高效多线程I/O解耦与分发:领导者/跟随者模式详解
"领导者/跟随者模式(Leader/Followers Pattern)是IT行业中一种重要的设计模式,尤其在构建高性能并发服务器时显得至关重要。该模式提供了一种高效的多线程事件处理机制,能够使多个线程有效地解耦和调度共享IO处理程序,从而优化系统的并发能力和资源利用率。
设计意图:
其核心目标是解决多线程环境中如何高效地处理大量并发的I/O操作和事件。在分布式系统或高并发OLTP(在线事务处理)场景下,例如在线旅游预订服务,前端通信服务器接收到来自远程客户端(如旅行社)的交易请求后,通过领导者/跟随者架构,可以将这些请求分发到不同的后台处理层。领导者负责事件的路由和集中管理,而跟随者则作为响应和执行实际I/O操作的工作者。
在一个具体的例子中,如图所示的系统设计中,前端通信服务器充当领导者角色,它接收并分析来自远程客户端的网络请求,然后通过LAN和WAN链接将这些请求分发给后端的数据库服务器集群。这些数据库服务器是跟随者,它们负责处理实际的数据库交互,如查询、更新等操作。这种模式允许服务器群中的各个组件协同工作,避免了单点故障,并提高了系统的并发处理能力。
领导者/跟随者模式的优势在于:
1. 解耦与同步:通过领导者协调,各个跟随者之间的通信被简化,降低了同步需求,有助于提高系统的可扩展性和容错性。
2. 负载均衡:领导者可以根据负载动态调整任务分配,确保跟随者能在最佳状态下运行,避免过载。
3. 事件驱动:跟随者只处理分配给它们的任务,减少了无用的计算和等待时间。
4. 维护简单:领导者模式使得代码结构更清晰,易于理解和维护,特别是当需要对系统进行扩展或修复时。
总结来说,领导者/跟随者模式是一种强大的工具,它在处理高并发、分布式I/O场景中发挥了关键作用,对于构建可扩展、高性能的服务器系统具有显著的价值。学习和掌握这种模式对于任何致力于IT系统优化和并发编程的开发者都非常重要。"
threads demultiplex events from a larger number of handles.
Conversely, a client application may have a large number of
threads that are communicating with the same server. In this
case, however, allocating a connection-per-thread may con-
sume excessive operating system resources. Thus, it may be
necessary to multiplex events generated by many client threads
onto a smaller number of connections, e.g., by maintaining
a single connection from a client process to each server pro-
cess [11] with which it communicates.
!
For example, one possible OLTP server concurrency
model could allocate a separate thread for each client connec-
tion. However, this thread-per-connection concurrency model
may not handle hundreds or thousands of simultaneous con-
nections scalably. Therefore, our OLTP servers employ a de-
multiplexing model that uses a thread pool to align the number
of server threads to the available processing resources, such
as the number of CPUs, rather than to the number of active
connections. Likewise, to conserve system resources, multiple
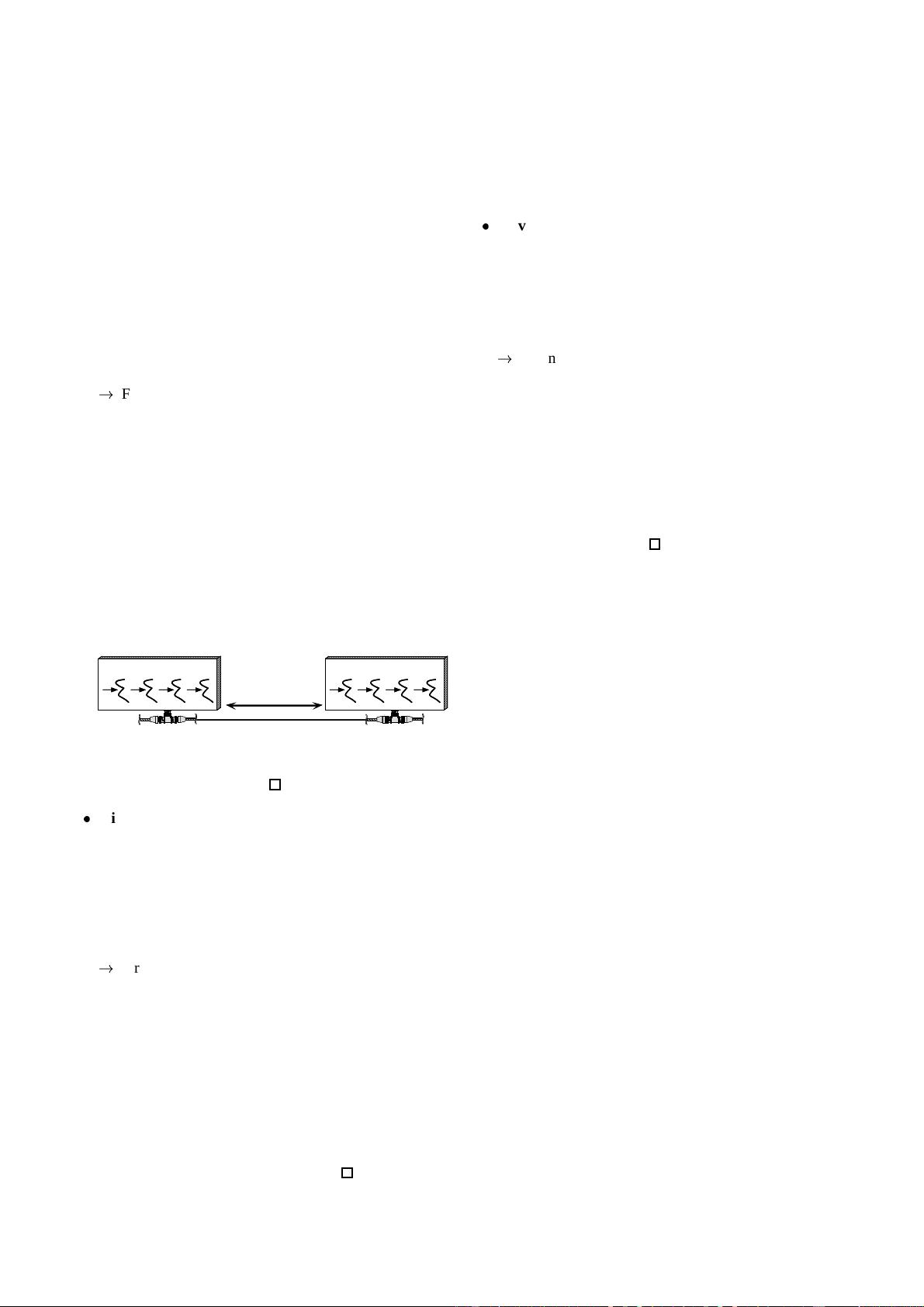
threads in each of our front-end communication servers send
requests to the same back-end server over a single multiplexed
connection, as shown in the following figure. Thus, when a
ONE TCP
CONNECTION
WORKER THREADS
FRONT-END
COMMUNICATION
SERVER
WORKER THREADS
BACK-END
DATABASE
SERVER
front-end server receives a result from a back-end server, it
must demultiplex the result to the corresponding thread that is
blocked waiting to process it.
Minimize concurrency-related overhead: To maximize
performance, key sources of concurrency-related overhead,
such as context switching, synchronization, and cache co-
herency management, must be minimized. In particular,
a concurrency model that requires memory to be allocated
dynamically for each request and passed between multiple
threads will incur significant overhead on conventional multi-
processor operating systems [12].
!
For instance, our example OLTP servers employ a thread
pool concurrencymodel based on the “half-sync/half-reactive”
variant of the Half-Sync/Half-Async pattern [2]. This model
uses a message queue to decouple the network I/O thread,
which receives client request events, from the pool of worker
