决策树与随机森林详解:从原理到Python实现
20 浏览量
更新于2024-08-28
收藏 555KB PDF 举报
"决策树与随机森林"
决策树是一种监督学习算法,常用于分类和回归问题。它通过构建一系列规则来做出决策,这些规则基于输入数据的特征。与线性模型不同,决策树不是通过所有特征的加权组合来预测结果,而是通过一系列条件判断(即特征的分割)来逐步划分数据集,直到达到预设的终止条件。
在决策树的生成过程中,关键概念包括根节点、父节点、子节点和叶节点。根节点代表整个数据集,父节点对应一个特征的选择,子节点是基于该特征的不同取值划分出的数据子集,而叶节点则表示最终的分类或预测结果。决策树的生成目标是找到最优的特征和分割点,使得数据集的纯度最大化或者不纯度最小化。
纯度通常由不同的指标来度量,如信息熵、信息增益、信息增益率和基尼指数。ID3算法使用信息增益,C4.5算法采用信息增益率,而CART(Classification And Regression Tree)算法使用基尼系数。在建树过程中,算法会遍历所有特征并选择能带来最大纯度提升的特征作为分割点。之后,数据集会根据该特征的不同取值进一步分割,这个过程不断重复,直到满足停止条件,如达到预设的最大深度、最小样本数或者节点纯度阈值。
剪枝是防止过拟合的重要步骤,它通过去掉部分分支来简化模型。预剪枝是在树构建过程中提前设定停止条件,如达到预定的最小叶子节点样本数;后剪枝则是在树完全构建后,从底部开始删除不会显著降低模型性能的分支。
随机森林是决策树的集成学习版本,通过构建多个决策树并取其平均结果来提高模型的稳定性和预测准确性。在随机森林中,每个树都是独立生成的,通常在每次分裂时只考虑特征子集,并且每个树都会随机采样一部分数据(袋外数据)进行训练。这样可以减少树之间的相关性,增加多样性,从而提升整体模型的泛化能力。
在Python中,可以使用`scikit-learn`库来实现决策树和随机森林的训练与预测。`sklearn.tree.DecisionTreeClassifier`和`sklearn.ensemble.RandomForestClassifier`是常用的类,它们提供了丰富的参数调整选项,以适应各种不同的问题和数据集。
决策树和随机森林因其直观性、可解释性和良好的性能,成为了机器学习中非常受欢迎的工具。它们可以处理非线性关系,适用于特征间存在交互效应的情况,并且对于缺失值有一定的鲁棒性。然而,决策树容易过拟合,随机森林则通过集成方法有效缓解了这一问题,提高了模型的泛化性能。
决策树与随机森林决策树与随机森林
首先,在了解树模型之前,自然想到树模型和线性模型有什么区别呢?其中最重要的是,树形模型是一个一个特征进行处理,
之前线性模型是所有特征给予权重相加得到一个新的值。决策树与逻辑回归的分类区别也在于此,逻辑回归是将所有特征变换
