函数将数据映射到不同的文件中,这样可以有效地利用分布式环境,降低单台机器的压力。
Hadoop 的三大核心模块是其核心技术基石:
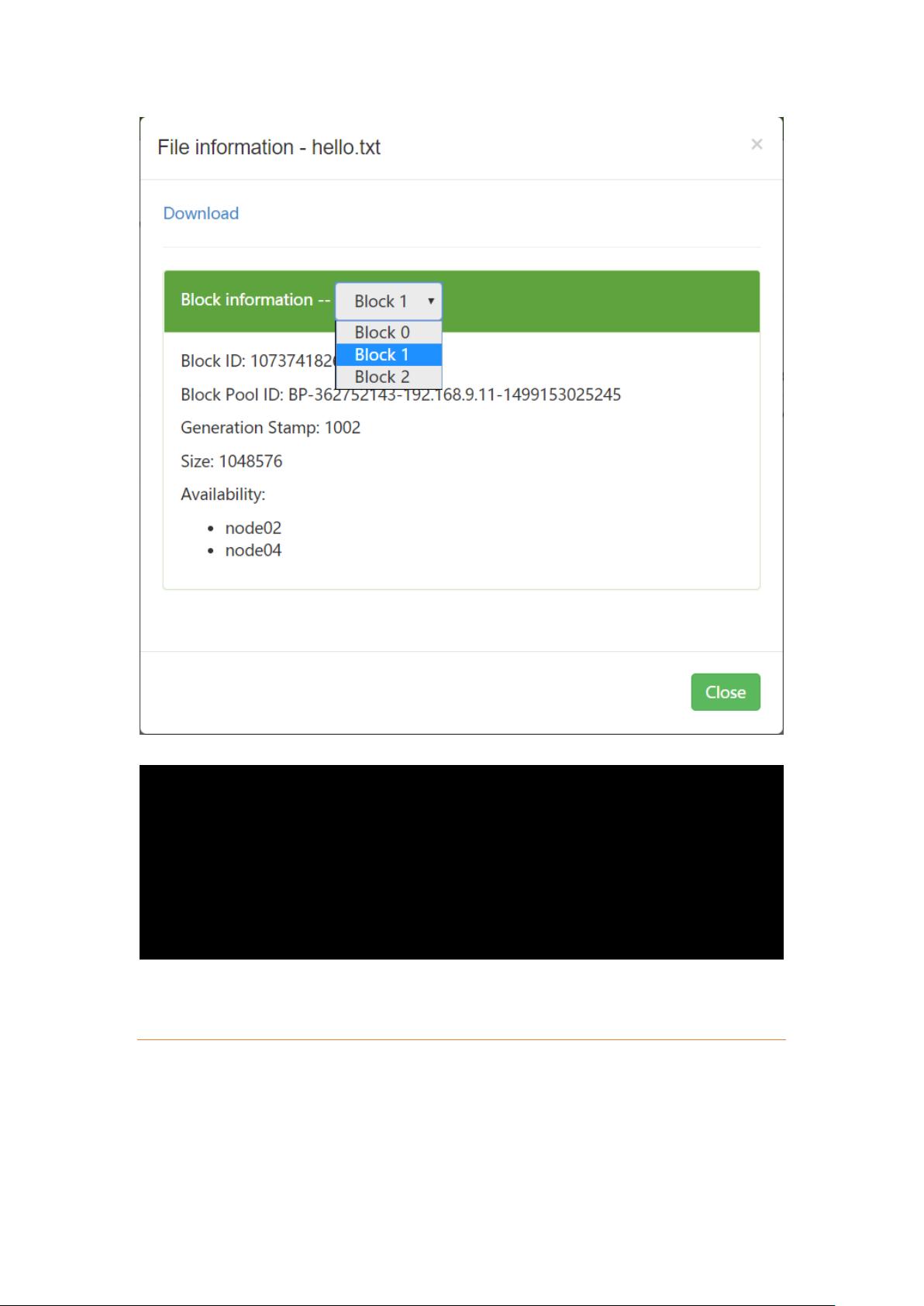
1. **Hadoop Distributed File System (HDFS)**: 作为分布式存储系统,HDFS 为大数据处理提供了高可靠性和扩展性。HDFS 将大文件切割成固定大小的Block,分布在多个节点上,支持一次写入多次读取,但不支持修改现有数据(因为修改会引发全网的同步操作)。此外,它支持append模式追加数据,且允许设置Block的副本数,提高数据冗余和可用性。
2. **MapReduce**: 这是一种分布式计算模型,简化了程序员编写并行处理任务的难度。它由Map阶段(将输入数据分片并执行函数处理)和Reduce阶段(合并中间结果生成最终输出)组成,具有容错性和扩展性,非常适合处理大规模数据处理任务。
3. **YARN (Yet Another Resource Negotiator)**: 作为Hadoop的下一代资源管理框架,YARN 负责整个集群的资源管理和调度,使得MapReduce作业和其他应用程序能够更高效地共享硬件资源。
Hadoop的生态系统丰富多样,包括但不限于:
- **Hive**: 一个基于SQL的数据仓库工具,便于数据分析人员进行查询和报表生成。
- **HBase**: 一个分布式列式存储系统,适合于实时查询和大规模数据处理。
- **Spark**: 实时计算框架,提供了比MapReduce更快的处理速度,尤其适合迭代计算任务。
在Hadoop的分布式存储系统HDFS中,关键概念包括文件元数据(如权限、名称等)和数据本身。NameNode作为元数据存储的中心节点,维护着文件系统的命名空间,而DataNode则负责实际的数据存储和复制。HdfsClient与NameNode交互,获取文件的元数据信息,进一步实现文件的访问和操作。
这份学习资料涵盖了Hadoop2.x 的基础理论、核心组件以及实战应用,无论是对初学者还是进阶者来说,都是深入理解和掌握Hadoop 非常重要的参考资料。

</property>
</configuration>
[root@node01 hadoop]# vi slaves
node02
node03
node04
4. 将 node01 的 hadoop 安装目录分发给其他节点
[root@node01 sxt]# scp -r hadoop-2.6.5 node02:`pwd`
[root@node01 sxt]# scp -r hadoop-2.6.5 node03:`pwd`
[root@node01 sxt]# scp -r hadoop-2.6.5 node04:`pwd`
5. 格式化文件系统(只在第一次启动时格式化)
[root@node01 sxt]# hdfs namenode -format
6. 启动服务
[root@node01 sxt]# start-dfs.sh
Starting namenodes on [node01]
node01: starting namenode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-namenode-
node01.out
node04: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-
node04.out
node02: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-
node02.out
node03: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-
node03.out
Starting secondary namenodes [node02]
node02: starting secondarynamenode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-
secondarynamenode-node02.out
7. 进行一些操作
[root@node01 ~]# for i in `seq 100000`;do echo "$i Hello sxt You Are Good" >>
/tmp/hello.txt;done
[root@node01 ~]# hdfs dfs -D dfs.blocksize=1048576 -put /tmp/hello.txt
#hdfs 切割文件时,按照字节来切分,思考,如果是中文,怎么切割?



剩余114页未读,继续阅读
2018-03-05 上传
2024-01-19 上传
2024-07-24 上传
2023-07-02 上传
2024-09-14 上传
2024-06-20 上传
2023-06-06 上传

独照松月冷别赋
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
