卢亿雷分享:Hadoop应用实践与挑战解析
在Hadoop 10周年庆典上,AdMaster技术副总裁卢亿雷分享了关于Hadoop应用和实践中的经验与教训。他首先探讨了Hadoop数据平台架构,包括MapReduce作为其核心分布式计算模型,以及如何利用其他工具如Storm进行实时流处理、Open API支持数据采集和Crawler抓取文本数据,进一步通过Text Categorization和Clustering进行文本分析,甚至实现Sentiment Analysis。他还强调了数据挖掘和前端应用服务的重要性,以及如何通过API接口如Text Analysis API进行数据处理。
Hadoop系统平台架构方面,卢亿雷讲解了HDFS(Hadoop分布式文件系统)在存储海量数据的角色,以及离线计算平台如MapReduce、Pig和Hive用于批处理数据的流程。他还提到了Zookeeper在协调集群管理中的作用,以及在线计算场景下的HBase、实时计算框架如Spark和YARN资源管理器。此外,他还提到了Cascading和Flink这类数据流水线工具,以及如何利用消息队列KafkaMQ和NoSQL数据库如MySQL、MongoDB等来支持应用服务。
在面对大规模数据挑战时,卢亿雷指出每天可能处理高达5TB的新数据,并执行对数十亿条记录的复杂维度分析。他还分享了离线分析和在线分析的区别,比如如何在离线环境中通过Pig的算法执行大量数据处理,而在实时计算中则可能使用MySQL或Elasticsearch等数据库。
核心应用模块部分,卢亿雷介绍了SocialCRM、数据中心和分析报告等业务场景的应用,以及Track系统、Site系统和算法服务等关键组件。他还提到了NLP(自然语言处理)技术在情感分析、标签分类和NLP Lab中的应用,以及数据采集服务和社交平台的整合。
在技术层面,卢亿雷详细列举了Hadoop生态中的各种工具和技术,如NFS和HDFS的选择,Pig和Hive在不同场景的使用,以及MapReduce和Spark在数据处理中的切换。此外,他还讨论了如何通过API和DSL(领域特定语言)来管理和操作原始数据,以及如何构建数据处理管道以支持Buzz文章的爬虫服务。
卢亿雷的分享涵盖了Hadoop技术的全面应用,从基础架构到实际业务场景,以及如何避免和解决在Hadoop使用过程中遇到的各种问题,为听众提供了丰富的实践经验参考。
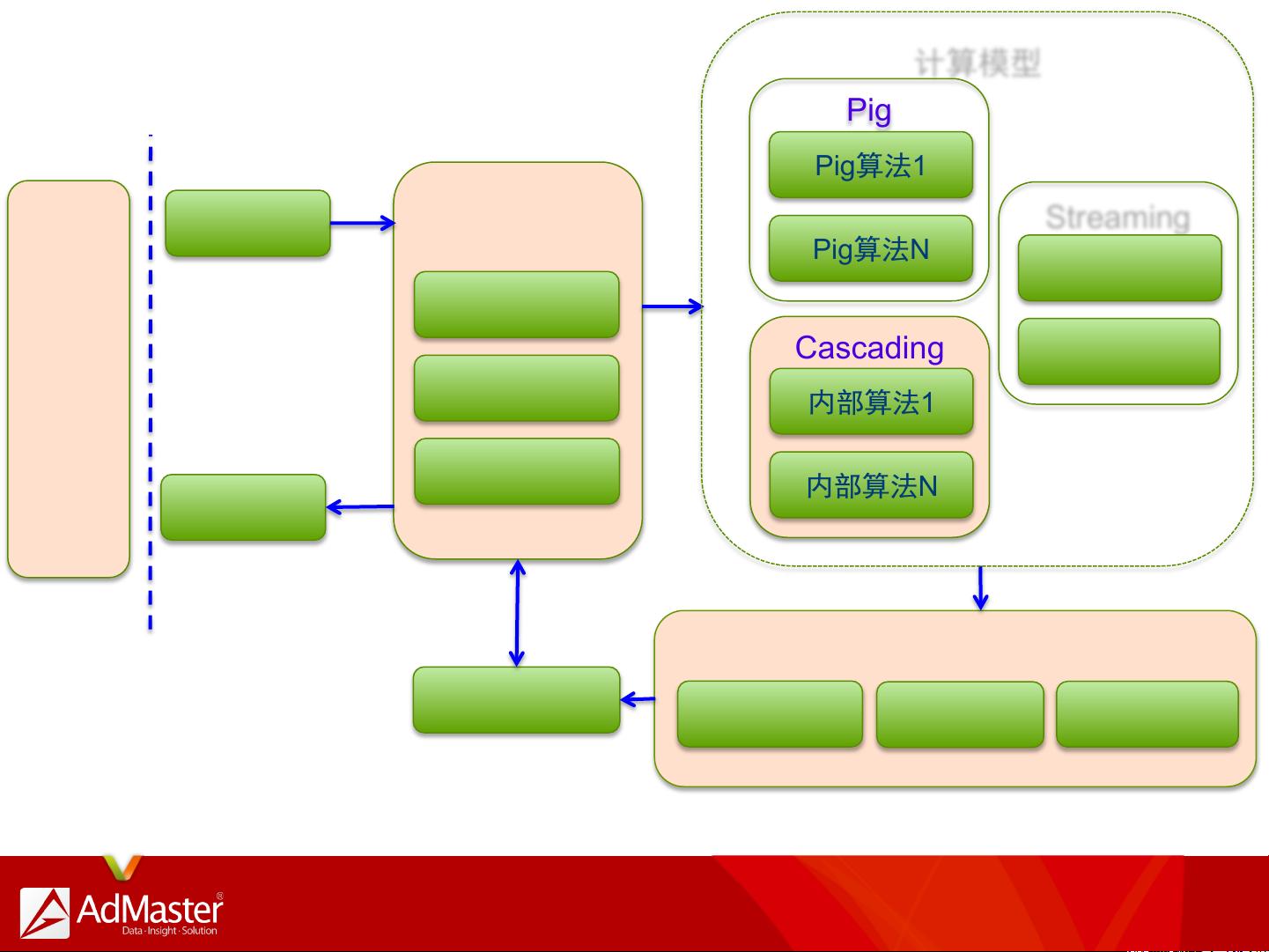
Pig
离线数据分析
输入拆分
任务调度
输出合并
Pig算法1
Pig算法N
Hadoop
MapReduce
Storm
MySQL
•
每天新增5TB级数据
•
每天对千亿条记录进行几百种维度的计算
Cascading
内部算法1
内部算法N
计算模型
Streaming
非固定算法1
非固定算法N
RabbitMQ
Redis
FieServer
HBase
Client
剩余23页未读,继续阅读
2015-06-23 上传
2014-12-18 上传
点击了解资源详情
点击了解资源详情
2023-09-03 上传
2023-07-02 上传
2023-11-28 上传
2023-07-30 上传

周建丁
- 粉丝: 1215
- 资源: 150
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
