Hadoop3.X大数据平台中的Hive:数据仓库与分析
需积分: 11 180 浏览量
更新于2024-07-09
收藏 1.35MB PDF 举报
"本章详细介绍了Hadoop大数据平台上的数据仓库工具Hive,包括其基本概念、安装配置、Beeline的使用、DDL和DML操作、数据查询、内置函数、高级应用以及程序设计。Hive是由Facebook开源的一个项目,它将结构化的数据文件映射为表,借助HDFS存储数据,并利用MapReduce进行数据处理。Hive提供了类似SQL的查询语言HiveQL,使得非MapReduce开发人员也能进行数据分析。Hive的特点包括良好的可扩展性和容错性,支持用户自定义函数,但不适合低延迟和实时查询的应用场景。在Hadoop生态系统中,Hive与其他组件如HDFS和MapReduce紧密协作。"
在大数据处理领域,Hive是一个关键的组件,尤其适用于大规模批处理作业,例如网络日志分析。Hive的出现使得那些对SQL有经验的用户无需深入理解MapReduce就能对大数据进行操作。Hive的基础包括它的架构,它是Facebook为了简化大规模数据集的查询而创建的。Hive并不存储数据,而是将数据存储在Hadoop的分布式文件系统HDFS上,通过MapReduce执行计算任务。
在Hive的安装与配置环节,用户需要设置Hadoop环境并配置Hive的相关参数,以便于Hive能正确地与HDFS和MapReduce交互。Beeline是Hive的一个命令行客户端,提供了一种更高效的方式来执行HiveQL语句。
