
ApacheBeam:下一代的数据处理标准:下一代的数据处理标准
Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的孵化项目,被认为是继
MapReduce、GFS和BigQuery等之后,Google在大数据处理领域对开源社区的又一贡献。Apache Beam的主要目标是统一
批处理和流处理的编程范式,为无限、乱序,Web-Scale的数据集处理提供简单灵活、功能丰富以及表达能力十分强大的
SDK。Apache Beam项目重点在于数据处理的编程范式和接口定义,并不涉及具体执行引擎的实现。本文主要介绍Apache
Beam的编程范式——Beam Model,以及通过Beam SDK如何方便灵活地编写分布式数据处理业务逻辑,希望读者能够通过
本文对Apache Beam有初步了解,同时对于分布式数据处理系统如何处理乱序无限数据流的能力有初步认识。
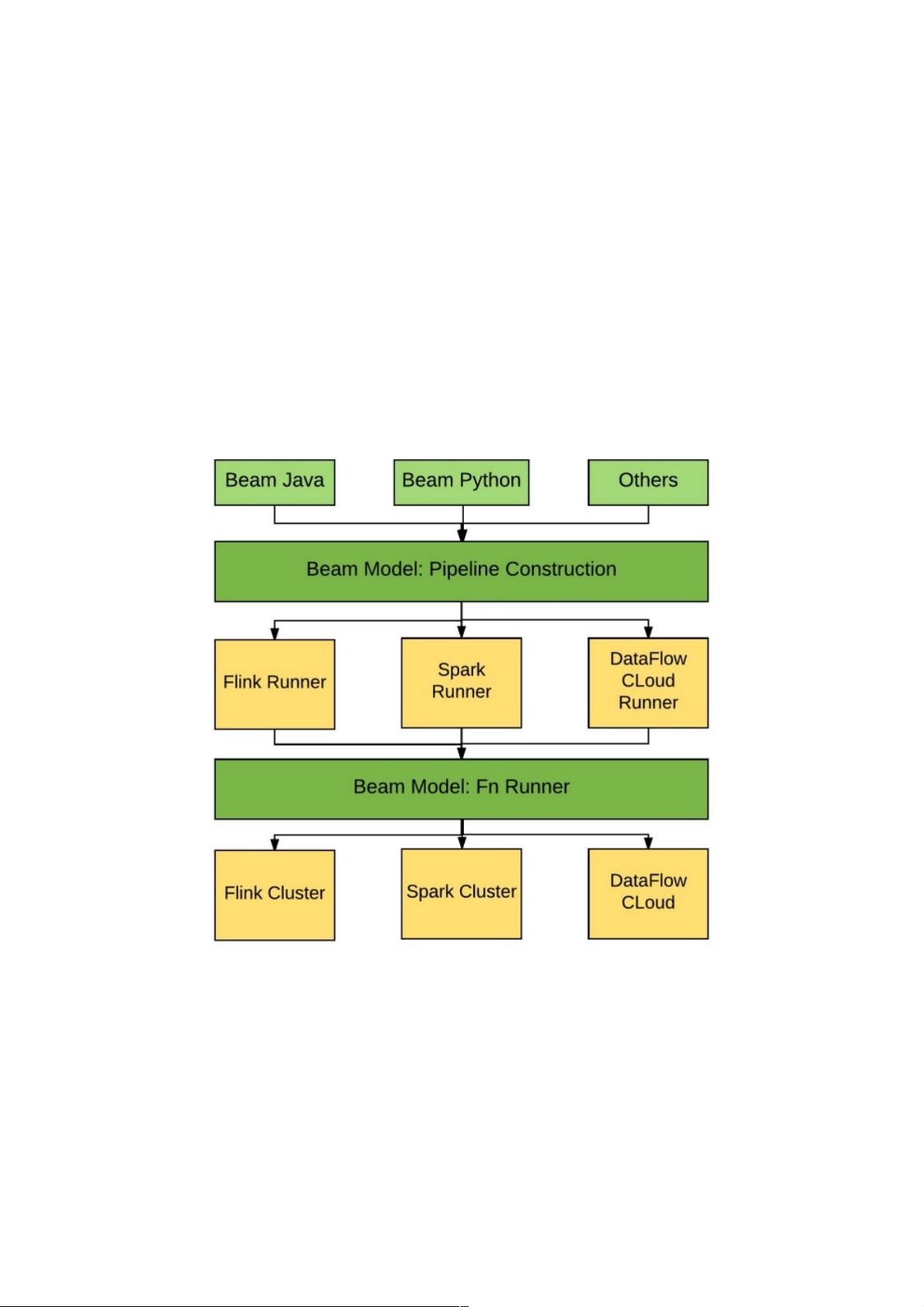
Apache Beam基本架构
随着分布式数据处理不断发展,业界涌现出越来越多的分布式数据处理框架,从最早的Hadoop MapReduce,到Apache
Spark、Apache Storm、以及更近的Apache Flink、Apache Apex等。新的分布式处理框架可能带来更高性能,更强大功能,
更低延迟等,但用户切换到新分布式处理框架的代价也非常大:需要学习一个新的数据处理框架,并重写所有业务逻辑。解决
这个问题的思路包括两部分,首先,需要一个编程范式,能够统一规范分布式数据处理的需求,例如统一批处理和流处理的需
求。其次,生成的分布式数据处理任务应该能够在各个分布式引擎上执行,用户可以自由切换执行引擎与执行环境。Apache
Beam正是为了解决以上问题而提出的。它主要由Beam SDK和Beam Runner组成,Beam SDK定义了开发分布式数据处理任
务业务逻辑的API接口,生成的的分布式数据处理任务Pipeline交给具体的Beam Runner执行引擎。Apache Beam目前支持的
API接口由Java语言实现,Python版本的API正在开发之中。它支持的底层执行引擎包括Apache Flink、Apache Spark以及
Google Cloud Platform,此外Apache Storm、Apache Hadoop、Apache Gearpump等执行引擎的支持也在讨论或开发中。其
基本架构如图1。
需要注意的是,虽然Apache Beam社区非常希望所有的Beam执行引擎都能够支持Beam SDK定义的功能全集,但在实际实现
中可能并不一定。例如,基于MapReduce的Runner显然很难实现和流处理相关的功能特性。目前Google DataFlow Cloud是
对Beam SDK功能集支持最全面的执行引擎,在开源执行引擎中,支持最全面的则是Apache Flink。
Beam Model
Beam Model指Beam的编程范式,即Beam SDK背后的设计思想。在介绍Beam Model前,先介绍下Beam Model要处理的问
题域与基本概念。
数据。要处理的数据一般可以分为两类,有限的数据集和无限的数据流。对于前者,比如一个HDFS中的文件,一个HBase表
等,特点是数据提前已经存在,一般也已经持久化,不会突然消失。而无限的数据流,比如Kafka中流过来的系统日志流,或
是从Twitter API拿到的Twitter流等,这类数据的特点是动态流入,无穷无尽,无法全部持久化。一般来说,批处理框架的设计
目标是用来处理有限的数据集,流处理框架的设计目标是用来处理无限的数据流。有限的数据集可以看做无限数据流的一种特
例,但是从数据处理逻辑角度,这两者并无不同之处。例如,假设微博数据包含时间戳和转发量,用户希望按照每小时的转发
量统计总和,此业务逻辑应该可以同时在有限数据集和无限数据流上执行,并不应该因为数据源的不同而对业务逻辑的实现产
生任何影响。
下载后可阅读完整内容,剩余3页未读,立即下载

weixin_38690830
- 粉丝: 4
- 资源: 996
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


