Hadoop分布式配置检查与环境设置详解
需积分: 9 153 浏览量
更新于2024-09-06
收藏 217KB DOCX 举报
本文档详细介绍了如何配置Hadoop分布式系统,以便在三台虚拟机上搭建并验证其正常运行。以下是关键步骤的详细说明:
1. **修改`hadoop-env.sh`**:
- 首先,你需要切换到Hadoop的配置目录 `/usr/local/hadoop/etc/hadoop/`。
- 使用`sudo vim hadoop-env.sh`或`sudo nano hadoop-env.sh`来编辑该文件,确保JAVA_HOME指向正确安装的Java环境,如`export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64`。
- 这个步骤很重要,因为`hadoop-env.sh`文件包含了与Hadoop运行相关的环境变量设置。
2. **配置`core-site.xml`**:
- 同样,切换到`/usr/local/hadoop/etc/hadoop/`目录。
- 打开`core-site.xml`,在这个文件中,你需要在 `<configuration>` 标签之间添加配置,比如设置临时目录 `hadoop.tmp.dir` 为 `/usr/local/hadoop/tmp` 和指定文件系统默认URI为 `fs.defaultFS`,例如 `hdfs://master:9000`。
3. **管理`slaves` 文件**:
- 进入`slaves` 文件,根据集群规模修改文件内容。对于两台从节点的配置,将`slave1` 和 `slave2` 添加到文件中,格式为一行一个节点名。
4. **配置`hdfs-site.xml`**:
- 在`hdfs-site.xml`中,添加属性来设置DataNode的块副本数,例如 `<dfs.replication><value>3</value></dfs.replication>`,这表示每个块至少有三个副本。同时,可以设置Namenode的存储位置,具体配置项取决于实际环境。
5. **启动Hadoop服务**:
- 通过执行`sbin/start-dfs.sh` 或 `sbin/start-all.sh` 来启动Hadoop分布式服务。如果启动成功,这些命令会在各个节点上启动相应的进程,包括JPS(Java进程监控工具),用于检查服务是否已启动并且正常运行。
6. **验证集群状态**:
- 分别在master节点和从节点上检查Hadoop服务的状态,确认HDFS和YARN等组件是否启动并监听指定端口。可以通过命令行工具如`jps`、`hadoop dfsadmin -report` 和 `yarn node -list`来查看节点状态。
在整个过程中,注意每一步都涉及到对Hadoop配置文件的修改,确保配置项的正确性,因为这直接影响到Hadoop集群的性能、容错能力和数据可靠性。此外,安全性和权限管理也是部署过程中不可忽视的部分,可能需要根据实际情况调整文件权限和SSH配置。
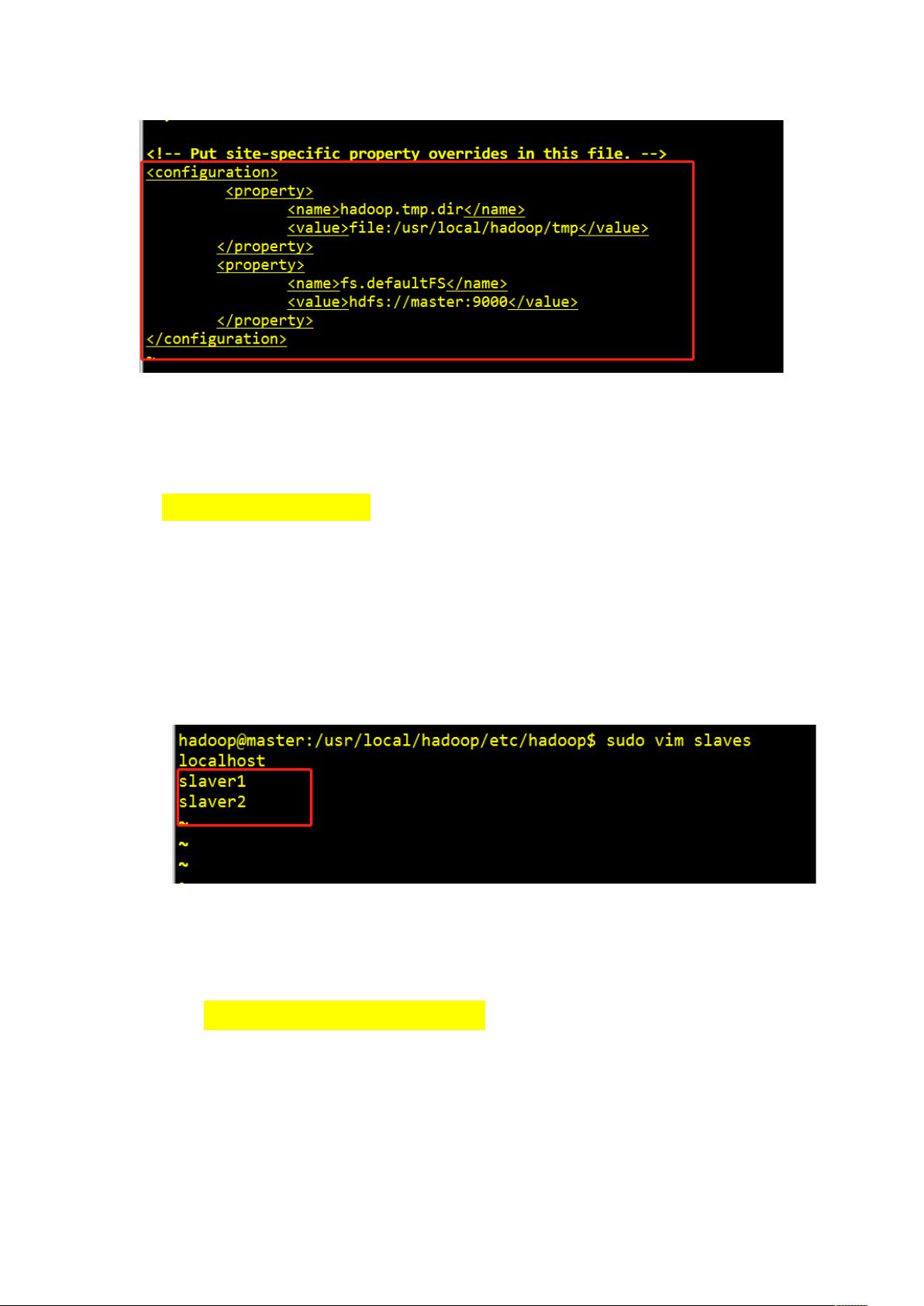
(三)修改 slaves 文件
1.sudo vim slaves
进入 slaves 文件,修改原文件内容为 slave1,slave2,根
据主机搭建的 hadoop 集群节点数多少而进行添加,本次共
有两个从节点,所以作此修改,如图:
slave1 slaver2
(四)修改 hdfs-site.xml 文件
1. sudo vim hdfs-site.xml
打 开 hdfs-site.xml 文 件 , 在 <con)guration></
con)guration>之间添加配置,其中<! …>为说明,无需添
加,如图:
剩余12页未读,继续阅读
596 浏览量
219 浏览量
点击了解资源详情
191 浏览量
352 浏览量
2022-04-16 上传
279 浏览量
192 浏览量