为概率后,通过大于某一概率阈值的划分为一类,小于某一概率阈值的为另一类;而决策树是对每一个特征做一个划分。另外
逻辑回归只能找到线性分割(输入特征x与logit之间是线性的,除非对x进行多维映射),而决策树可以找到非线性分割。
而树形模型更加接近人的思维方式,可以产生可视化的分类规则,产生的模型具有可解释性(可以抽取规则)。树模型拟合出
来的函数其实是分区间的阶梯函数。
其次,需要了解几个重要的基本概念:根节点(最重要的特征);父节点与子节点是一对,先有父节点,才会有子节点;叶节
点(最终标签)。
一、决策树
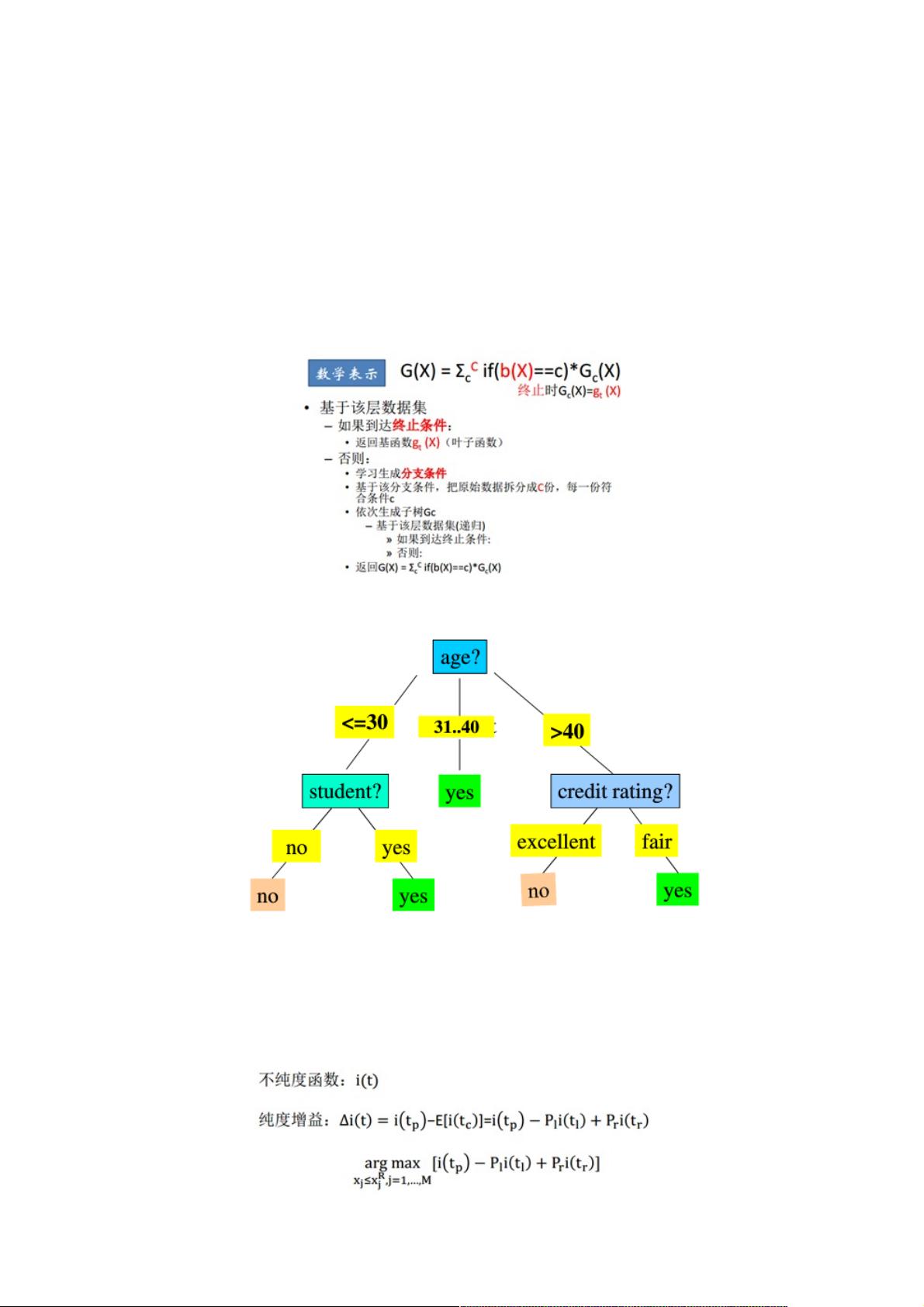
决策树生成的数学表达式:
决策树的生成:
决策树思想,实际上就是寻找最纯净的划分方法,这个最纯净在数学上叫纯度,纯度通俗点理解就是目标变量要分得足够开
(y=1的和y=0的混到一起就会不纯)。另一种理解是分类误差率的一种衡量。实际决策树算法往往用到的是,纯度的另一面
也即不纯度,下面是不纯度的公式。不纯度的选取有多种方法,每种方法也就形成了不同的决策树方法,比如ID3算法使用信
息增益作为不纯度;C4.5算法使用信息增益率作为不纯度;CART算法使用基尼系数作为不纯度。
决策树要达到寻找最纯净划分的目标要干两件事,建树和剪枝
下载后可阅读完整内容,剩余4页未读,立即下载
2021-09-23 上传
2022-08-08 上传
2021-09-11 上传
2021-09-10 上传
2023-02-08 上传
点击了解资源详情
点击了解资源详情
2023-04-22 上传

weixin_38609401
- 粉丝: 5
- 资源: 936
 我的内容管理
展开
我的内容管理
展开







最新资源
- scratchduino-blockly:基于Blockly的ScratchDuino机器人构建套件的可视化编程编辑器
- Java六角结构
- damassh
- rpi-garage-door:树莓派自动车库门控制器
- weex-native-directive:Weex本机指令设计
- Linux驱动开发:Linux内核模块、字符设备驱动、IO模型、设备树、GPIO子系统、中断子系统.zip
- نوسان-crx插件
- yifanchen0811.github.io
- rails-infinite-scroll-posts
- WebServiceProj:这是测试 Web 服务项目。 Spring Data Mongo,泽西岛 JAX-RX
- java web期末考核
- radiopadre:(无线电)Python天文学数据缩减审查员
- everyplay-unity-sdk:Everyplay Unity插件
- grunt-contrib-copy:复制文件和文件夹
- Công cụ đặt hàng Aliviet-crx插件
- paperspeaker.github.io
