
关键概念:贪心算法
通过实现局部最优来达到接近全局最优结果的算法,所有的树模型都是这样的算法。
重要概念:不纯度
决策树的每个叶子节点中都会包含一组数据,在这组数据中,如果有某一类标签占有较大的比例,我们就说叶子
节点“纯”,分枝分得好。某一类标签占的比例越大,叶子就越纯,不纯度就越低,分枝就越好。
如果没有哪一类标签的比例很大,各类标签都相对平均,则说叶子节点”不纯“,分枝不好,不纯度高。
要在这么多棵决策树中去一次性找到分类效果最佳的那一棵是不可能的,如果通过排列组合来进行筛选,计算量过于
大而且低效,因此我们不会这样做。相对的,机器学习研究者们开发了一些有效的算法,能够在合理的时间内构造出
具有一定准确率的次最优决策树。这些算法基本都执行”贪心策略“,即通过局部的最优来达到我们相信是最接近全局
最优的结果。
最典型的决策树算法是Hunt算法,该算法是由Hunt等人提出的最早的决策树算法。现代,Hunt算法是许多决策树算
法的基础,包括ID3、C4.5和CART等。Hunt算法诞生时间较早,且基础理论并非特别完善,此处以应用较广、理论
基础较为完善的ID3算法的基本原理开始,讨论如何利用局部最优化方法来创建决策模型。
1.2.1 ID3算法构建决策树
ID3算法原型见于J.R Quinlan的博士论文,是基础理论较为完善,使用较为广泛的决策树模型,在此基础上J.R
Quinlan进行优化后,陆续推出了C4.5和C5.0决策树算法,后二者现已称为当前最流行的决策树算法,我们先从ID3
开始讲起,再讨论如何从ID3逐渐优化至C4.5。
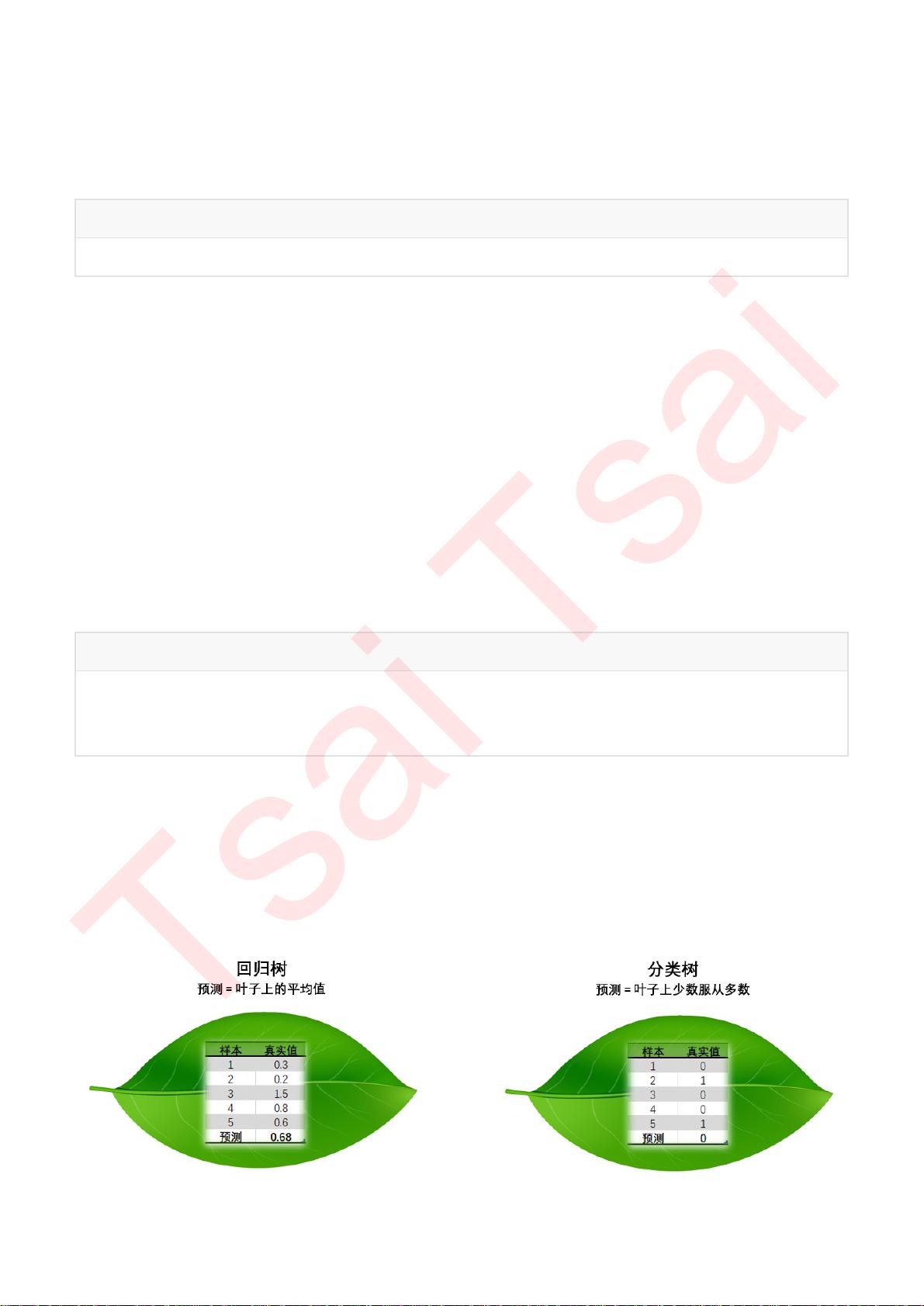
为了要将表格转化为一棵树,决策树需要找出最佳节点和最佳的分枝方法,而衡量这个“最佳”的指标叫做“不纯度”。
不纯度基于叶子节点来计算的,所以树中的每个节点都会有一个不纯度,并且子节点的不纯度一定是低于父节点的,
也就是说,在同一棵决策树上,叶子节点的不纯度一定是最低的。
这个其实非常容易理解。分类型决策树在叶子节点上的决策规则是少数服从多数,在一个叶子节点上,如果某一类标
签所占的比例较大,那所有进入这个叶子节点的样本都回被认为是这一类别。距离来说,如果90%根据规则进入叶子
节点的样本都是类别0(叶子比较纯),那新进入叶子节点的测试样本的类别也很有可能是0。但是,如果51%的样本
是0,49%的样本是1(极端情况),叶子节点还是会被认为是0类叶子节点,但此时此刻进入这个叶子的测试样本点
几乎有一半的可能性应该是类别1。从数学上来说,类分布为(0,100%)的结点具有零不纯性,而均衡分布
(50%,50%)的结点具有最高的不纯性。如果叶子本身不纯,那测试样本就很有可能被判断错误,相对的叶子越
纯,那样本被判断错误的可能性就越小。
Tsai Tsai
菜菜的sklearn课堂直播间: https://live.bilibili.com/12582510
sklearn专题第一期:决策树原理
剩余12页未读,继续阅读

无能为力就要努力
- 粉丝: 17
- 资源: 332
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


