词法分析与正则表达式到NFA转换
版权申诉
152 浏览量
更新于2024-07-03
收藏 1.23MB PPT 举报
"该资源是关于编译程序原理与实现的第二章,主要讲解了从正则表达式(RE)到非确定有限自动机(NFA)的转换过程。"
在计算机科学中,编译器是将高级编程语言转换为机器可执行代码的关键组件。编译程序的构造涉及多个阶段,其中之一是词法分析,它负责识别源代码中的词汇单元,如关键字、标识符和符号。本章深入探讨了词法分析的相关概念,以及如何利用正则表达式和有限自动机来实现这一过程。
一、词法分析概述
词法分析程序的主要任务是从源代码中识别出一个个的词法单元,即“ token ”。这些 token 是语法分析的基础。词法分析还涉及到处理诸如空白、注释等无关字符,以及处理边界情况,如数字和字符串的识别。
二、正则表达式
正则表达式是一种简洁的表示字符集合的方式,可以用来描述一系列的字符序列。它们在描述程序设计语言的单词结构时非常有用,因为它们可以轻松地表示复杂的模式,例如数字、字母和符号的组合。
三、有限自动机
1. 确定有限自动机(DFA):DFA 是一种有穷状态的机器,每个状态有一个确定的转移,用于接受特定的输入序列。
2. 非确定有限自动机(NFA):NFA 可以在给定状态下对多种输入有多个可能的转移,这使得 NFA 在某些情况下能更简洁地表示正则表达式。
3. NFA 到 DFA 的转换:虽然 NFA 更易于表达,但通常更倾向于使用 DFA,因为它们更容易实现。通过一种称为 powerset construction 的方法,可以将 NFA 转换为等价的 DFA。
4. DFA 的化简:DFA 化简是为了减少状态数量,使其更高效。常用的方法包括状态合并和死状态识别。
四、正则表达式到NFA的转换
这个过程,也称为 Thompson 构造法,按照以下规则将正则表达式转换为 NFA:
- 空字符 ε 代表一个空的输入序列。
- 字符 c 代表一个匹配字符 c 的状态。
- 括号 (A) 保留 A 的含义。
- 连接 A 和 B (AB) 表示先匹配 A 后匹配 B。
- 选择 A 和 B (A|B) 表示匹配 A 或 B。
- 闭包 A* (A*) 表示零个或多个 A 的连续序列。
通过这些规则,我们可以构建出对应于给定正则表达式的 NFA。例如,正则表达式 (a|b)*abb(a|b)、a((a|b)*ab*a)b 和 (0|1)*00 都可以分别转换为相应的 NFA 图形表示。
词法分析程序构造通常遵循以下步骤:
1. 使用正则表达式定义单词结构。
2. 将正则表达式转换为 NFA。
3. 将 NFA 转换为 DFA,以简化实现。
4. 对 DFA 进行化简,提高效率。
5. 最后,实现词法分析程序,它可以扫描源代码并生成对应的 token 序列。
通过这些方法,编译器能够理解和解析输入的源代码,为后续的语法分析和代码生成做好准备。理解正则表达式到 NFA 的转换对于开发编译器和解析器至关重要,也是计算机科学教育中的核心内容。
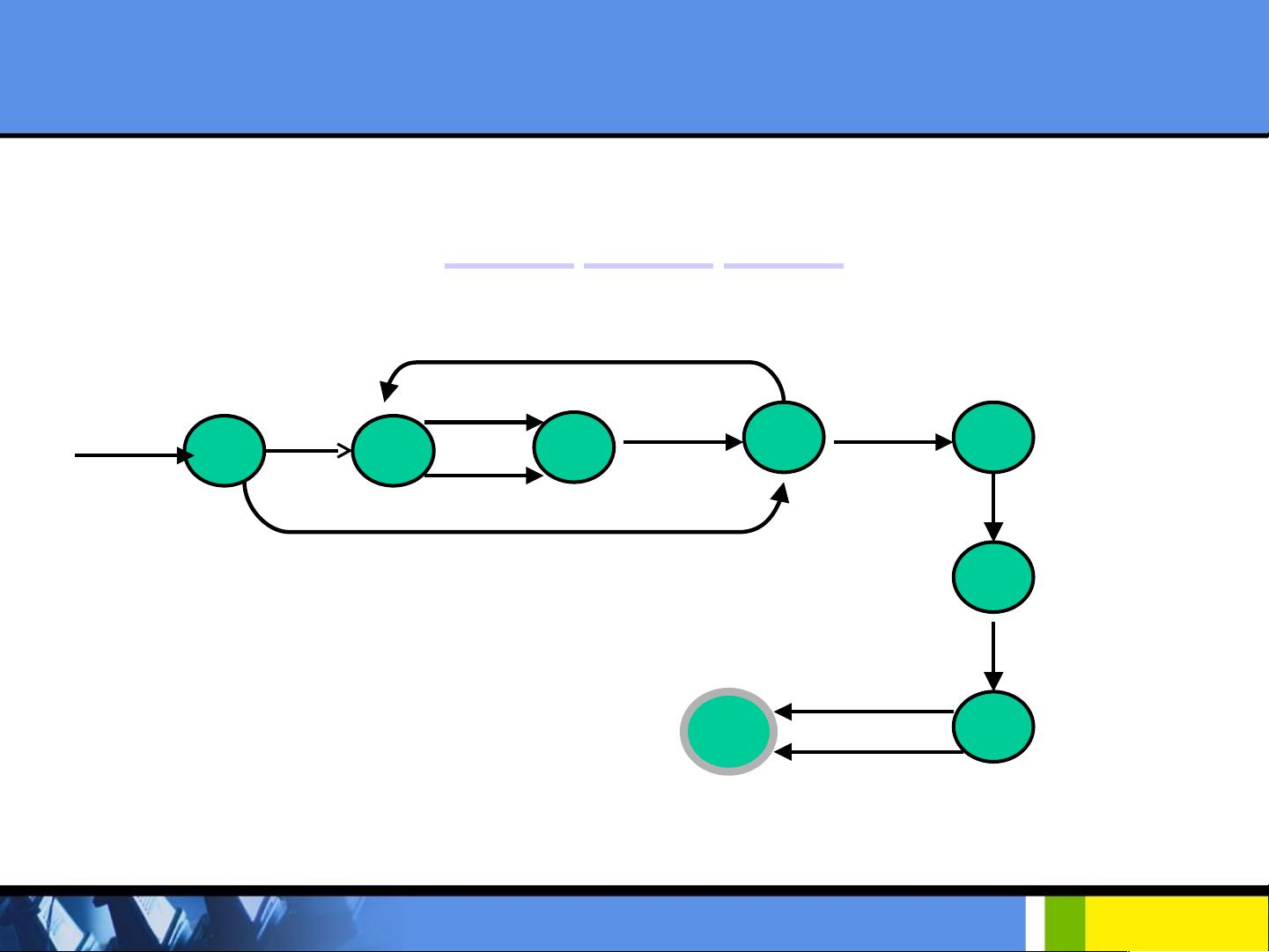
RE 到 NFA 的转换
•
例 1 :将正则表达式 (a | b)* a b b (a | b) 转化成等价的 NFA.
a
b
b
b
a
a
b
剩余41页未读,继续阅读
2022-06-15 上传
2019-07-05 上传
2009-11-15 上传
2023-05-30 上传
2023-06-11 上传
2023-06-11 上传
2024-11-06 上传
2023-05-18 上传
2024-11-17 上传

智慧安全方案
- 粉丝: 3837
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







