自动驾驶汽车安全:超越道路测试的挑战
版权申诉
96 浏览量
更新于2024-07-20
收藏 5.11MB PDF 举报
"本次演讲的主题是《自动驾驶汽车安全的大局》,由Philip Koopman教授在2019年的Safe Systems Summit上发表。讨论了自动驾驶汽车的安全标准,包括传统的车辆软件安全、驾驶辅助系统的安全(ADAS/SOTIF)、全自动驾驶的安全问题以及系统生命周期、社会与伦理问题。"
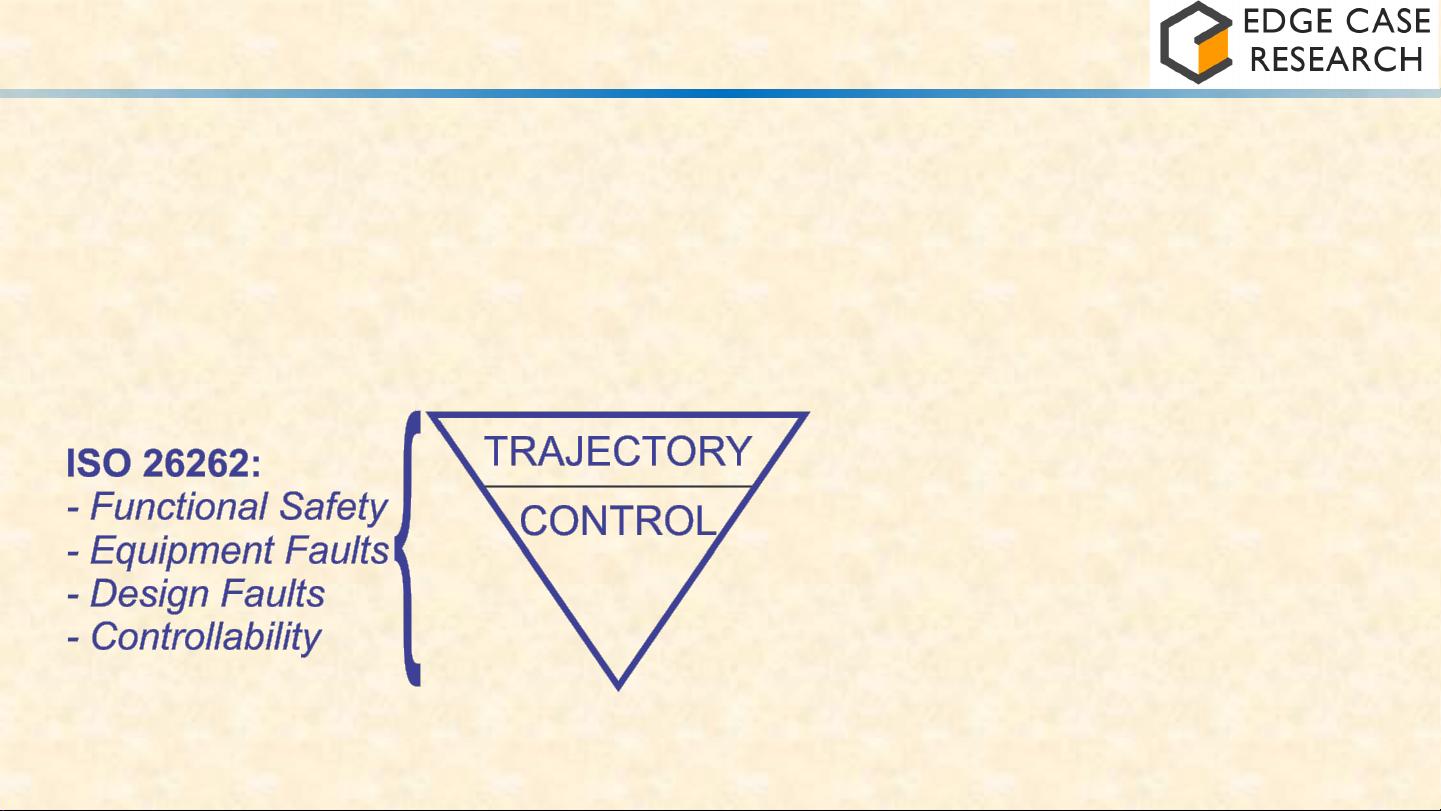
在自动驾驶汽车安全领域,首先提到了传统的车辆软件安全,这部分着重于确保车辆硬件设备的正常运行,并避免设计缺陷导致的安全问题。驾驶员对行车安全负有最终责任,即功能性安全,需要确保车辆能够正确执行如转向等基本操作,并在设备故障时做出响应,保持可控性。
接着,演讲探讨了驾驶辅助系统(ADAS)的安全性,这些系统旨在帮助驾驶员在特定情况下进行辅助驾驶,但同时也提出了安全之外的适合性问题(SOTIF),即系统在未预期或边界条件下的表现。
对于全自动驾驶的安全,Koopman教授强调了感知、运营和系统生命周期的重要性。自动驾驶汽车需要具备精确的环境感知能力,以理解并应对复杂的交通情况。运营方面,如何在实际道路环境中安全有效地运行是一个挑战。系统生命周期则涵盖了从设计、开发、测试到部署和维护的全过程,确保每个阶段都符合安全标准。
针对大规模的道路测试,Koopman教授指出,单纯依赖大量的实地测试来验证安全性能是不现实的。如果每百万英里才发生一次关键事故,那么要进行三到十倍于事故率的测试,即可能需要测试10亿英里,这相当于在全球所有公路上往返约25次,而且可能还遇不到10次关键事故。因此,他提倡基于标准的安全工程方法,通过系统性的设计和验证来确保安全性。
此外,演讲还涉及了自动驾驶带来的社会和伦理问题,比如如何处理自动驾驶汽车在道德困境中的决策,以及如何获得公众的信任和接受。这些问题不仅涉及到技术层面,还关系到法律、道德和社会规范的制定。
这篇演讲揭示了自动驾驶汽车安全的多维度挑战,从技术、法规、伦理等多个角度探讨了实现安全自动驾驶所需考虑的关键因素。为了确保自动驾驶汽车的安全,必须综合运用标准驱动的安全工程方法,同时解决社会和伦理层面的复杂问题。
5
© 2019 Philip Koopman
Human driver ultimately responsible for safety
“Functional Safety” – respond to equipment; avoid design faults
Human does the right thing for malfunctions (“Controllability”)
Conventional Vehicle Safety
Vehicle motion
Perform turns, etc.
剩余24页未读,继续阅读
2021-10-02 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传

电动汽车控制与安全
- 粉丝: 263
- 资源: 4186
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
