CUDA编程指南2.3.1:通用并行计算架构
需积分: 9 178 浏览量
更新于2024-08-02
收藏 1.2MB PDF 举报
"CUDA编程指南2.3版"
CUDA编程指南是NVIDIA公司推出的一份详细文档,旨在帮助开发者理解和利用CUDA(Compute Unified Device Architecture)架构进行并行计算。CUDA是一种将GPU(图形处理器)从图形处理扩展到通用计算的平台,提供了高效能计算的能力。该指南覆盖了CUDA的编程模型、接口以及编程注意事项。
在介绍部分,CUDA被定义为一个通用的并行计算架构,其目的是为了实现从图形处理到通用计算的转变。CUDA的核心是一个可扩展的编程模型,它允许开发者通过内建的并行计算单元——线程,对大规模数据集进行并行处理。
1. **编程模型**
- **内核(Kernels)**: CUDA程序中的核心计算部分,可以在GPU上执行,由大量的线程构成。
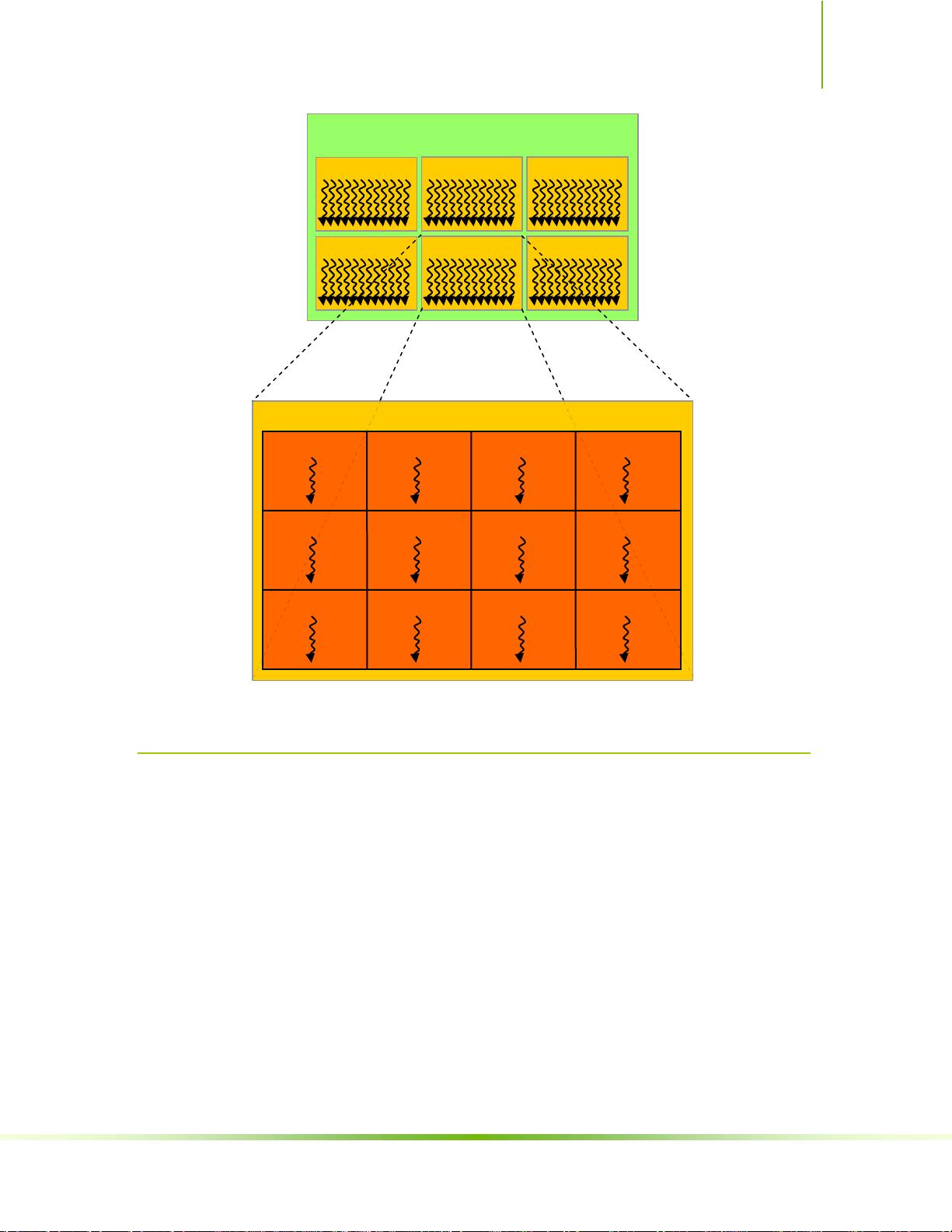
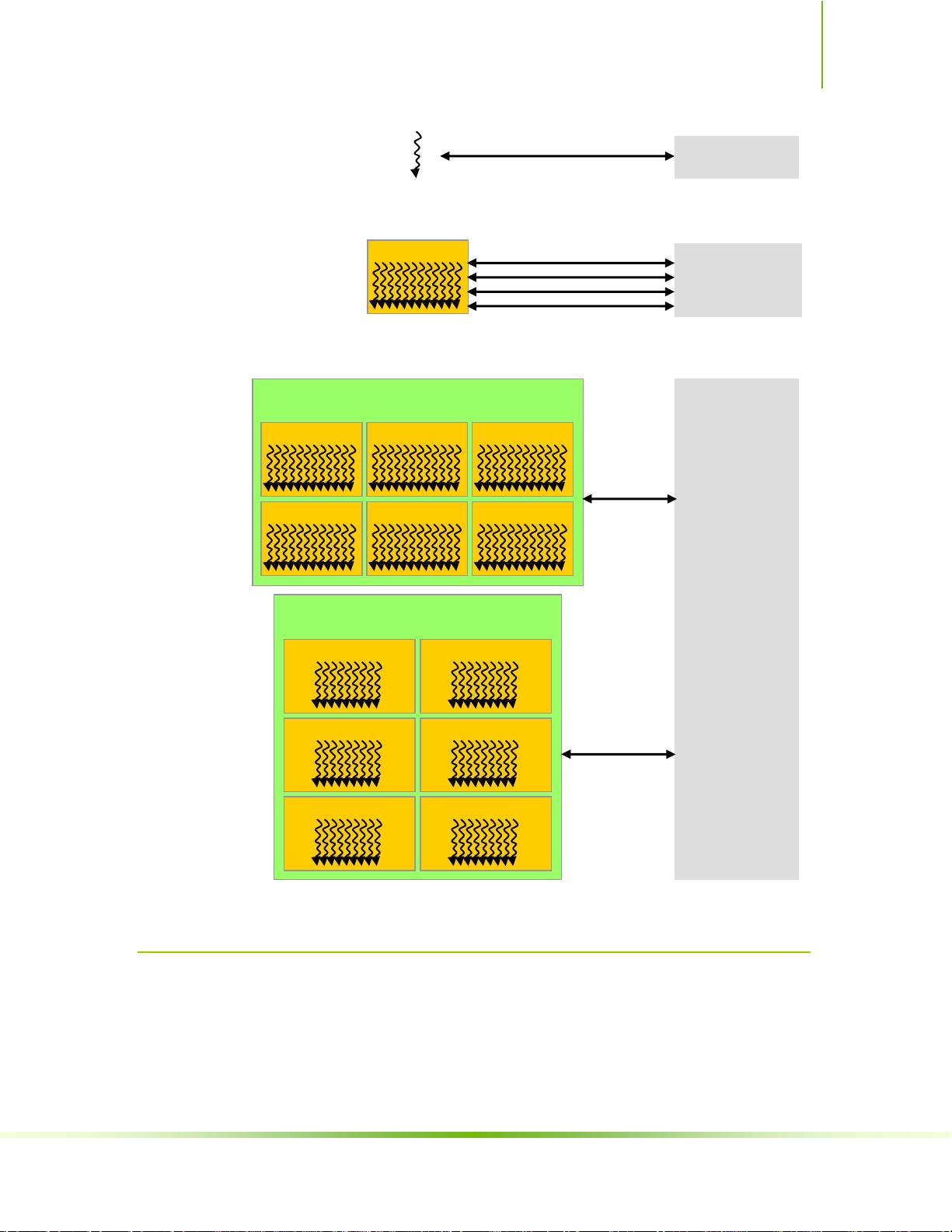
- **线程层次结构(Thread Hierarchy)**: 包括线程块(Thread Blocks)和线程网格(Grids),线程块内的线程可以协同工作,并且线程块又组成线程网格,形成多级的并行结构。
- **内存层次结构(Memory Hierarchy)**: 包括全局内存、共享内存、纹理内存、常量内存和寄存器等,根据不同的访问速度和范围满足不同需求。
- **主机与设备(Host and Device)**: 指CPU和GPU,CUDA程序可以在主机上编写,通过特定接口将计算任务传输到设备上执行。
2. **编程接口**
- **NVCC编译器(Compilation with NVCC)**: CUDA程序的编译工具,支持各种编译选项,如`__noinline__`用于禁止函数内联,`#pragma unroll`用于控制循环展开。
- **C for CUDA**: 在C语言基础上扩展的CUDA C,提供了访问GPU内存的特性,如:
- **设备内存(Device Memory)**: 全局内存用于所有线程之间的通信,是默认的内存空间。
- **共享内存(Shared Memory)**: 位于线程块级别的高速缓存,可以提升局部数据访问速度。
- **多设备(Multiple Devices)**: 支持在多个GPU上并行运行代码,提高计算能力。
- **纹理内存(Texture Memory)**: 优化连续数据读取的内存类型,适用于采样操作。
- **纹理引用声明(Texture Reference Declaration)**: 定义纹理对象来引用数据。
- **纹理属性(Runtime Texture Reference Attributes)**: 运行时设置纹理属性,如过滤模式和地址模式。
- **纹理绑定(Texture Binding)**: 将数据绑定到纹理对象,以使用纹理内存功能。
- **页锁定主机内存(Page-Locked Host Memory)**: 可以直接与GPU交互的内存,包括:
