Ubuntu与Spark安装教程:从VMware到配置
需积分: 10 37 浏览量
更新于2024-07-07
1
收藏 7.7MB DOCX 举报
"该文档提供了一份详尽的Spark本地版在Ubuntu系统上的安装教程,教程覆盖了使用VMware虚拟机的安装、Ubuntu系统的下载与安装、Hadoop的安装与配置以及Spark的安装配置。适用于想要在Ubuntu环境中搭建Spark开发环境的用户。"
在安装Spark本地版之前,首先需要在Ubuntu系统上搭建基础环境。这份教程首先指导用户如何使用VMware进行虚拟机的安装。VMware是一款强大的虚拟机软件,允许用户在一台物理机器上运行多个操作系统。安装步骤包括访问VMware官方网站下载最新版软件,安装过程中需要注意路径设置不应包含中文字符,并可以选择试用或输入密钥激活。
接下来,教程转向Ubuntu的安装。用户需要从Ubuntu官网下载相应的桌面版镜像文件,然后在VMware中创建新的虚拟机。在虚拟机设置中,选择Linux操作系统和Ubuntu 64位版本,调整虚拟机的存储路径,避免使用C盘并确保无中文路径。此外,还需要合理配置内存和处理器资源,以适应Ubuntu的运行需求。在硬件设置中,关联下载好的Ubuntu ISO镜像文件,网络适配器设置为NAT模式。
安装Ubuntu时,选择中文语言,进行键盘布局设置,并按照提示进行安装过程。一旦Ubuntu安装完成并启动,用户可以进一步安装Hadoop和Spark。Hadoop是分布式计算框架,为Spark提供数据存储和处理的基础。在Ubuntu中,Hadoop的安装通常涉及下载源码、编译配置、修改环境变量等一系列步骤,确保Hadoop集群能正常运行。
