最大似然估计与最大验后估计解析
需积分: 50 42 浏览量
更新于2024-09-08
收藏 94KB DOC 举报
"最大似然估计与最大验后估计是两种在统计学和机器学习中用于参数估计的重要方法。本文将详细介绍这两种方法,并通过实例进行解释。
最大似然估计(Maximum Likelihood Estimation, MLE)是一种基于观察数据来确定模型参数的常见技术。在MLE中,我们假设有一个模型,但模型的参数未知。例如,如果我们想估计全国人口的身高分布,可以假设身高服从正态分布,但不知道具体的均值和方差。通过采样一部分人的身高,我们可以使用最大似然估计来估计正态分布的均值和方差。关键假设是所有采样都是独立同分布的。
具体来说,设我们有独立同分布的样本集X = {x1, x2, ..., xn},模型f依赖于参数θ,最大似然估计就是找到使样本集出现概率最大的参数θ。似然函数L(θ|X)定义为在给定参数θ下,样本集X出现的概率,即L(θ|X) = f(x1; θ)f(x2; θ)...f(xn; θ)。在实际计算中,通常取对数似然函数log L(θ|X)来简化优化过程,因为对数函数是非负且单调增加的。最大化对数似然等价于最大化平均对数似然,即求解使得E[log L(θ|X)]最大的θ,这被称为最大对数似然估计。
以黑白球比例的例子来说明,假设罐中有一定数量的黑白球,比例未知。我们多次抽取并记录球的颜色,每次抽取后球放回,形成独立同分布的样本。如果100次抽取中有70次是白球,我们想要估计白球的比例p。根据最大似然估计,我们寻找使得样本出现概率最大的p,即最大化P(Data|M),其中Data是抽取的结果,M是模型(每次抽到白球的概率为p)。计算这个概率时,我们考虑每次抽取的独立性,将所有抽取结果的概率乘起来。
最大验后估计(Maximum A Posteriori, MAP)是最大似然估计的一种扩展,它考虑了先验知识。在MAP中,除了似然函数外,还包括了参数的先验概率分布。假设参数θ有先验概率分布π(θ),那么MAP估计是找到使得后验概率P(θ|Data)最大的θ,即:
\[ \hat{\theta}_{MAP} = \arg\max_{\theta} P(\theta|Data) = \arg\max_{\theta} \frac{P(Data|\theta) \cdot \pi(\theta)}{P(Data)} \]
其中P(Data)是归一化常数,不影响θ的选择。因此,MAP估计实际上是最大化似然函数与先验概率的乘积。
总结来说,最大似然估计只依赖于观察数据,而最大验后估计则结合了先验信息。在实际应用中,两者都是估计模型参数的重要工具,选择哪种方法取决于我们是否有可用的先验信息以及如何权衡先验与数据的重要性。"
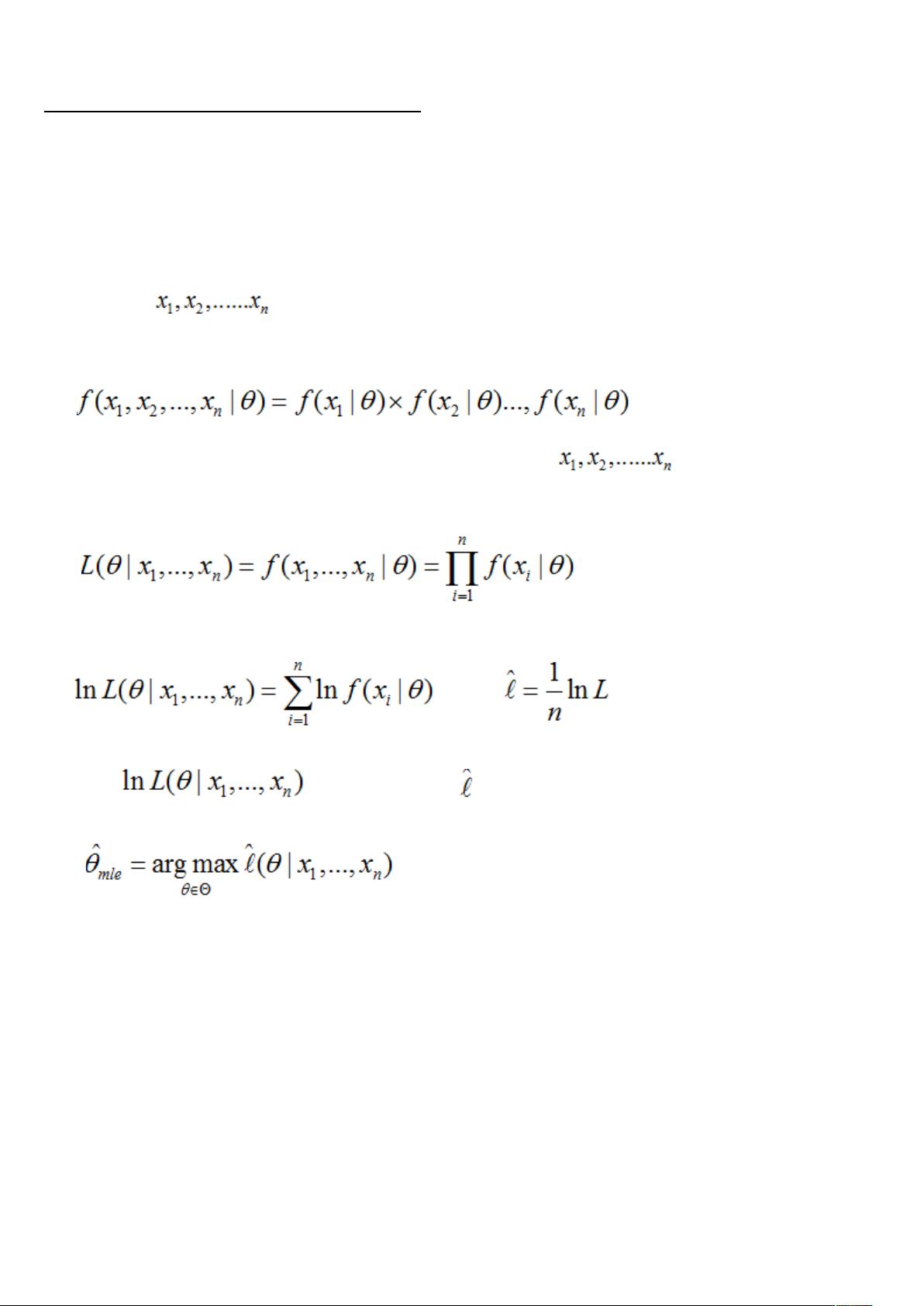