threads, which process these events and return responses to
clients. Unfortunately, this design requires memory to be allo-
cated dynamically, from either the heap or a global pool, in the
network I/O thread so that incoming event requests can be in-
serted into the message queue. In addition, it requires numer-
ous synchronizations and context switches to insert/remove
the request into/from the message queue.
Prevent race conditions: Multiple threads that demulti-
plex events on a set of I/O handles must coordinate to prevent
race conditions. Race conditions can occur if multiple threads
try to access or modify certain types of I/O handles simultane-
ously. This problem often can be prevented by protecting the
handles with a synchronizer, such as a mutex, semaphore, or
condition variable.
!
For instance, a pool of threads cannot use select [3]
to demultiplex a set of socket handles because the operat-
ing system will erroneously notify more than one thread call-
ing select when I/O events are pending on the same sub-
set of handles [3]. Thus, the thread pool would need to re-
synchronize to avoid having multiple threads read from the
same handle. Moreover, for bytestream-oriented protocols,
such as TCP, having multiple threads invoking read on the
same socket handle will corrupt or lose data. Likewise, mul-
tiple simultaneous writes to a socket handle can “scramble”
the data in the bytestream.
5 Solution
Allow one thread at a time – the leader – to wait for an event
to occur on a set of I/O handles. Meanwhile, other threads
– the followers – can queue up waiting their turn to become
the leader. After the current leader thread demultiplexes an
event from the I/O handle set, it promotes a follower thread
to become the new leader and then dispatches the event to a
designated event handler, which processes the event. At this
point, the former leader and the new leader thread can execute
concurrently.
In detail: multiple former leader threads can process events
concurrently while the current leader thread waits on the han-
dle set. After its event processing completes, an idle follower
thread waits its turn to become the leader. If requests arrive
faster than the available threads can service them, the underly-
ing I/O system can queue events internally until a leader thread
becomes available. The leader thread may need to handoff an
event to a follower thread if the leader does not have the neces-
sary context to process the event. This scenario is particularly
relevant in high-volume, multi-tier distributed systems, where
results often arrive in a different order than requests were ini-
tiated. For example, if threads use the Thread-Specific Stor-
age pattern [22] to reduce lock contention, the thread that pro-
cesses a result must be the same one that invoked the request.
6 Structure
The participants in the Leader/Followers pattern include the
following:
3
剩余14页未读,继续阅读
2019-08-16 上传
2011-04-30 上传
2023-07-11 上传
2024-10-06 上传
2023-08-23 上传
2023-08-13 上传
2023-07-23 上传
2023-12-08 上传

andycai_sc
- 粉丝: 2
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