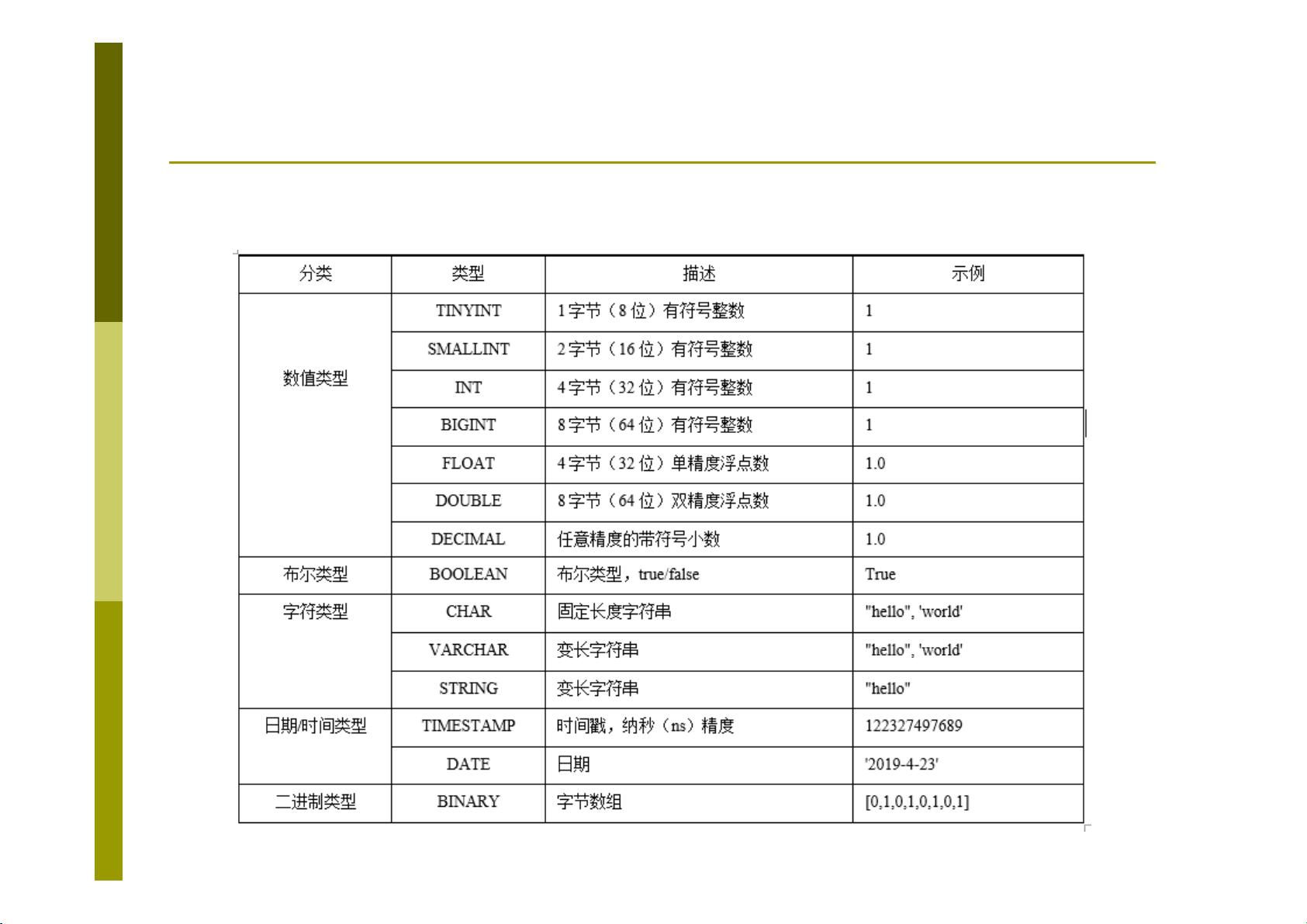
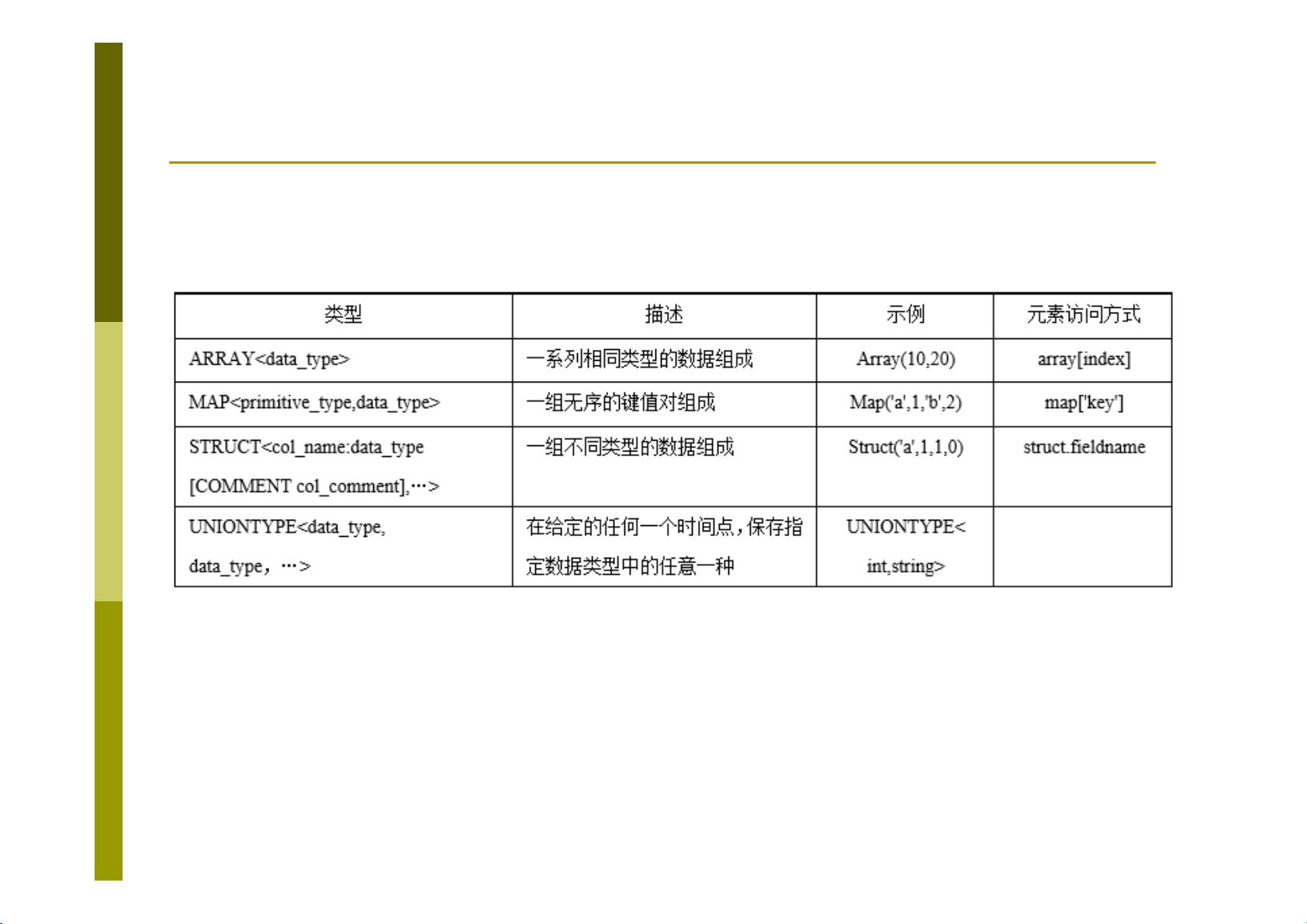
Hive的数据操作分为DDL(Data Definition Language)和DML(Data Manipulation Language)两大类。DDL主要包括创建、修改和删除表等操作,而DML则涉及插入、更新和删除数据,以及各种查询操作。Hive还提供了一系列内置函数,用于数据处理和分析。
Hive的高级应用包括分区、桶、视图和索引等特性,这些特性可以提高数据处理的效率和灵活性。同时,Hive允许用户编写自定义函数(UDF),以应对内置函数无法满足的复杂计算需求。
在对比传统数据库时,Hive虽然提供了类似SQL的查询接口,但它不支持低延迟查询和行级别的数据更新,更适合离线分析。此外,Hive在容错性和可扩展性方面表现出色,能够随着集群规模的扩大而扩展,且在节点故障时仍能保持服务的连续性。
最后,Hive在Hadoop生态系统中的位置是至关重要的,它与其他组件如HDFS(用于数据存储)、MapReduce(用于并行计算)以及YARN(资源调度)紧密配合,共同构建了一个强大的大数据处理框架。

Hadoop 3.X 大数据平台技术与应用开发
数据库(database)
每个数据库对应HDFS中一个文件夹
内部表(Table)
每一个内部表在Hive中都有一个相应的同名目录存储数据。
向内部表中加载数据时,实际数据文件移动到内部表对应文件夹中
删除内部表时,表中的数据和元数据将会被同时删除
外部表(External Table)
