

1.2 Algorithm Description 3
of ID3 and C4.5. Today, C4.5 is superseded by the See5/C5.0 system, a commercial
product offered by Rulequest Research, Inc.
The fact that two of the top 10 algorithms are tree-based algorithms attests to
the widespread popularity of such methods in data mining. Original applications of
decision trees were in domains with nominal valued or categorical data but today
they span a multitude of domains with numeric, symbolic, and mixed-type attributes.
Examples include clinical decision making, manufacturing, document analysis, bio-
informatics, spatial data modeling (geographic information systems), and practically
any domain where decision boundaries between classes can be captured in terms of
tree-like decompositions or regions identified by rules.
1.2 Algorithm Description
C4.5 is not one algorithm but rather a suite of algorithms—C4.5, C4.5-no-pruning,
and C4.5-rules—with many features. We present the basic C4.5 algorithm first and
the special features later.
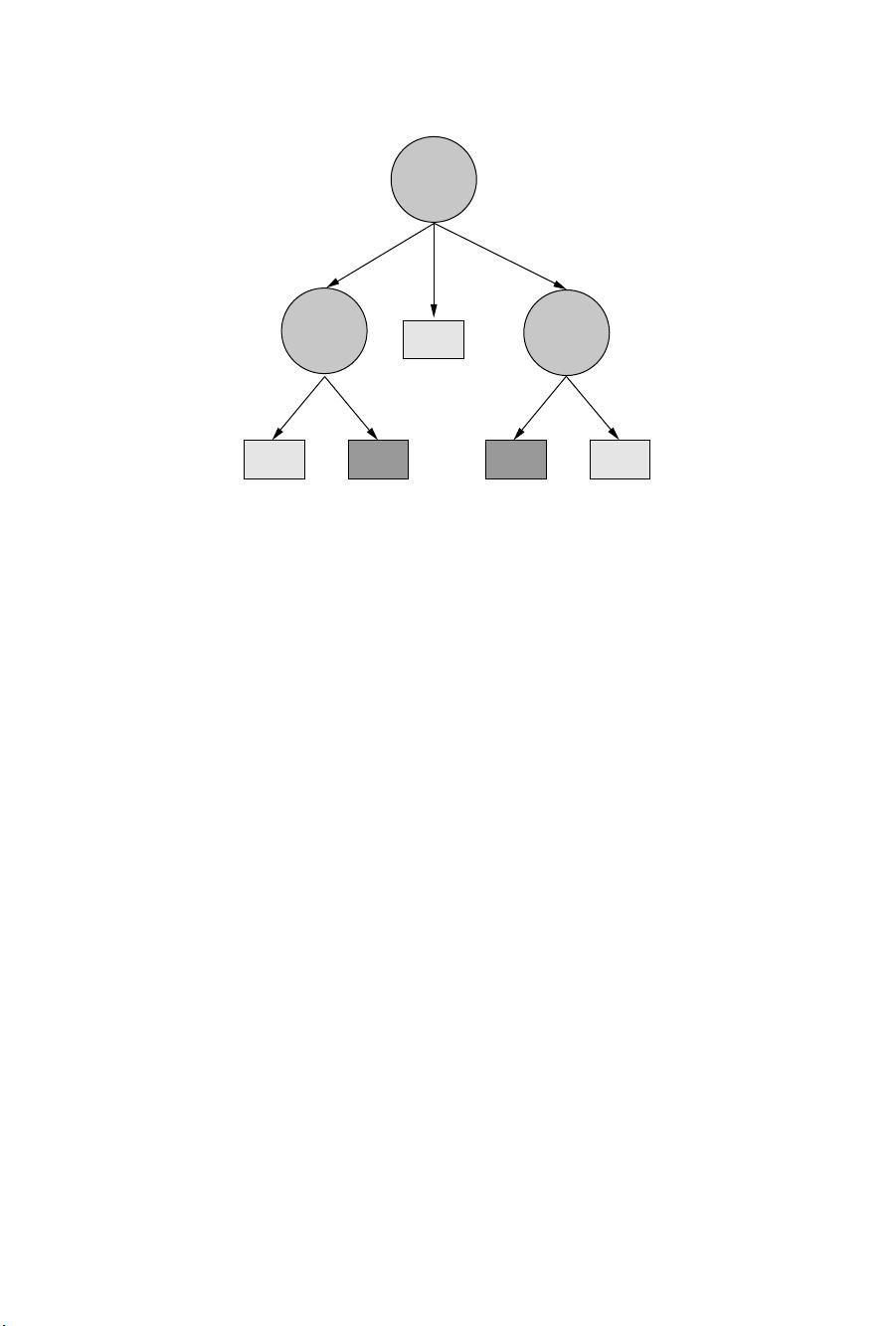
The generic description of how C4.5 works is shown in Algorithm 1.1. All tree
induction methods begin with a root node that represents the entire, given dataset and
recursively split the data into smaller subsets by testing for a given attribute at each
node. The subtrees denote the partitions of the original dataset that satisfy specified
attribute value tests. This process typically continues until the subsets are “pure,” that
is, all instances in the subset fall in the same class, at which time the tree growing is
terminated.
Algorithm 1.1 C4.5(D)
Input: an attribute-valued dataset D
1: Tree = {}
2:
if D is “pure” OR other stopping criteria met then
3: terminate
4: end if
5: for all attribute a ∈ D do
6: Compute information-theoretic criteria if we split on a
7: end for
8: a
best
= Best attribute according to above computed criteria
9: Tree = Create a decision node that tests a
best
in the root
10: D
v
= Induced sub-datasets from D based on a
best
11: for all D
v
do
12: Tree
v
= C4.5(D
v
)
13:
Attach Tree
v
to the corresponding branch of Tree
14: end for
15: return Tree
© 2009 by Taylor & Francis Group, LLC



剩余205页未读,继续阅读

loadbalancing
- 粉丝: 2
- 资源: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


