Pandas分组与排序详解:实例演示与功能应用
98 浏览量
更新于2024-08-31
收藏 116KB PDF 举报
Pandas是Python中强大的数据分析库,其提供了丰富的数据处理功能,包括分组与排序。在本文中,我们将深入探讨如何在Pandas DataFrame上执行高效的数据分组和排序操作,以便更好地理解和分析数据。
**一、Pandas分组基础**
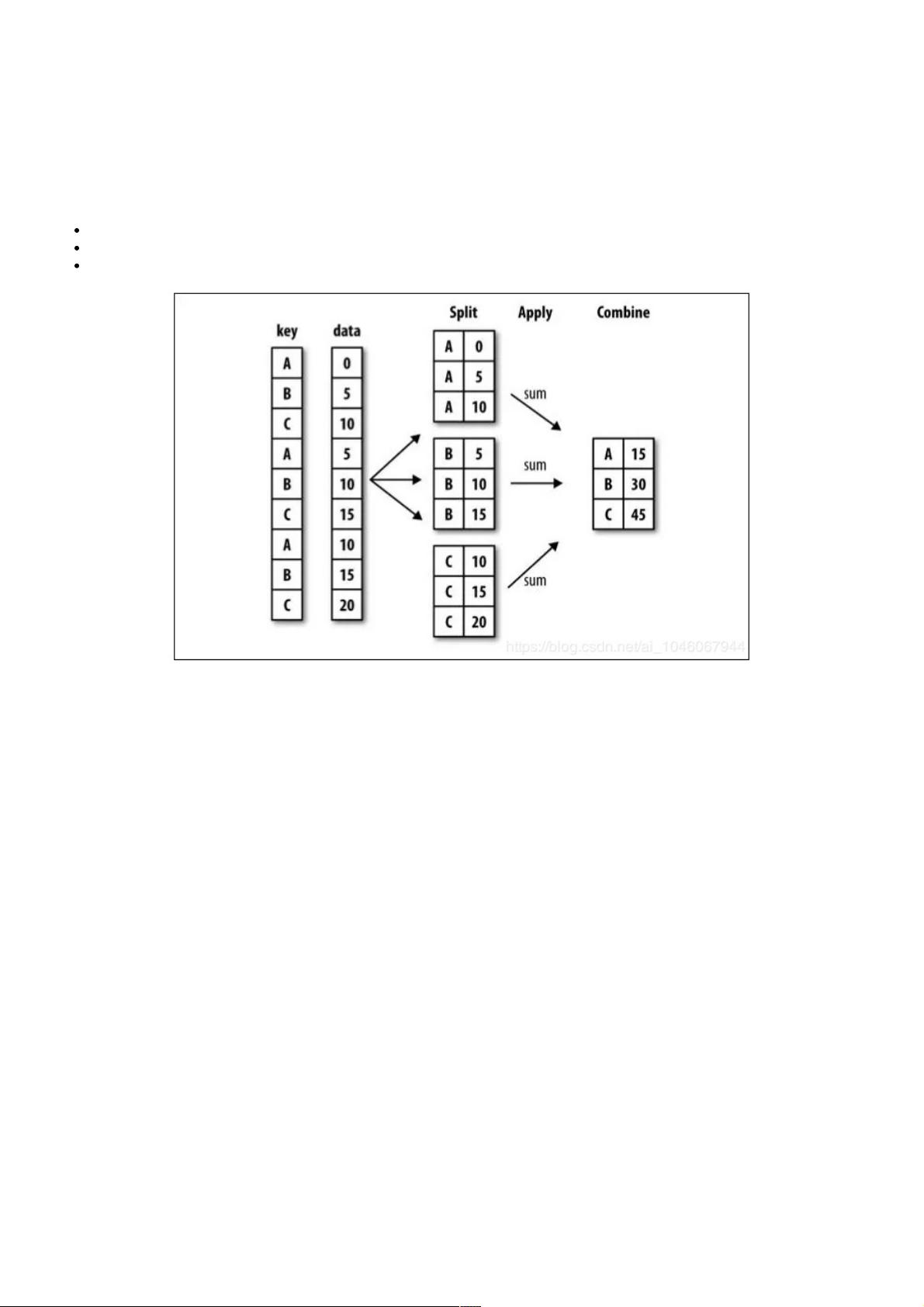
1. **分组运算过程**:
- **拆分(Split)**:通过`groupby()`方法根据指定列或多个列的值将数据集划分为多个子集,这些子集称为组。
- **应用(Apply)**:对每个组执行特定的计算规则,这可能涉及聚合函数(如求和、平均值等)、转换函数或自定义函数。
- **合并(Combine)**:将每个组的结果合并回一个统一的数据结构。
2. **分组函数参数**:
- `by`: 主要参数,可以接受多种类型,如列名、函数、标签列表或列的映射,用于确定分组依据。
- 其他参数如`axis`(默认0,表示按行分组)、`sort`(是否对分组后的结果进行排序,默认True)、`group_keys`(是否保留原分组键,默认True)等,可以根据需要调整。
**二、Pandas聚合函数**
- 聚合操作是对分组后的数据进行总结计算,例如`sum()`、`mean()`、`count()`、`min()`、`max()`等,用于汇总某一列的值。
**三、分组聚合实例**
1. **单列分组**:
- 通过`groupby()`对单列(如'A'列)进行分组,然后使用`sum()`聚合其他列(如'B', 'C', 'D'),得到每个分组的汇总值。
```python
df.groupby('A').sum() # 按'A'列分组并求和
```
2. **多列分组**:
- 当需要根据多个列(如'A'和'B')进行分组时,可以将它们作为一个列表传递给`by`参数,得到更细粒度的分组结果。
```python
df.groupby(['A', 'B']).sum() # 按'A'和'B'列联合分组并求和
```
3. **多列聚合**:
- 可以选择性地只对某些列进行聚合,例如只对'C'和'D'列求和。
```python
df.groupby(['A', 'B'])['C'].sum() # 只对'C'列求和
df.groupby(['A', 'B'])[['C', 'D']].sum() # 对'C'和'D'列同时求和
```
