
THREAD
PE
PROCESSING
ELEMENT
LIGHTWEIGHT
PROCESS
LWP
UNIX
PROCESS
PE
PE PE
PEPE PE PE PE
SHARED MEMORY
KERNEL
-
LEVEL
USER
-
LEVEL
LWP LWP LWPLWP LWP LWP LWP
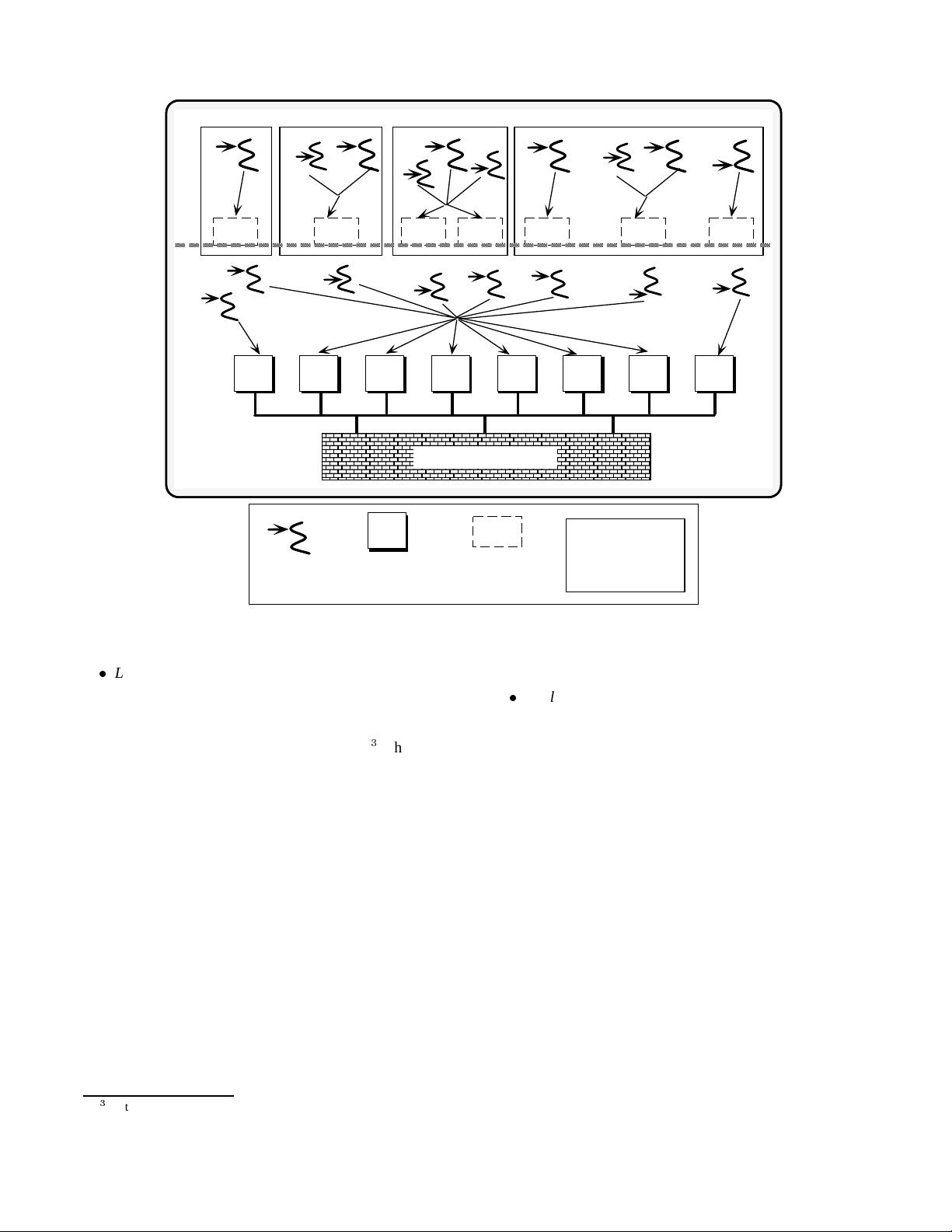
Figure 2: Solaris 2.x Multi-processing and Multi-threading Architecture
Lightweight processes (LWPs) – which are associated
with kernel threads. In Solaris 2.x, a UNIX process is
no longer a thread of control. Instead, each process con-
tains one or more LWPs. There is a 1-to-1 mapping
between its LWPs and its kernel threads.
3
The kernel-
level scheduler in Solaris uses LWPs (and thereby ker-
nel threads) to scheduleapplication tasks. An LWP con-
tains a relatively large amount of state (such as regis-
ter data, accounting and profiling information, virtual
memory address ranges, and timers). Therefore, con-
text switching between LWPs is relatively slow.
For the time-sharing scheduler class (the default), the
scheduler divides the available PE(s) among multiple
active LWPs via preemption. With this technique, each
LWP runs for a finite period of time (typically 10 mil-
liseconds). After the time-slice of the current LWP
has elapsed, the OS scheduler selects another available
LWP, performs a context switch, and places the pre-
empted LWP onto a queue. The kernel schedules LWPs
using several criteria (such as priority, availability of
resources, scheduling class, etc.). There is no fixed or-
der of executionfor LWPs in the time-sharing scheduler
3
On the other hand, not every kernel thread has an LWP. For example,
there are system threads (like the pagedaemon, NFS daemon, and the callout
thread) that have a kernel thread and operate entirely in kernel space.
class.
Applicationthreads – Each LWP may be thought of as a
“virtual PE,” upon which application threads are sched-
uled and multiplexed by a user-level thread library.
Each application thread shares its process address space
with other threads, though it has a unique stack and reg-
ister set. An application thread may spawn other appli-
cation threads. Within a process, each of these applica-
tion threads execute independently (though not neces-
sarily in parallel depending on the hardware).
Solaris 2.x provides a multi-level concurrency model
that permits application threads to be spawned and
scheduled using one of the following two modes:
1. Bound threads – which map 1-to-1 ontoLWPs and
kernel threads. Bound threads permit independent
tasks to execute in parallel on multiple PEs. Thus,
if two application threads are running on sepa-
rate LWPs (and thus separate kernel threads), they
may execute in parallel (assuming they are run-
ning on a multiprocessor or using asynchronous
I/O). Moreover, application threads may perform
blocking system calls and handle page faults with-
out impeding each other’s progress.
A kernel-level context switch is required to
reschedule bound threads. Likewise, synchroniza-
6

剩余30页未读,继续阅读

hfeekiaaa
- 粉丝: 3
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


