小米AI团队分享NLPCC小模型预训练推理优化实战
版权申诉
143 浏览量
更新于2024-07-05
收藏 1.63MB PDF 举报
"《4-7+预训练在小米的推理优化落地》一文主要探讨了在小米AI实验室-NLP团队的背景下,如何应对中文自然语言处理领域轻量级模型资源匮乏的问题。文章聚焦于NLPCC 2020年的小模型大赛,该赛事由CLUE组织,旨在推动中文语言模型的发展,特别是针对小规模模型的优化和性能提升。大赛吸引了众多知名机构参与,如MSRA、华为和小米,其中小米在比赛中取得了显著成绩,展示了其在推理优化方面的实力。
在NLP中,预训练是一个关键环节,它通过在大规模文本数据上预先训练模型,学习通用的语言特征,然后在特定任务上微调以提高性能。比赛涉及到多种NLP任务,如句子分类、句对关系判断、序列标注(如命名实体识别)、阅读理解以及指代消歧等,这些都是评估模型综合能力的重要指标。
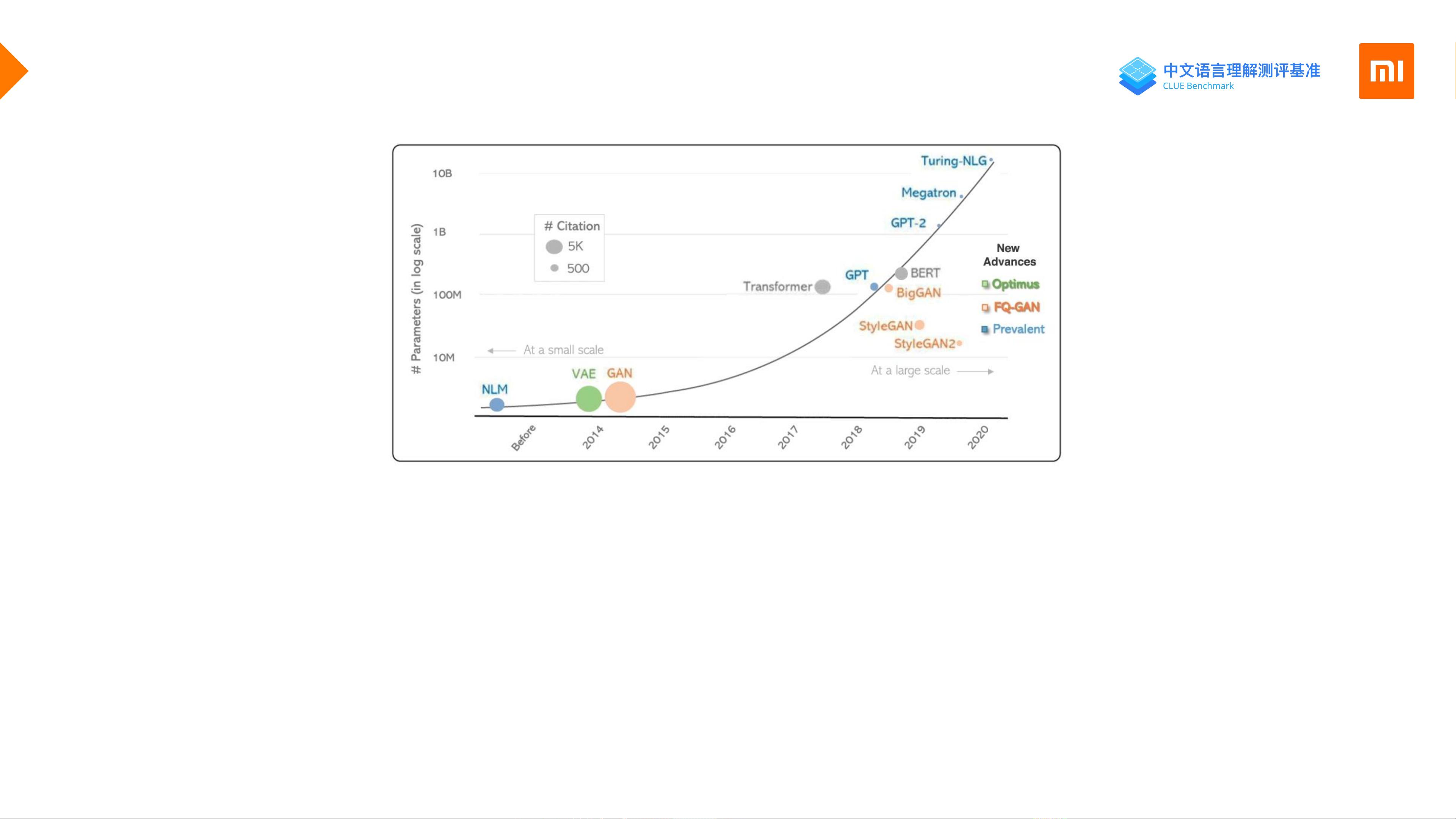
然而,传统的预训练方法面临效率问题,如需处理大量数据(超过100GB),这可能导致模型训练耗时较长,一台V100显卡可能需要2-3个月才能完成。特别是对于大模型,这种效率问题更为突出。小米团队在这篇文章中分享了他们在推理效率优化上的实践经验,包括但不限于模型剪枝、量化、低秩分解等技术,以减少模型大小和计算需求,同时保持或提升模型在实际任务中的表现。
通过参加NLPCC预训练小模型比赛,参赛者有机会获得丰厚的奖金和官方认证,如1万元人民币的第一名奖励,以及双周赛中的现金奖励、证书和额外资源(如200GB中文预训练语料)。双周赛的举办频率为每两周一次,提供了一个持续学习和优化的机会,鼓励创新和进步。
总结部分强调了预训练在实际应用中的重要性,尤其是在小米这样的公司中实现推理优化的落地。通过比赛,不仅推动了技术创新,还促进了业界对轻量级模型高效利用的研究和发展。这篇文章对于对NLP有志者来说,是一份宝贵的实战经验和策略指导,特别是对于那些寻求提高模型效率并将其应用于实际产品中的开发者和研究者。"
背景介绍 - 效率问题
训练
• > 100G语料
• 1台V100需要2 - 3个月
• 大模型 or 蒸馏 or 小模型?
推理
• 延迟太高?P99 > xxx ms
• 需要的GPU太多,无性价比可言?

剩余36页未读,继续阅读
2024-04-25 上传
2024-03-05 上传
2023-12-20 上传
2023-10-08 上传
2023-05-13 上传
2023-05-27 上传
2023-06-01 上传
2023-05-14 上传
2024-05-21 上传

普通网友
- 粉丝: 12w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
