宝马与Ruetz系统解决方案公司联合测试过程
需积分: 12 98 浏览量
更新于2024-07-15
收藏 1.22MB PDF 举报
"2_Test_Process_ECU and network test.pdf - 它是关于ECU(电子控制单元)和网络测试的测试过程文档,由Thomas Kirchmeier(宝马公司)和Georg Janker(Ruetz System Solutions GmbH)共同编写。文档版本为1.0,最终定稿日期为2016年9月22日,公开于OPEN Alliance。"
在TC8-ECU和网络测试中,该文档详细阐述了汽车行业中电子控制单元和网络系统的测试流程。测试过程是确保汽车电子系统质量和可靠性的关键环节,它涵盖了从测试准备到执行,再到结果分析和反馈的整个周期。
首先,文档可能详细介绍了测试环境的建立,包括ECU的安装、配置以及网络的布线和调试。ECU测试可能涉及功能验证、性能评估、故障模拟等多种场景,以确保ECU能够正确地接收和处理来自传感器和控制器的信号,并按照预定逻辑进行响应。
网络测试则关注通信协议的合规性、数据传输的效率和稳定性。这可能包括CAN、LIN、FlexRay或以太网等不同车载网络的测试,检查它们在多ECU环境下的协同工作能力,防止数据冲突和通信错误。
在测试过程中,文档可能提到了使用的问题问卷,这是为了收集DUT(设备-under-test,即被测设备)的相关信息,如硬件配置、软件版本、预期行为等,以便更准确地制定测试计划和测试用例。
版本控制部分显示了文档的迭代历史,从0.1版的初稿合并到0.3版的反馈审查,每次更新都对测试流程进行了细化和完善。特别地,0.2版更新了ECU测试和网络测试的描述,而0.3版则根据评审反馈进行了修订,并解决了链接问题,明确了新内容将融入到官方的测试规范文档中。
最后,文档强调了所有技术成员对测试规范的正式审查和发布,以确保测试标准的严谨性和行业共识。这种协作和标准化的流程对于保持汽车行业的高质量标准至关重要。
这份文档为汽车制造商和测试机构提供了ECU与网络系统测试的全面指南,有助于提高测试效率,减少潜在问题,保障汽车电子系统的安全和可靠性。
OPEN Alliance
Restriction Level:
Public TC8 Test Process | Sep-16 4
1 Motivation
This document describes all necessary requirements for implementation of a test process which
specifies and performs OPEN Alliance test cases for ECUs (OPEN Alliance Automotive Ethernet ECU Test
Specification). These requirements shall be fulfilled by all parties in order to enable not only with high
quality test definition but also reliable test results to ensure a stable communication in Automotive
Ethernet networks.
The ECU Test Specification pursues the objective to confirm that the ECU will fulfill all requirements of
an Automotive Ethernet device. This specification is defined and will be maintained by TC8 of the OPEN
Alliance. Based on the test specification a test house implements and verifies these tests in order to
offer a test service for any TIER1. The TIER1 is mandated by an OEM to develop a number of ECUs.
Usually, the OEM mandates different TIER1 with the development of all ECUs needed for a particular
automobile. The TIER1 mandates a Test House to perform the Automotive Ethernet ECU tests. The
Ethernet ECU test report from the Test House is forwarded to the OEM by / via TIER1. The OEM
performs the network integration for all ECUs based on the test reports of all TIER1. If all Ethernet ECU
test reports are bugless, there will be a reliable communication within the network.
