Spark Mllib决策树二元分类:模型评估与AUC深度解析
需积分: 3 150 浏览量
更新于2024-08-29
收藏 185KB PDF 举报
在Spark Mllib中的决策树二元分类中,模型评估是一个关键环节,特别是在网站分类这类应用场景中。相比于简单的准确性百分比,AUC(Area Under the Curve of ROC,ROC曲线下的面积)提供了更为精细的评估指标。AUC考虑了真正例率(TPR)和假正例率(FPR)之间的平衡,这两个概念是构建ROC曲线的基础:
- **真正例率 (TPR)**: 表示模型正确预测为正类(1)的样本比例,即 TP / (TP + FN)。它衡量的是模型识别出实际为正类的样本的能力。
- **假正例率 (FPR)**: 表示模型错误预测为正类(1)的样本比例,即 FP / (FP + TN)。它反映了模型将负类误判为正类的倾向。
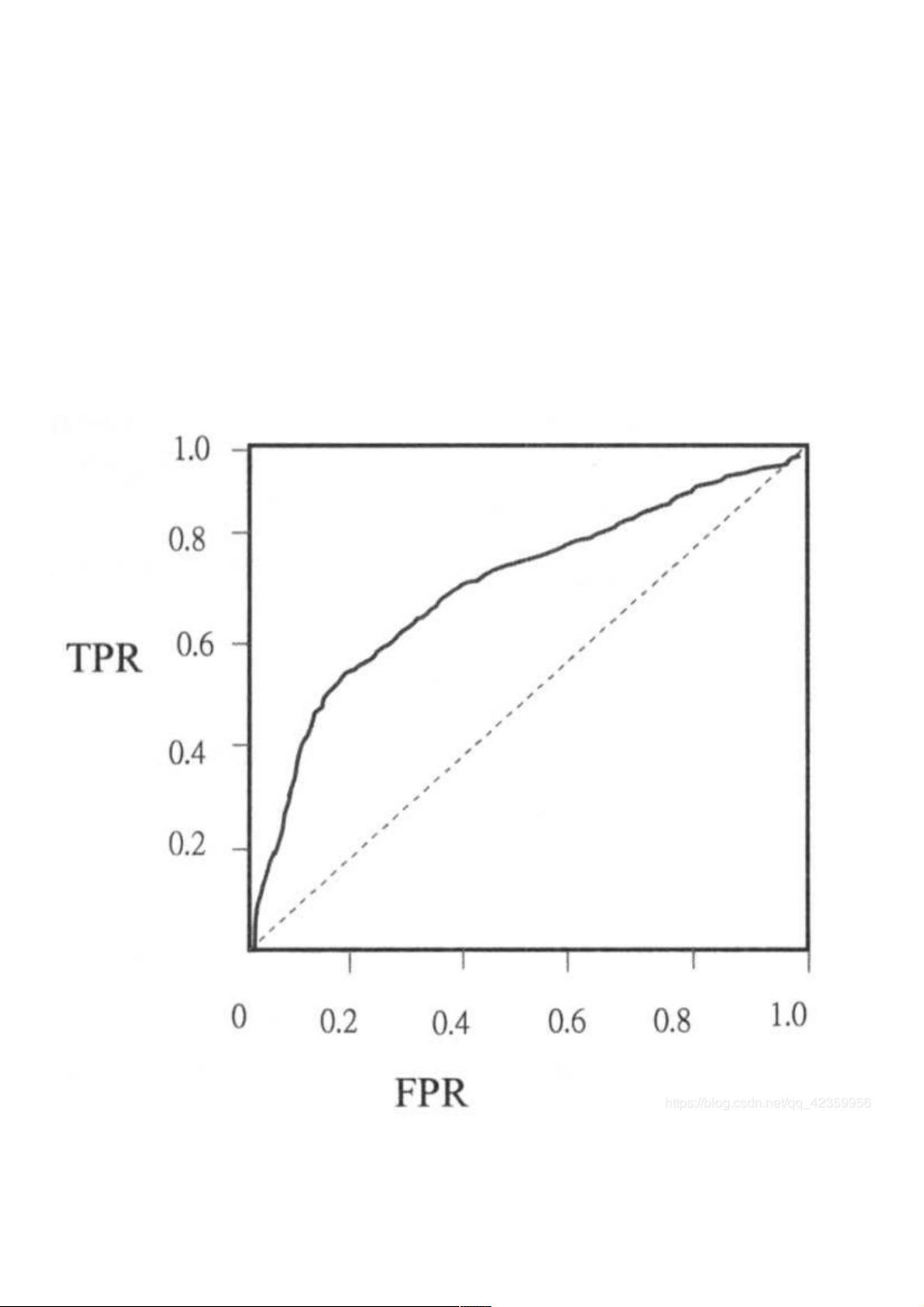
通过计算TNR(True Negative Rate,真阴性率,即 TN / (FP + TN)),ROC曲线可以描绘出不同阈值下FPR与TPR的变化情况。ROC曲线的位置越高,面积越大,说明模型性能越好。在本案例中,通过调用`BinaryClassificationMetrics`评估工具,计算得到的AUC值为0.6199946682707425,这表明模型具有一定的区分能力,但仍有改进的空间。
训练模型时,我们使用了`DecisionTree.trainClassifier`方法,设置了参数如numClasses(这里为2,表示二元分类)、categoricalFeaturesInfo、impurity(例如设置为“entropy”信息增益)、maxDepth(树的最大深度)和maxBins(用于离散化特征的桶数)。将预测结果和真实值合并后,我们对模型进行了评估,并展示了部分预测结果示例。
总结来说,Spark Mllib的决策树二元分类模型评估过程包括理解TPR和FPR的概念、绘制并分析ROC曲线以及计算AUC值。通过这些指标,我们可以更全面地了解模型在网站分类任务中的表现,并据此进行优化或调整。
Spark Mllib 下的决策树二元分类下的决策树二元分类 —— 网站分类网站分类(2)
模型评估模型评估
在上一章节的末尾我们提到过模型的评估,那时只是简单的求了一下百分比,那种方式只能粗略的反映模型的准确率,针对二元分类算
法,我们有AUC(Area under the Curve of ROC)即ROC曲线下的面积来评估模型的好坏在计算AUC之前应该先理解下面的几个概念:
/ 真真 假假
阳 TP FP
阴 TN FN
真阳性 True Positives ( TP ): 预测为 1 ,实际为 1.