最大似然估计 (Maximum likelihood estimation)
最大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。简单而
言,假设我们要统计全国人口的身高,首先假设这个身高服从服从正态分布,但是该分布的均值与方
差未知。我们没有人力与物力去统计全国每个人的身高,但是可以通过采样,获取部分人的身高,然
后通过最大似然估计来获取上述假设中的正态分布的均值与方差。
最大似然估计中采样需满足一个很重要的假设,就是所有的采样都是独立同分布的。下面我们具体
描述一下最大似然估计:
首先,假设 为独立同分布的采样,θ 为模型参数,f 为我们所使用的模型,遵循我们上述
的独立同分布假设。参数为 θ 的模型 f 产生上述采样可表示为
回到上面的“模型已定,参数未知”的说法,此时,我们已知的为 ,未知为 θ,故似然定义
为:
在实际应用中常用的是两边取对数,得到公式如下:
其中 称为对数似然,而 称为平均对数似然。而我们平时所称的最大似然
为最大的对数平均似然,即:
举个别人博客中的例子,假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,两种颜色的
比例也不知。我 们想知道罐中白球和黑球的比例,但我们不能把罐中的球全部拿出来数。现在我们可
以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球 再放回罐中。这个过
程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。假如在前面的一百次重复记录中,
有七十次是白球,请问罐中白球所占的比例最有可能是多少?很多人马上就有答案了:70%。而其后的
理论支撑是什么呢?
我们假设罐中白球的比例是 p,那么黑球的比例就是 1-p。因为每抽一个球出来,在记录颜色之后,
我们把抽出的球放回了罐中并摇匀,所以每次抽出来的球的颜 色服从同一独立分布。这里我们把一次
抽出来球的颜色称为一次抽样。题目中在一百次抽样中,七十次是白球的概率是 P(Data | M),这里
Data 是所有的数据,M 是所给出的模型,表示每次抽出来的球是白色的概率为 p。如果第一抽样的结果
记为 x1,第二抽样的结果记为 x2... 那么 Data = (x1,x2,…,x100)。这样,
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-03 上传
2018-03-16 上传
2023-05-25 上传
2023-05-27 上传
2023-06-01 上传
2021-09-30 上传

iaxiaoq
- 粉丝: 5
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