通过这些实例,你可以了解如何运用Pandas进行数据分组和聚合,这对于数据清洗、预处理和分析来说都是非常实用的工具。掌握这些操作不仅可以提高工作效率,还能帮助你深入理解数据的内在规律。
Pandas分组与排序的实现分组与排序的实现
主要介绍了Pandas分组与排序的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的
参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
一、一、pandas分组分组
1、分组运算过程:、分组运算过程:split->apply->combine
拆分:进行分组的根据
应用:每个分组运行的计算规则
合并:把每个分组的计算结果合并起来
2、分组函数、分组函数
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, observed=False, **kwargs
by: 依据哪些列进行分组,值可以是:mapping, function, label, or list of labels
3、聚合函数、聚合函数
下载后可阅读完整内容,剩余3页未读,立即下载
2021-01-20 上传
点击了解资源详情
点击了解资源详情
2023-06-03 上传
2023-05-03 上传
2023-05-03 上传
2023-04-11 上传
2023-05-19 上传
2023-07-10 上传

weixin_38680764
- 粉丝: 3
- 资源: 903
 我的内容管理
展开
我的内容管理
展开







最新资源
- Haskell编写的C-Minus编译器针对TM架构实现
- 水电模拟工具HydroElectric开发使用Matlab
- Vue与antd结合的后台管理系统分模块打包技术解析
- 微信小游戏开发新框架:SFramework_LayaAir
- AFO算法与GA/PSO在多式联运路径优化中的应用研究
- MapleLeaflet:Ruby中构建Leaflet.js地图的简易工具
- FontForge安装包下载指南
- 个人博客系统开发:设计、安全与管理功能解析
- SmartWiki-AmazeUI风格:自定义Markdown Wiki系统
- USB虚拟串口驱动助力刻字机高效运行
- 加拿大早期种子投资通用条款清单详解
- SSM与Layui结合的汽车租赁系统
- 探索混沌与精英引导结合的鲸鱼优化算法
- Scala教程详解:代码实例与实践操作指南
- Rails 4.0+ 资产管道集成 Handlebars.js 实例解析
- Python实现Spark计算矩阵向量的余弦相似度