假阳性 False Positives ( FP ): 预测为 1 ,实际为 0.
真阴性 True Negatives ( TN ): 预测为 0 ,实际为 0.
假阴性 True Negatives ( FN ): 预测为 0 ,实际为 1.
TPR:在所有实际为 1 的样本中被正确判断为 1 的比例.
TPR = TP/( TP + FN )
FPR: 在所有实际为 0 的样本中被错误判断为 1 的比例.
FPR = FP/( FP + TN)
有了 TPR 和 FPR就可以绘制ROC曲线了,如下图所示:
ROC曲线与XY轴正方向围成的面积即为AUC的值
1、训练模型、训练模型
model = DecisionTree.trainClassifier(train_data,numClasses=2,categoricalFeaturesInfo={},impurity="entropy",maxDepth=5,maxBins=5)
2、将预测结果和真实值压缩在一起、将预测结果和真实值压缩在一起
score = model.predict(validation_data.map(lambda p:p.features))
score_and_labels = score.zip(validation_data.map(lambda p:p.label))
score_and_labels.take(5)
下载后可阅读完整内容,剩余4页未读,立即下载
570 浏览量
294 浏览量
1434 浏览量
174 浏览量
467 浏览量
点击了解资源详情
144 浏览量
151 浏览量

weixin_38657376
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- ITween插件实用教程:路径运动与应用案例
- React三纤维动态渐变背景应用程序开发指南
- 使用Office组件实现WinForm下Word文档合并功能
- RS232串口驱动:Z-TEK转接头兼容性验证
- 昆仑通态MCGS西门子CP443-1以太网驱动详解
- 同步流密码实验研究报告与实现分析
- Android高级应用开发教程与实践案例解析
- 深入解读ISO-26262汽车电子功能安全国标版
- Udemy Rails课程实践:开发财务跟踪器应用
- BIG-IP LTM配置详解及虚拟服务器管理手册
- BB FlashBack Pro 2.7.6软件深度体验分享
- Java版Google Map Api调用样例程序演示
- 探索设计工具与材料弹性特性:模量与泊松比
- JAGS-PHP:一款PHP实现的Gemini协议服务器
- 自定义线性布局WidgetDemo简易教程
- 奥迪A5双门轿跑SolidWorks模型下载
