MapReduce模型在日志分析的应用:用户兴趣点挖掘
88 浏览量
更新于2024-07-15
收藏 417KB PDF 举报
Reduce编程模型是大数据处理的一种重要方法,特别是在日志分析领域,它能有效地处理海量的数据,提取有价值的信息。MapReduce的核心思想是将复杂的大规模数据处理任务分解为一系列可并行执行的小任务,然后在分布式计算环境中高效执行。
Map阶段是数据处理的起点,它的主要任务是对原始数据进行预处理。在日志分析中,Map函数通常接收的是原始的日志文件,这些文件可能包含了用户的访问时间、访问页面、停留时间等信息。Map函数会将每一条日志分割成键值对,例如,可以将用户的IP地址作为键(key),用户的访问行为作为值(value)。这样,原始数据就被转换成了适合进一步处理的格式。
Reduce阶段则负责聚合和总结Map阶段产生的中间结果。在这个阶段,相同的键会被分发到同一个Reduce任务中,然后对与这个键关联的所有值进行处理。在日志分析的场景下,Reduce可能会统计每个IP地址访问特定页面的次数,或者找出最常访问的页面等。Reduce的结果是整个数据处理流程的输出,也是最终分析报告的基础。
在MapReduce中,处理特殊问题的技巧是必不可少的。例如,机器学习算法可以在MapReduce框架内用于用户行为预测或分类。通过Map阶段提取特征,Reduce阶段可以执行模型训练或预测。排序算法如归并排序或快速排序,可以在Reduce阶段应用,以确保相同键的值按照某种顺序排列。索引机制可以帮助快速定位和访问特定的数据,可以在Map阶段创建,以便于后续的查询和分析。连接机制,如基于键的连接,可以用于合并来自不同数据源的日志信息,比如将用户登录日志与浏览日志匹配,以获取更全面的用户行为视图。
日志分析的实例——用户兴趣点挖掘,是MapReduce在实践中的典型应用。在这一过程中,Map阶段会解析日志,识别用户的访问模式,例如,用户访问的网页类别、访问频率等。Reduce阶段则会汇总这些信息,找出用户的热点访问页面,形成用户的兴趣模型。这有助于公司了解用户的偏好,优化网站布局,或提供个性化推荐。
MapReduce通过其强大的分布式计算能力,为日志分析提供了强大的工具。无论是简单的统计分析,还是复杂的机器学习任务,都能在MapReduce模型中得到有效解决。通过本文的深入讲解,读者不仅能理解MapReduce的基本原理,还能掌握其在日志分析中的实际应用,进一步提升大数据处理的能力。
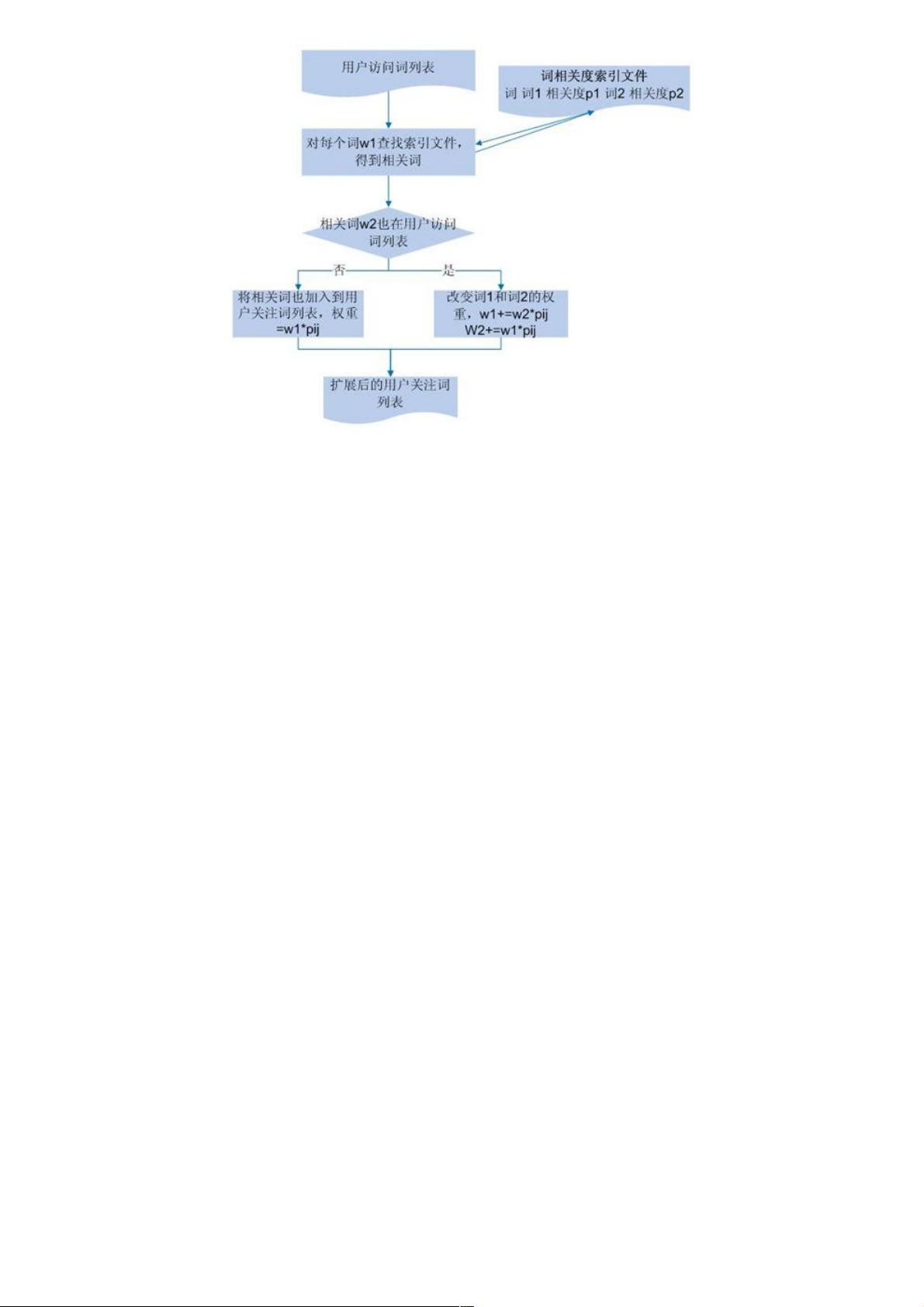
图 4 .用户访问关键词扩展流程图
图 4 描述了将词之间的相关度加入用户访问关键词列表中的流程:首先得到所有词对之间的相关度信息,并以索引形式存
储;然后,对之前得到的用户访问关键词列表中的每个词,查找索引得到相关的词,如果该词未被用户访问过,直接将其加入
到用户访问列表中;否则,对两个词的权重都需进行调整
关键词归约
与关键词扩展相对应的是关键词归约。用户访问的网页中挖掘出的关键词往往是具体的,比如用户关注的网页中提取出的词
是“足球”、“篮球”,而这些词在划分的时候都属于体育类,通过关键词归约,可以推测出该用户对”体育”比较感兴趣。
