HBase架构解析:分布式列式存储的基石
174 浏览量
更新于2024-08-27
收藏 376KB PDF 举报
"详解HBase架构原理"
HBase是一种分布式、列式存储的NoSQL数据库,源自Google的BigTable论文,是Apache Hadoop生态系统的组成部分。它被设计用来处理海量数据,支持高并发读写操作,并可在廉价硬件上构建大规模的存储集群。
1. **HBase的存储系统**
HBase利用Hadoop的HDFS作为底层的文件存储系统,这使得HBase能够拥有高可靠性和容错性。HDFS的设计目标是处理大量数据,而HBase则负责提供快速的数据访问。
2. **数据处理**
类似于BigTable通过MapReduce处理大数据,HBase也依赖Hadoop的MapReduce框架进行批量数据处理。这种设计允许HBase处理PB级别的数据,同时保持良好的性能。
3. **协同服务**
Google BigTable使用Chubby作为协作服务,确保分布式环境中的数据一致性。在HBase中,这一角色由Zookeeper承担,Zookeeper负责协调HBase的各个组件,如Master节点和RegionServer,确保集群的稳定运行。
4. **HBase设计模型**
- **行与列**:每个表由行和列构成,行由唯一的RowKey标识,列则由列簇(Column Family)和列标签(Column Qualifier)定义。RowKey的设计至关重要,因为它决定了数据的物理排序和访问效率。
- **时间戳**:每个数据单元都有一个时间戳,用于版本控制和历史数据保留。
- **列簇**:列簇是一组相关的列,所有属于同一列簇的列在物理存储上靠近,有利于提高访问速度。列簇内的列标签可以动态添加,提供了灵活性。
5. **逻辑存储模型**
- **RowKey**:RowKey是表中行的唯一标识,决定了行的排序方式。设计合理的RowKey可以优化查询性能,例如,通过将相关数据的RowKey设计得相近,可以减少磁盘I/O,提高读取效率。
- **列簇**:列簇是列的逻辑分组,所有列都必须属于一个或多个列簇。列簇在创建表时定义,而列标签可以在运行时动态添加。
- **数据访问**:HBase提供了基于RowKey的精确访问、范围访问和全表扫描三种访问方式。
6. **HBase的分布式架构**
HBase通过RegionServer进行数据分区,每个RegionServer管理一部分Region,Region包含表的一部分行。当Region大小达到预设阈值时,Region会被自动分裂,以保持性能。Master节点负责RegionServer的监控和Region的分配。
7. **读写流程**
- **读操作**:HBase首先通过RowKey找到对应的RegionServer,然后在该服务器上查找数据。如果数据不存在,HBase会回退到更早的时间戳版本。
- **写操作**:写操作首先写入内存中的MemStore,当MemStore达到一定大小后,会被持久化到HDFS,并形成一个新的HFile。多个HFile合并成一个HBase的Region。
8. **HBase与Hadoop的关系**