外部表的创建与数据加载同时完成,并不会移动数据到Hive的存储
目录中,只是与外部数据建立了一个链接
当删除外部表时,只是删除了该链接,并不会删除实际的外部数据
6.1.4 Hive数据存储模型


剩余108页未读,继续阅读
3423 浏览量
501 浏览量
1069 浏览量
273 浏览量
221 浏览量
290 浏览量
176 浏览量
282 浏览量
284 浏览量
162 浏览量

oracle_teacher
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 三态树源码实现详解及树形控件应用
- DoomViewer开源项目:经典游戏地图浏览工具
- Java Web中灵活的日期控件使用指南
- 探索jQuery Form插件:源码与压缩版解析
- 全技术栈项目源码资源包:仿泡椒网WAP安卓网站模板
- 深入学习Verilog HDL的优质教程资源
- panel-nvim:打造高效vim工作仪表板
- C# HTN-Planner: 探索与实现CHP开源项目
- 清华人工神经网络电子讲稿及Matlab应用教程
- C结构体序列化库:支持XML/JSON/Binary格式
- 利用jquery.qrcode.min.js实现网页生成可扫描二维码
- 专业AVI转码器:速度与效率兼顾的最佳工具
- WPF实现炫酷页面淡入淡出效果指南
- 开源工具包tools4BCI助力脑机交互标准化
- 全面掌握DSP开发技术全攻略
- 深入了解Linux下的PowerThIEf后渗透工具