- **便携式内存(Portable Memory)**: 内存可以在多GPU之间共享。
- **写结合内存(Write-Combining Memory)**: 优化写入性能的内存类型。
- **映射内存(Mapped Memory)**: 提供了一种方式将主机内存与设备内存进行映射,便于数据交换。
- **异步并发执行(Asynchronous Concurrent Execution)**: 允许在不同的流(Streams)上并行执行任务,提高了设备利用率。
CUDA编程指南2.3版详细介绍了这些概念,旨在帮助开发者充分利用GPU的并行计算能力,提高计算效率,解决高性能计算的问题。对于想要进入CUDA编程领域的人员,这份指南是不可或缺的参考资料。

Chapter 2. Programming Model
8 CUDA Programming Guide Version 2.3.1
...
// Kernel invocation
VecAdd<<<1, N>>>(A, B, C);
}
Each of the threads that execute VecAdd() performs one pair-wise addition.
2.2 Thread Hierarchy
For convenience, threadIdx is a 3-component vector, so that threads can be
identified using a one-dimensional, two-dimensional, or three-dimensional thread
index, forming a one-dimensional, two-dimensional, or three-dimensional thread
block. This provides a natural way to invoke computation across the elements in a
domain such as a vector, matrix, or field. As an example, the following code adds
two matrices A and B of size NxN and stores the result into matrix C:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 dimBlock(N, N);
MatAdd<<<1, dimBlock>>>(A, B, C);
}
The index of a thread and its thread ID relate to each other in a straightforward
way: For a one-dimensional block, they are the same; for a two-dimensional block
of size (D
x
, D
y
), the thread ID of a thread of index (x, y) is (x + y D
x
); for a three-
dimensional block of size (D
x
, D
y
, D
z
), the thread ID of a thread of index (x, y, z) is
(x + y D
x
+ z D
x
D
y
).
Threads within a block can cooperate among themselves by sharing data through
some shared memory and synchronizing their execution to coordinate memory
accesses. More precisely, one can specify synchronization points in the kernel by
calling the
__syncthreads() intrinsic function; __syncthreads() acts as a
barrier at which all threads in the block must wait before any is allowed to proceed.
Section 3.2.2 gives an example of using shared memory.
For effi
cient cooperation, the shared memory is expected to be a low-latency
memory near each processor core, much like an L1 cache,
__syncthreads() is
expected to be lightweight, and all threads of a block are expected to reside on the
same processor core. The number of threads per block is therefore restricted by the
limited memory resources of a processor core. On current GPUs, a thread block
may contain up to 512 threads.
However, a kernel can be executed by multiple equally-shaped thread blocks, so that
the total number of threads is equal to the number of threads per block times the


剩余144页未读,继续阅读
2010-02-26 上传
2010-06-06 上传
2013-03-02 上传
2017-01-04 上传
2021-12-17 上传
2022-09-02 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

zhushulei
- 粉丝: 2
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
