Flume日志采集系统详解:构建Hadoop大数据源解决方案
版权申诉
157 浏览量
更新于2024-07-07
收藏 2.39MB PPTX 举报
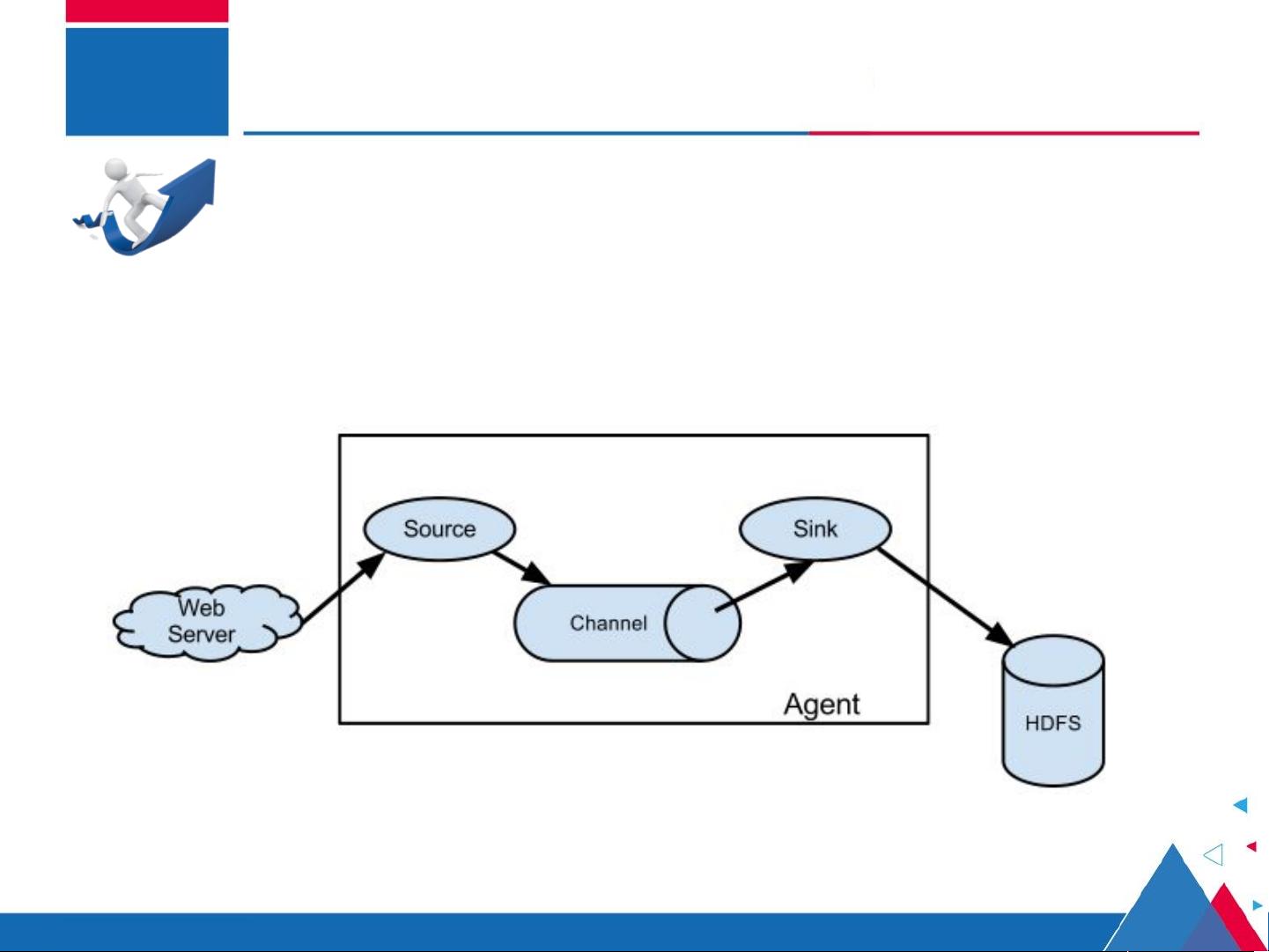
在大数据课程——Hadoop集群程序设计与开发中,第8章专门探讨了Apache Flume日志采集系统。Flume是一个强大的数据收集工具,尤其适合处理多样化的数据源,如网站日志、监控数据和用户行为数据,其目标是解决数据收集中的复杂性问题,确保数据能够高效、准确地流入HDFS系统。本章首先概述了Flume的基本概念,包括其运行机制:数据通过数据采集器(Source)、缓冲通道(Channel)和接收器(Sink)进行流动,以event(事件)的形式传输,每个event包含headers和body,分别存储标识信息和具体数据。
Flume的核心在于其可靠性保证,通过Source收集数据,然后在Channel中进行临时存储,直到Sink接收到所有数据后才进行持久化操作,确保数据完整性和一致性。源数据可以是单个或多个,Flume支持不同的数据源,如HTTP/HTTPS、Socket、Kafka等,可以根据实际场景灵活配置。Channel选项有多种,如Memory Channel、 JDBC Channel和File Channel等,提供了不同的数据处理策略。
在课程中,会深入讲解Flume的拦截器机制,这是一种扩展功能,允许在数据流经Flume时对其进行预处理或后处理,例如过滤、转换或加密。通过案例研究,学生将学习如何设计和配置Flume来实现日志采集,从简单的单通道串联结构到更复杂的多通道和多代理配置,以便满足不同的数据处理需求。
此外,学习者还将掌握如何将Flume集成到Hadoop生态系统中,利用其作为数据管道,将实时数据导入HDFS或进一步传递给其他处理环节,如MapReduce作业或实时分析工具。通过本章的学习,学生不仅能掌握Flume的使用,还能理解其在大数据项目中的重要作用,并提升数据集成和管理能力。
本章的教学大纲可能包括理论介绍、实战操作、代码示例和案例分析等环节,旨在使学员全面掌握Flume的日志采集系统设计和配置,为他们在大数据项目中实现高效的数据收集奠定坚实基础。通过教师版课程资料包,学员可以获得详细的教案、教学设计、实训文档以及配套的演示视频,确保学习效果。

✎
8.1 Flume 概述
Flume 日志采集系统结构图
在实际开发中, Flume 需要采集数据的
类型多种多样,同时还会进行不同的中间操
作,所以根据具体需求,可以将 Flume 日志
采集系统分为简单结构和复杂结构。
剩余53页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-01-01 上传
2022-01-01 上传
2022-01-01 上传
2022-01-01 上传
2022-01-01 上传
2022-01-01 上传

睡不醒.
- 粉丝: 1308
- 资源: 62
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
