
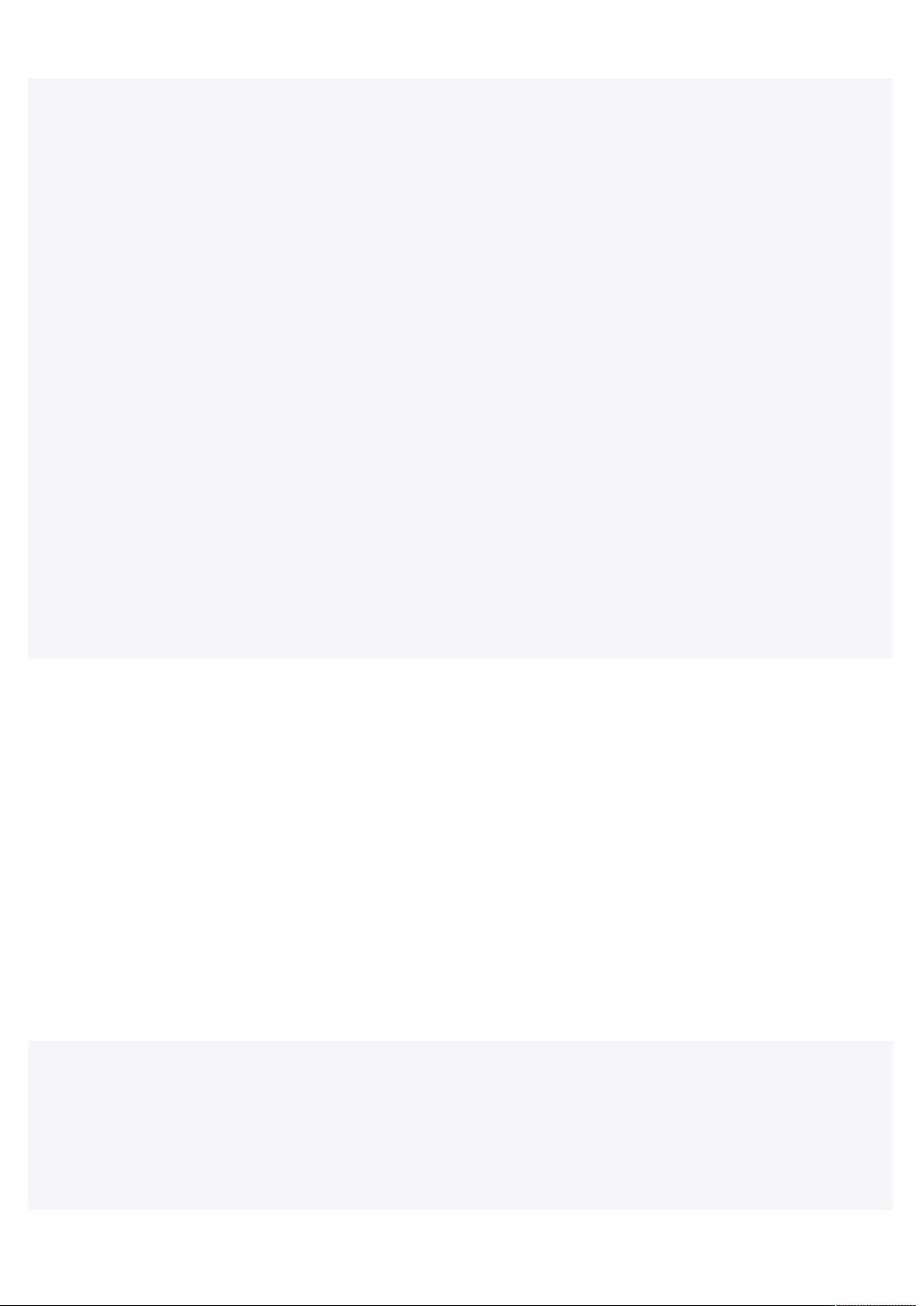
15 25558585=2,<
15 2555A85A85=2,?
15 255585A*85=2,BB
15 255585A*85=2,C?
15 255585A*85=2,C@
15 2555#D85#D85=2,E?
15 25558585=2,<
15 2555A85A85=2,?
15 2555FG+85FG+85=2,?@
15 25558585=2,<
15 2555A85A85=2,?
15 25558585=2,<
15 2555:85:85=2,<
15 25558585=2,<
15 2555A85A85=2,?
15 2555A85A85=2,?C
15 25558585=2,<
15 2555A85A85=2,?
15 25558585=2,<
15 2555:85:85=2,<
15 25558585=2,<
15 25555=2,E<
15 25555=2,B<
155=2,
下面给出 5 的代码,以便研究 是如何被调用的
111111*++H *+)I,% ;2% 5)!%%设置
了 34#2 的配置文件的路径
1111111H +")I,% ;2)!%%构建一个 scraper,第一个参数的作用是
配置了 Harvest 的配置文件,第二个参数设定了 Web-Harvest 的运行目录。
11111115G!
11111115!%%整个系统的运行都在这个方法里面了,可见这个方法的重要性。
11111111从上面对 方法的分析中,我们不难看出 这个类的重要性,下面我们来研究下 的
源代码。
Web-Harvest 学习笔记(三)
这一章,我们来学习 的源码。
首先,我们来看下 的构造函数,
*++" JG
11111115+H+!
11111115*+H *+!
11111115 JGH*95K JG!
11111115*$H #*$!
11111115H *!
11111115H+55!
剩余10页未读,继续阅读

hobertt
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