HBase是Hadoop生态系统的一部分,两者共同构建了大数据处理的基础设施。HBase利用Hadoop的HDFS提供存储,同时,MapReduce用于处理批量任务,如数据导入和复杂分析。
HBase是一个强大的分布式数据库,尤其适用于需要实时查询大规模结构化数据的场景。理解其架构原理对于有效地设计和使用HBase至关重要。
详解详解HBase架构原理架构原理
一、什么是HBase
HBase是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价的PC Server上搭建大规模结构
化存储集群。
HBase是Google BigTable的开源实现,与Google BigTable利用GFS作为其文件存储系统类似,HBase利用Hadoop HDFS作
为其文件存储系统;
Google运行MapReduce来处理BigTable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;
Google BigTable利用Chubby作为协同服务,HBase利用Zookeeper作为协同服务。
二、HBase设计模型
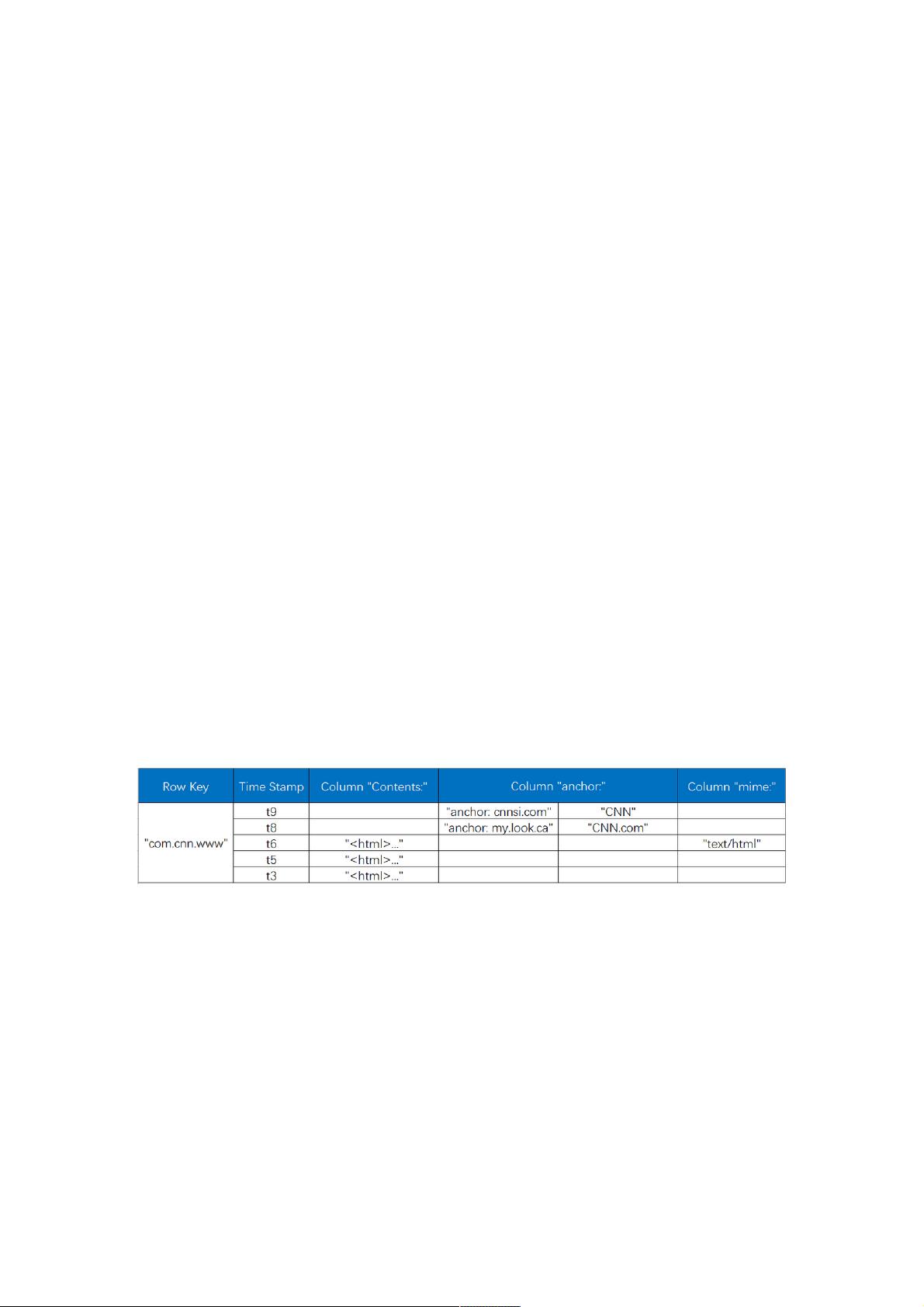
HBase中的每一张表就是所谓的BigTable。BigTable会存储一系列的行记录,行记录有三个基本类型的定义:
1.RowKey
是行在BigTable中的唯一标识。
2.TimeStamp:
是每一次数据操作对应关联的时间戳,可以看作SVN的版本。
3.Column:
定义为<family>:<label>,通过这两部分可以指定唯一的数据的存储列,family的定义和修改需要对HBase进行类似于DB的
DDL操作,
而label,不需要定义直接可以使用,这也为动态定制列提供了一种手段。family另一个作用体现在物理存储优化读写操作上,
同family
的数据物理上保存的会比较接近,因此在业务设计的过程中可以利用这个特性。
1. 逻辑存储模型
HBase以表的形式存储数据,表由行和列组成。列划分为若干个列簇,如下图所示:
下面是对表中元素的详细解析:
RowKey
与NoSQL数据库一样,rowkey是用来检索记录的主键。访问HBase Table中的行,只有三种方式:
1.通过单个rowkey访问
2.通过rowkey的range
3.全表扫描
rowkey行键可以任意字符串(最大长度64KB,实际应用中长度一般为10-100bytes),在HBase内部RowKey保存为字节数
组。
存储时,数据按照RowKey的字典序(byte order)排序存储,设计key时,要充分了解这个特性,将经常一起读取的行存放在
一起。
需要注意的是:行的一次读写是原子操作(不论一次读写多少列)
列簇
下载后可阅读完整内容,剩余4页未读,立即下载
302 浏览量
点击了解资源详情
213 浏览量
157 浏览量
717 浏览量
点击了解资源详情
164 浏览量
点击了解资源详情
126 浏览量

weixin_38743506
- 粉丝: 351
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







