社交网络分析预测软件缺陷:影响力与应用
需积分: 9 135 浏览量
更新于2024-07-22
收藏 2.05MB PDF 举报
本文档标题为"Social Network Analysis Approach and Applications",主要探讨了社交网络分析在特定领域的应用,特别是通过引用影响力和社交网络分析来预测软件缺陷的研究。作者Wei Hu在2013年秋季提交给阿尔伯塔大学研究生研究学院,作为其获取硕士学位的一部分。该论文着重于计算机科学领域,旨在理解社交网络结构如何与软件开发过程中的问题关联,以及如何利用这些关系来改进软件质量控制。
文章的核心内容可能包括以下几个部分:
1. 社交网络理论基础:首先,介绍了社交网络分析的基本概念,包括节点、边、社区结构等,以及它们在理解和解释人际交互中的作用。这可能涉及到度中心性、接近中心性、聚类系数等指标的定义和计算方法。
2. 引用影响力分析:论文可能讨论了在软件开发环境中,代码贡献者、开发者之间的交流和合作对软件质量的影响。引用次数或代码审查的频率可以被视为衡量个体影响力的指标,它们可能与软件缺陷的出现有所关联。
3. 预测模型构建:研究者可能会提出一种模型,该模型基于社交网络数据和引用影响力,试图预测潜在的软件缺陷。这可能涉及机器学习算法,如回归、分类或聚类技术,以及特征选择和评估模型性能的关键步骤。
4. 实证研究与结果:作者可能分享了他们在阿尔伯塔大学或其他相关项目中收集的数据,并展示了通过这种方法预测软件缺陷的有效性。这部分会包括数据集描述、实验设计以及预测准确性的定量评估。
5. 实践意义与未来方向:论文最后可能讨论了社交网络分析在软件工程中的实际应用价值,比如用于指导团队组织、提升协作效率,以及对于软件维护和演化策略的启示。同时,也可能会提出未来研究的挑战和可能的发展趋势。
这篇论文为读者提供了一种新颖的方法论,展示了社交网络分析在软件缺陷预防中的潜力,对于那些关注软件质量保证和团队协作的IT专业人士具有很高的参考价值。通过深入理解人与人之间的互动如何影响代码的质量,研究人员和实践者可以更好地优化软件开发流程,减少缺陷风险。
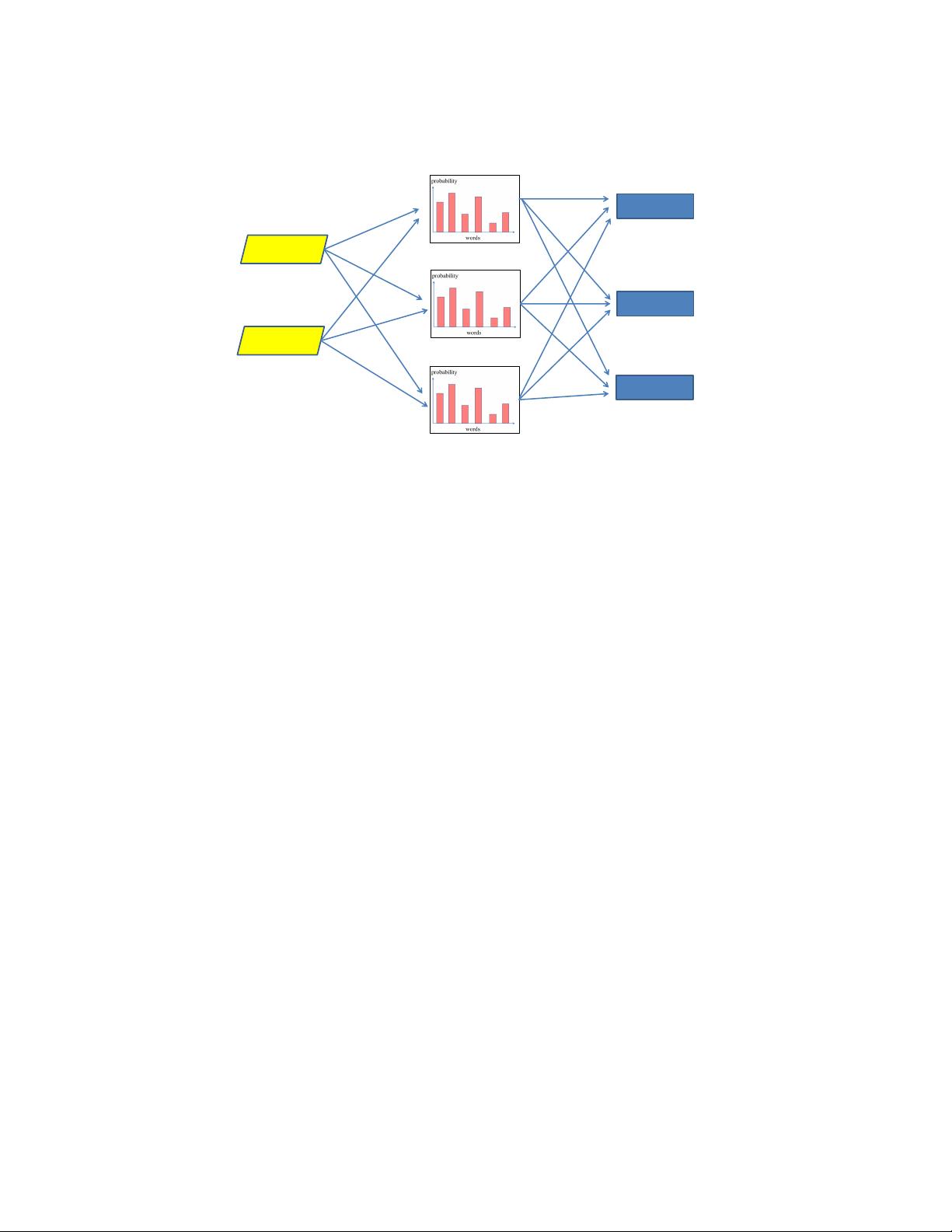
topics
probability
topic
probability
Topic 1
0.301
Topic 2
0.119
Topic 3
0.088
Topic 4
0.071
Topic 5
0.055
Topic 6
0.043
Topic 7
0.032
Topic 8
0.017
Topic 9
0.009
Topic 10
0.008
…
…
Figure 2.5: Document: mixture of topics
its topic mixture according to the probability of each topic under that document, and subsequently
selects a word according to the probability of each word under the selected topic.
Note that the generative process seeks to generate documents with given topic mixtures (distri-
bution over topics) and topics (distribution over words). However, to facilitate text analysis, one
often needs to infer the set of topics and the topic mixtures that were used to generate a collection of
documents, which is opposite to the generative process. Statistical techniques like Gibbs Sampling
[41] can be used to invert this process. The inferred topics and the topic mixture under a document
are used to model that particular document. Informally, Gibbs Sampling can be described as an
iterative process: first randomly select topic mixtures for each document and word distributions for
each topic, and then iteratively adjust the topic mixtures and word distributions given the already
generated documents, until the adjusted topic mixtures and word distributions converge.
9


剩余103页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-01-17 上传
2018-06-19 上传
2016-09-13 上传
2020-07-23 上传
2024-05-14 上传
2021-09-04 上传
点击了解资源详情

lihuiyu19920815
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