最后,Spark的安装配置涉及到下载Spark源码或二进制包,设置环境变量,以及可能的Hadoop兼容性配置。对于本地版Spark,一般不需要集群配置,但仍然需要确保Java环境的正确安装,并且Spark的bin目录添加到PATH环境变量中,以便于在命令行中直接运行Spark命令。
整个过程虽然复杂,但遵循此文档的步骤,用户可以逐步构建一个适合开发和学习Spark的本地Ubuntu环境。这对于学习大数据处理和分析的初学者,或是需要在Ubuntu环境下测试Spark功能的专业人士来说,都是非常有价值的指南。
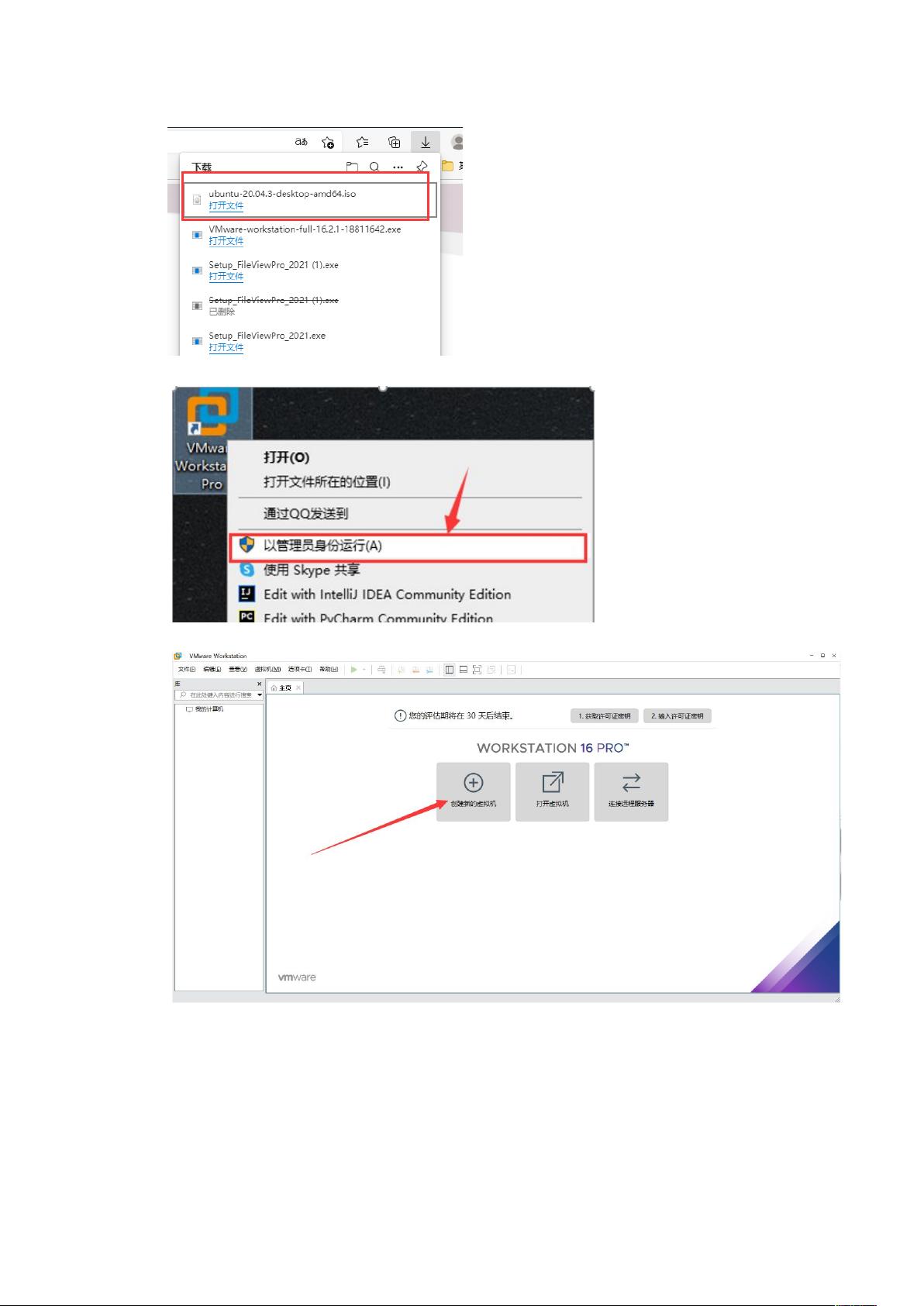
4、找到桌面的 VMware,右键以管理员身份运行
5、打开后,点击创建新的虚拟机
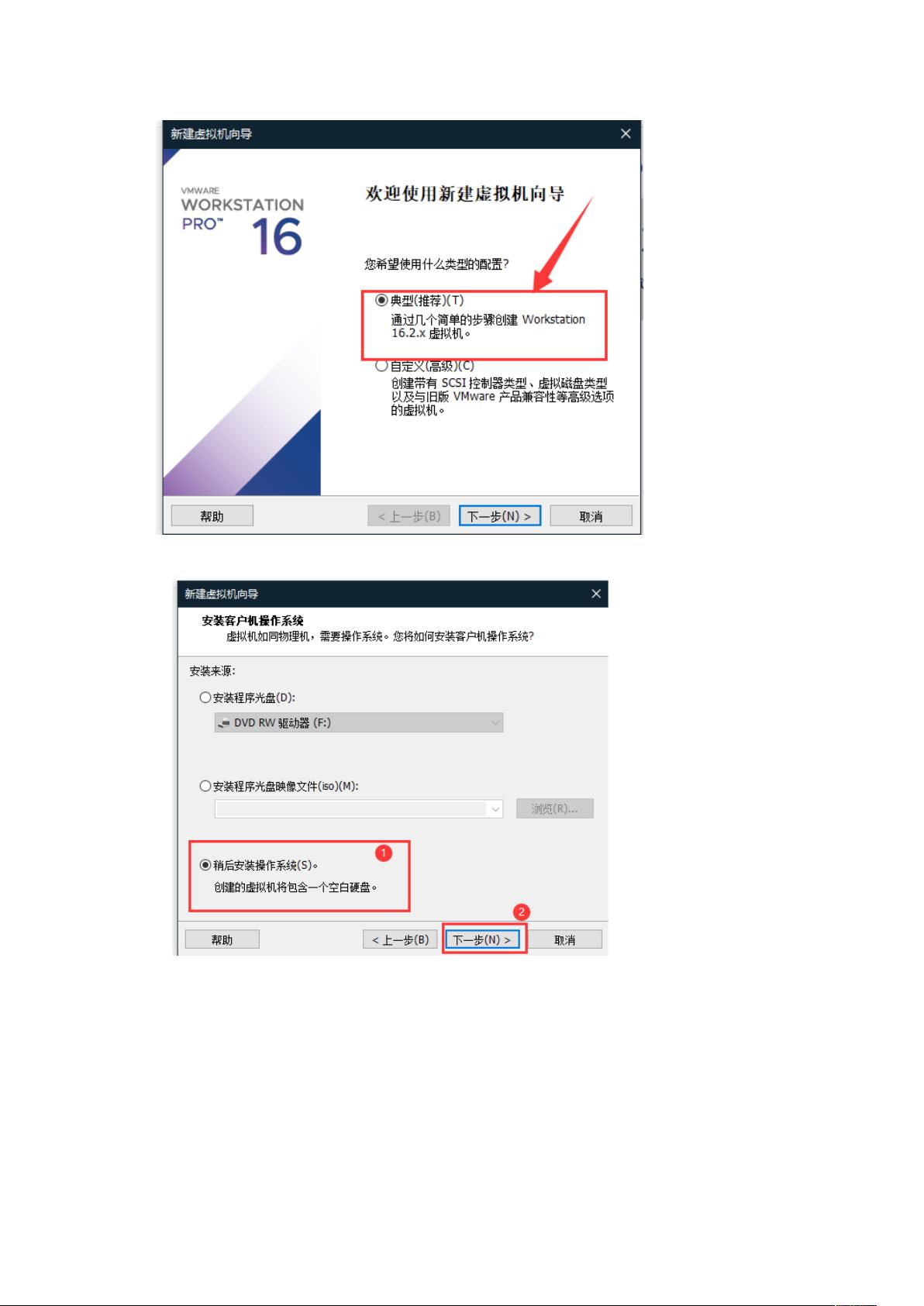
6、选择典型,然后下一步
剩余39页未读,继续阅读
2024-07-15 上传
2021-09-14 上传
2021-10-30 上传
2021-10-03 上传
2021-11-27 上传
2022-11-27 上传
2024-07-16 上传
2019-11-28 上传
2024-07-14 上传

zz酱
- 粉丝: 2
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
