
MySQL索引底层实现原理索引底层实现原理
索引的本质
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本
质:索引是数据结构。
我们知道,数据库查询是数据库的最主要功能之一。我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从
查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显
然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary
tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据
有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能
同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某
种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
看一个例子:
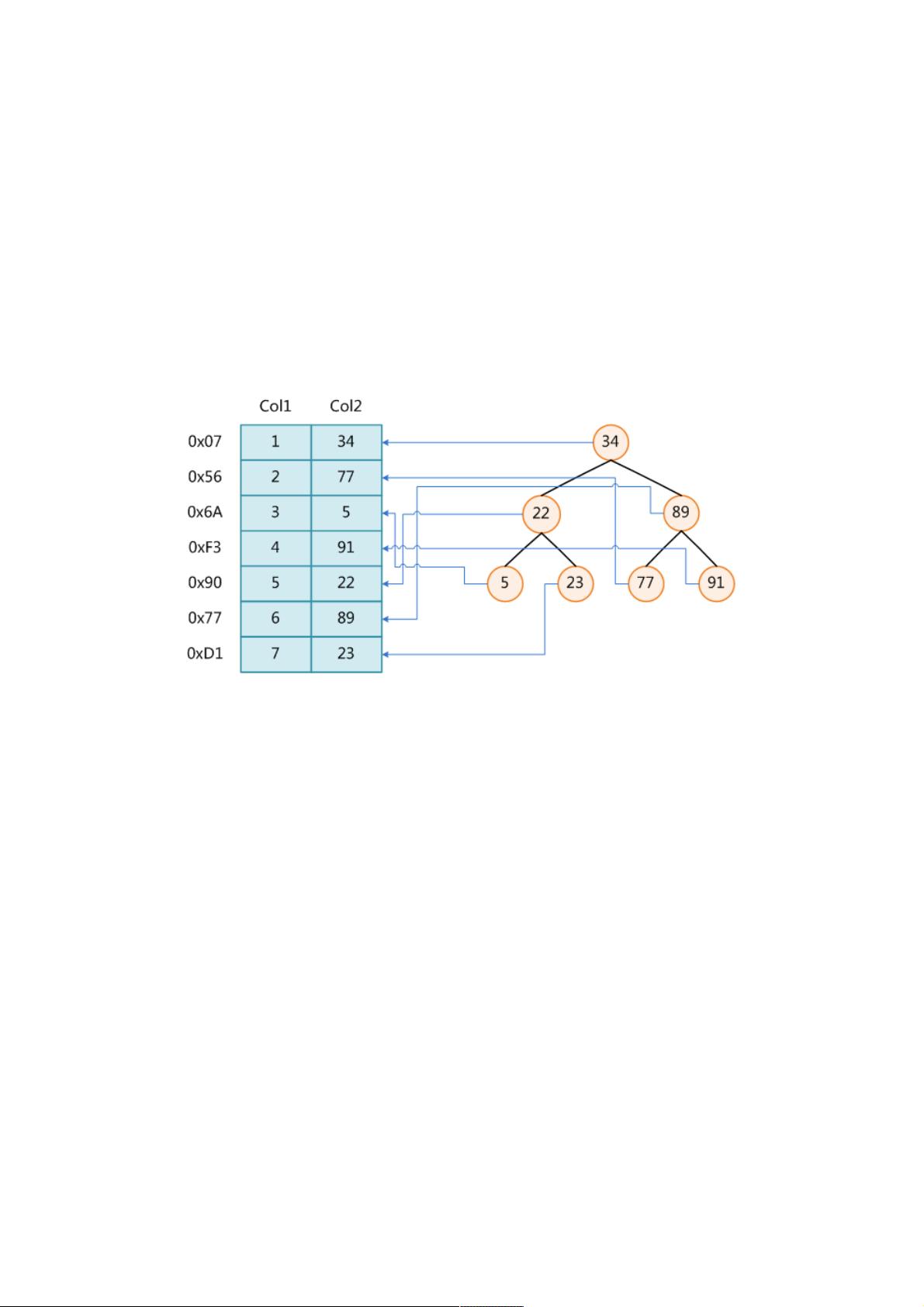
上图展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的
记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含
索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(logn2)O(log2n)的复杂度内获取到相应数
据。
虽然这是一个货真价实的索引,但是实际的数据库系统几乎没有使用二叉查找树或其进化品种红黑树(red-black tree)实现
的,原因会在下文介绍。
二叉排序树
在介绍B树之前,先来看另一棵神奇的树——二叉排序树(Binary Sort Tree),首先它是一棵树,“二叉”这个描述已经很明显
了,就是树上的一根树枝开两个叉,于是递归下来就是二叉树了(下图所示),而这棵树上的节点是已经排好序的,具体的排
序规则如下:
若左子树不空,则左子树上所有节点的值均小于它的根节点的值
若右子树不空,则右字数上所有节点的值均大于它的根节点的值
它的左、右子树也分别为二叉排序数(递归定义)
下载后可阅读完整内容,剩余7页未读,立即下载

weixin_38556822
- 粉丝: 2
- 资源: 974
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