而分类标准应该如何获得呢?在各大门户网站如新浪、网易的首页,都有诸如天气、新闻、教育、军事等各大类,在每一大类
里又有各小类;在淘宝、易趣等网上交易平台,更是有对商品的多级详细分类。关键词归约,就是根据用户访问的关键词追溯
到用户对哪些类别的内容感兴趣。
无论是关键词扩展还是归约,都会得到更加精确的用户访问关键词列表,对所有词按权重由大到小进行排列,描述的即是用户
的兴趣点。
MapReduce 对用户兴趣挖掘的实现
上一部分介绍了用户兴趣点挖掘的流程,本部分将针对各个模块进行 MapReduce 的实现。整个应用的输入是用户访问网页记
录组成的文件,文件每行表示用户访问网页的一条记录,形为:
“用户 URL”。期望输出为用户的兴趣点文件,文件每行存储每个用户的兴趣点,形为:
“用户 词 1 权重 1 词 2 权重 2 词 3 权重 3 ”。
下面会对三个步骤分别讲解 MapReduce 实现。
单一网页信息挖掘
单一网页信息挖掘的目的是选取出网页中相对重要的关键词。策略为每个词赋予权重,并选取权重较大的词。词的权重获取公
式 v = sum(vi*fi) 由两部分决定:该词在每个特征上的取值和该特征的权重。
每个特征的权重,可由训练得到,输入为给出关键词的系列网页。特征权重训练通常有特定的算法,比如 SCGIS 算法,因为
训练集相对于整体的输入集较小,而算法通常也较复杂,并不适合并行化,可在 MapReduce 任务开始之前进行特征权重训
练。
而词在每个特征维度上对应的取值,视特征的不同,难易程度也不同。比如词的出现位置、大小写、词性等,在对网页进行扫
描时,可以立即获得。而 TF( 词在网页中出现的次数 )、DF(词在所有网页中出现的次数)等特征并不能随词出现时立即获
取,但由于每个词处理的程序都相同,所以可以使用 MapReduce 编程模型并行化。下面进行具体讲述。
单一网页信息挖掘部分的 MapReduce 流程如图 5 所示。
剩余15页未读,继续阅读
点击了解资源详情
点击了解资源详情
248 浏览量
132 浏览量
390 浏览量
184 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38599412
- 粉丝: 6
- 资源: 930
 我的内容管理
展开
我的内容管理
展开







最新资源
- Oracle8i_9i数据库基础.doc
- 修改主机名后em不能启动解决方法.doc
- c++ 连接sql2000 实例
- Pattern-Oriented Software Architecture, Patterns for Concurrent and Networked Objects, Volume 2
- 09版三级网络技术上级100题
- 软件设计师历年考题分布情况
- 新手起步:perl入门
- Spss For Windows 實用教學
- 单片机复位电路的可靠性设计
- matlab数理统计工具箱
- COM Programming by Example
- 代码大全 (code complete) 绝世经典 外文原版
- 关于随机码的事件问题
- 关于java上传的问题
- JSP网页编程.ppt
- PDM资料-------------
