ID3算法详解:从熵到信息增益
"ID3算法是一种用于分类的决策树算法,它通过计算信息增益来选择最佳属性进行划分。该算法基于熵的概念,熵是用来衡量数据集合纯度的统计特性。ID3算法首先计算整个样本集的熵,然后通过计算每个属性分割后的条件熵,找出信息增益最大的属性作为分裂节点。信息增益是熵减少的程度,表示选择该属性进行划分时能提供的分类信息。
在ID3算法中,熵的计算公式为:Entropy(S) = Σ-p(I)log2p(I),其中p(I)是属于类I的样本在S中的比例,C是类别总数。当所有样本属于同一类别时,熵为0,表示数据已经完全分类;反之,若样本均匀分布,熵接近1,表示数据完全随机。
条件熵Entropy(S, A)计算的是属性A在样本集S上的熵,它是通过计算属性A所有可能值v的子集Sv的熵并加权平均得到的:Entropy(S, A) = Σ(|Sv|/|S|) * Entropy(Sv)。|Sv|表示子集Sv的样本数量,|S|表示样本集S的总样本数。
信息增益Gain(S, A)是熵减少的度量,公式为:Gain(S, A) = Entropy(S) - Entropy(S, A)。信息增益越大,表明属性A对于分类的贡献越大。ID3算法会选择信息增益最高的属性作为决策树的下一个分支。
以一个简单的例子来说明,假设我们要根据天气情况判断是否适合打垒球。数据集包含14天的记录,有两个类别(可以或不可以打垒球),四个属性(户外、温度、湿度和风速)。每个属性都有多个可能的值。ID3算法会遍历所有属性,计算信息增益,然后选择信息增益最大的属性作为决策树的第一个节点,以此类推,构建出完整的决策树。
这个例子中,ID3会首先计算所有14天数据的整体熵,然后分别计算每个天气属性(户外、温度、湿度和风速)分割后的条件熵,进而计算信息增益。选择信息增益最大的属性作为决策树的根节点,接着对每个分支继续这个过程,直到所有数据被正确分类或者没有更多的属性可以分割为止。
总结来说,ID3算法是一种基于信息论的决策树构建方法,它通过比较属性的信息增益来确定最佳划分,从而生成一个能够有效分类数据的决策树模型。虽然在处理连续属性和大规模数据集时效率较低,但其直观的决策规则和易于理解的结构使得ID3成为机器学习领域经典的基础算法之一。"
更多精彩文章,欢迎访问“统计之都”:www.cos.name
D12 阴天 温柔 高 强 进行
D13 阴天 炎热 正常 弱 进行
D14 雨天 温柔 高 强 取消
END DATA.
EXE.
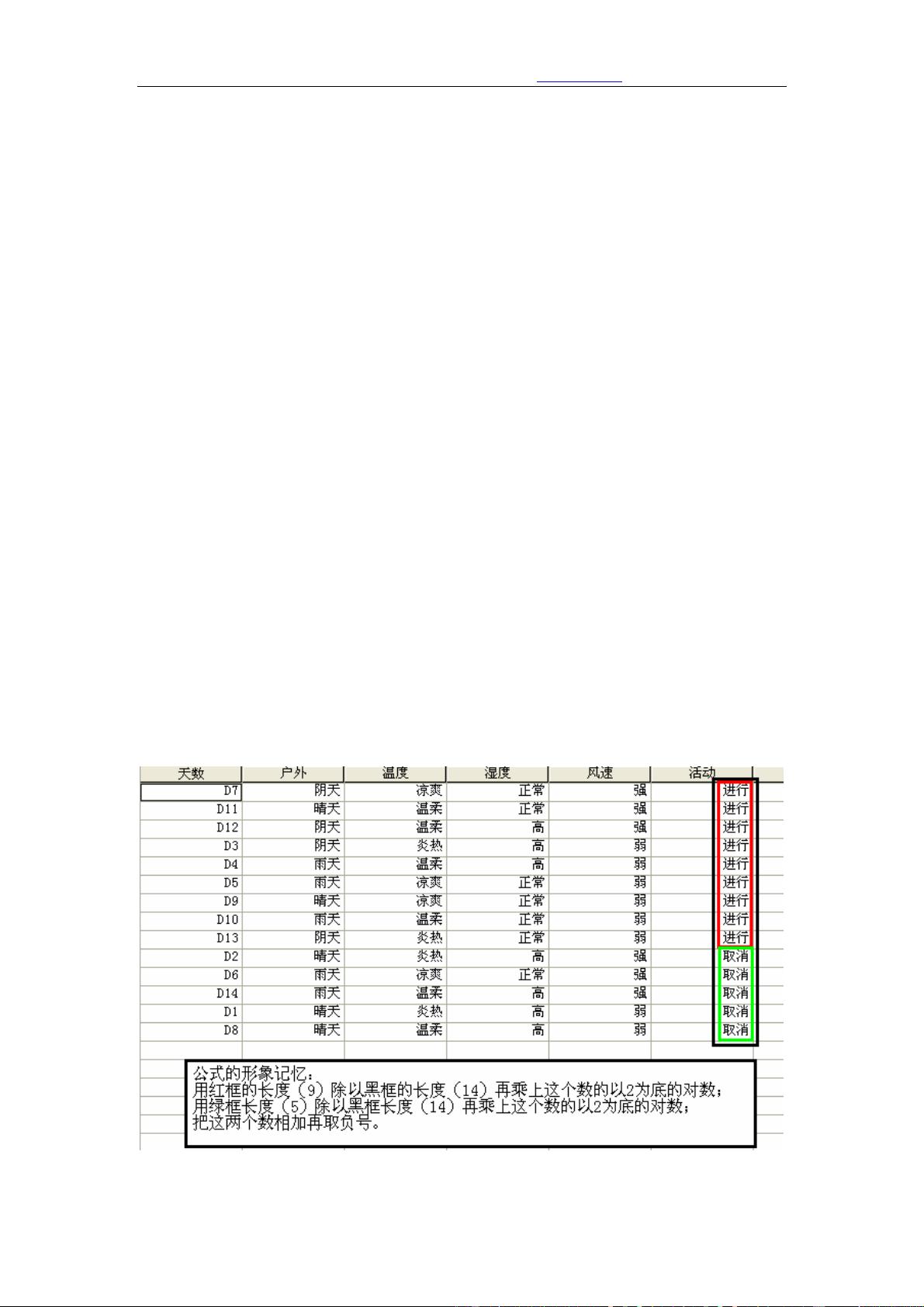
第一步 :计算决策属性的熵
决策属性活动有 14 个记录,其中 9 个记录活动可以进行,5 个记录不适合活动,
那么使用公式 1 计算熵。
Entropy(活动) = - (9/14) Log2 (9/14) - (5/14) Log2 (5/14) = 0.940
声明一下,由于在 SPSS 中没有找到以 2 为底的对数函数,所以这部分计算熵的
工作不得不自己动手完成,尽管十分不情愿。
如果直接计算上式,相信多数人不会有太多的印象,要是对熵的概念不是很熟悉,
还真有点不好记,还是利用人类适合记忆图像的特点,将计算过程图示化。
按变量活动对数据进行排序:
SORT CASES BY 活动 .
EXE.
观察变量活动那一列,9 个适合活动的记录,5 个不适合活动的记录,比较醒目。
3
剩余14页未读,继续阅读
231 浏览量
点击了解资源详情
点击了解资源详情
2008-05-19 上传
2022-07-15 上传
122 浏览量
376 浏览量

guoycyz1020
- 粉丝: 1
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