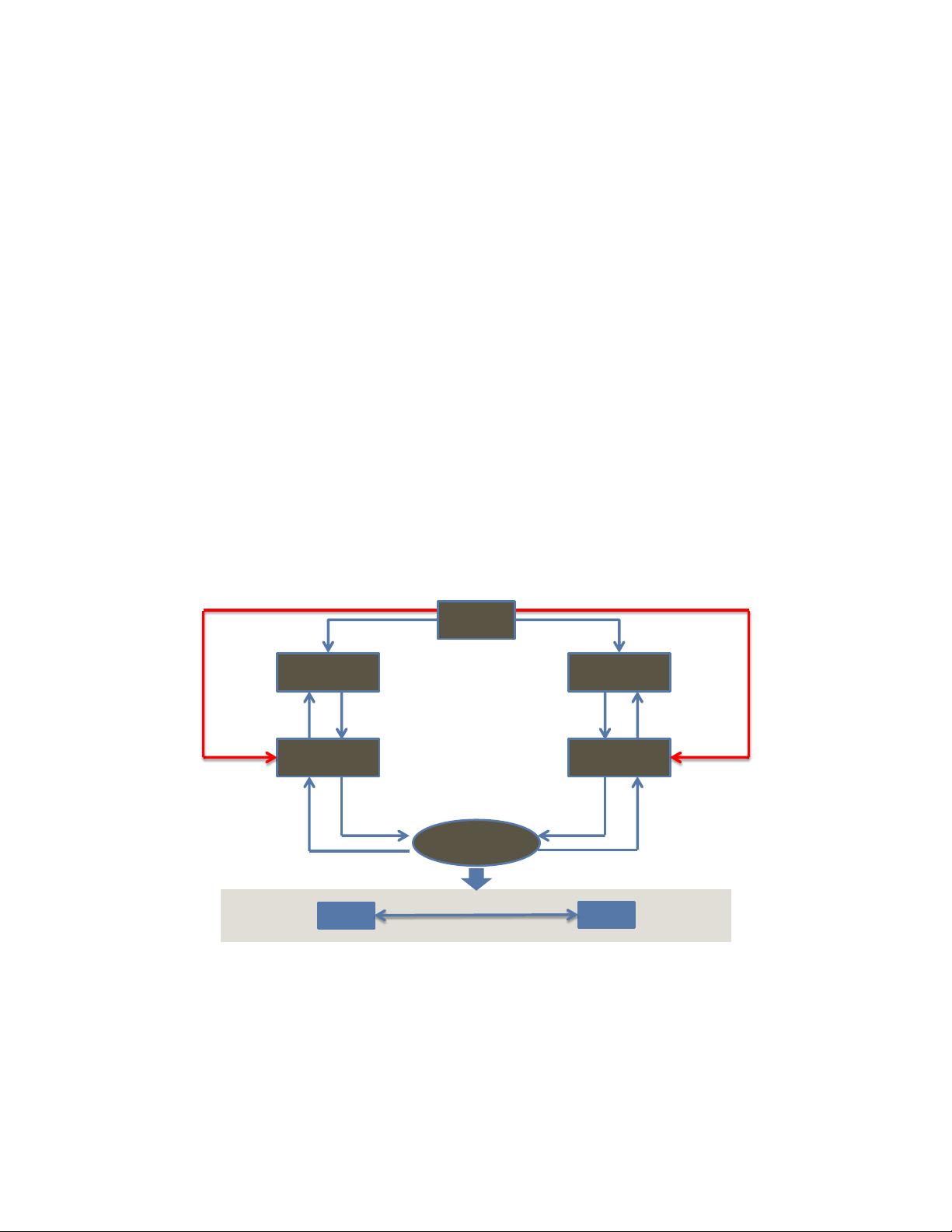
Figure 1 illustrates the described situation.
Figure 1: The Goal of the TC8 ECU test specification is the confirmation of a reliable communication of different ECUs in the
same network.
Network
integration
OPEN
Alliance
Test house A Test house B
OEM
ECU1
ECU2
reliable communication in
network
goal
ECU test spec. ECU test spec.
Ethernet ECU
test report
Contract, if
req. list fulfill
Ethernet ECU
test report
Contract, if
req. list fulfill
Tier1 Y Tier1 X
ECU test
report
ECU test
report
Contract
ECU2 Spec.
Contract
ECU1 Spec.
Test house
requirements list
Test house
requirements list
剩余19页未读,继续阅读
2020-04-29 上传
2021-12-02 上传
2023-05-23 上传
2023-06-07 上传
2023-06-10 上传
2023-05-29 上传

csdnverruckt
- 粉丝: 0
- 资源: 22
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
