MapReduce模型在日志分析中的应用实践
57 浏览量
更新于2024-07-15
收藏 417KB PDF 举报
"MapReduce编程模型在日志分析方面的应用"
MapReduce编程模型是处理大规模数据的一种有效方法,尤其适用于日志分析这样的大数据处理任务。在日志分析中,MapReduce模型能够帮助我们从海量的访问日志中提取有价值的信息,例如用户行为模式、兴趣点挖掘等,这些信息对商业智能和决策支持至关重要。
MapReduce的核心思想是将复杂的数据处理任务分解为两个主要阶段:Map阶段和Reduce阶段。Map阶段负责数据的预处理,将原始数据分割成键值对,并分配到集群的不同节点上进行并行处理。Reduce阶段则负责对Map阶段生成的中间结果进行聚合和总结,生成最终的结果。
在用户访问日志分析的例子中,Map阶段可能需要解析每个日志条目,提取关键信息,如用户ID、访问页面、访问时间等,然后将这些信息转化为键值对。例如,键可以是用户ID,值则包含该用户的访问详情。这个过程通常涉及字符串解析、正则表达式匹配等技术。
Reduce阶段则根据Map阶段生成的键值对进行聚合,例如,如果要找出每个用户的热门访问页面,Reduce函数可以对相同用户ID的页面访问记录进行汇总,统计出每个页面被访问的次数。这个阶段可以实现排序、统计、聚类等操作,进一步提炼出用户的行为特征。
在MapReduce编程中,还需要考虑一些特殊问题的处理,例如:
1. **机器学习算法**:在日志分析中,可能需要运用机器学习来预测用户行为或进行分类。Map阶段可以用来预处理数据,Reduce阶段则可以执行模型训练或预测。
2. **排序算法**:MapReduce支持基于键的排序,这对于诸如时间序列分析、Top-N查询等场景非常有用。Reduce任务接收的是已排序的键值对,可以高效地处理这些问题。
3. **索引机制**:虽然MapReduce本身不直接支持索引,但可以通过在Map阶段生成临时索引来加速特定查询,如快速查找特定用户的所有记录。
4. **连接机制**:在处理多源数据时,可以使用Shuffle阶段的分区和排序特性实现不同数据源之间的连接操作。
MapReduce模型的实现通常基于Hadoop框架,它提供了完善的容错机制和可扩展性,能够处理PB级别的数据。然而,随着数据规模的增长和需求的复杂化,出现了诸如Spark、Flink等更高效的计算框架,它们在某些场景下可以提供比MapReduce更快的计算速度和更低的延迟。
MapReduce编程模型在日志分析中的应用展示了其在处理大规模数据的强大能力,通过对日志的深入分析,我们可以洞察用户行为,优化业务策略,甚至预测未来趋势,从而提升企业的竞争力。通过学习和掌握MapReduce,开发者能够更好地应对大数据时代带来的挑战。
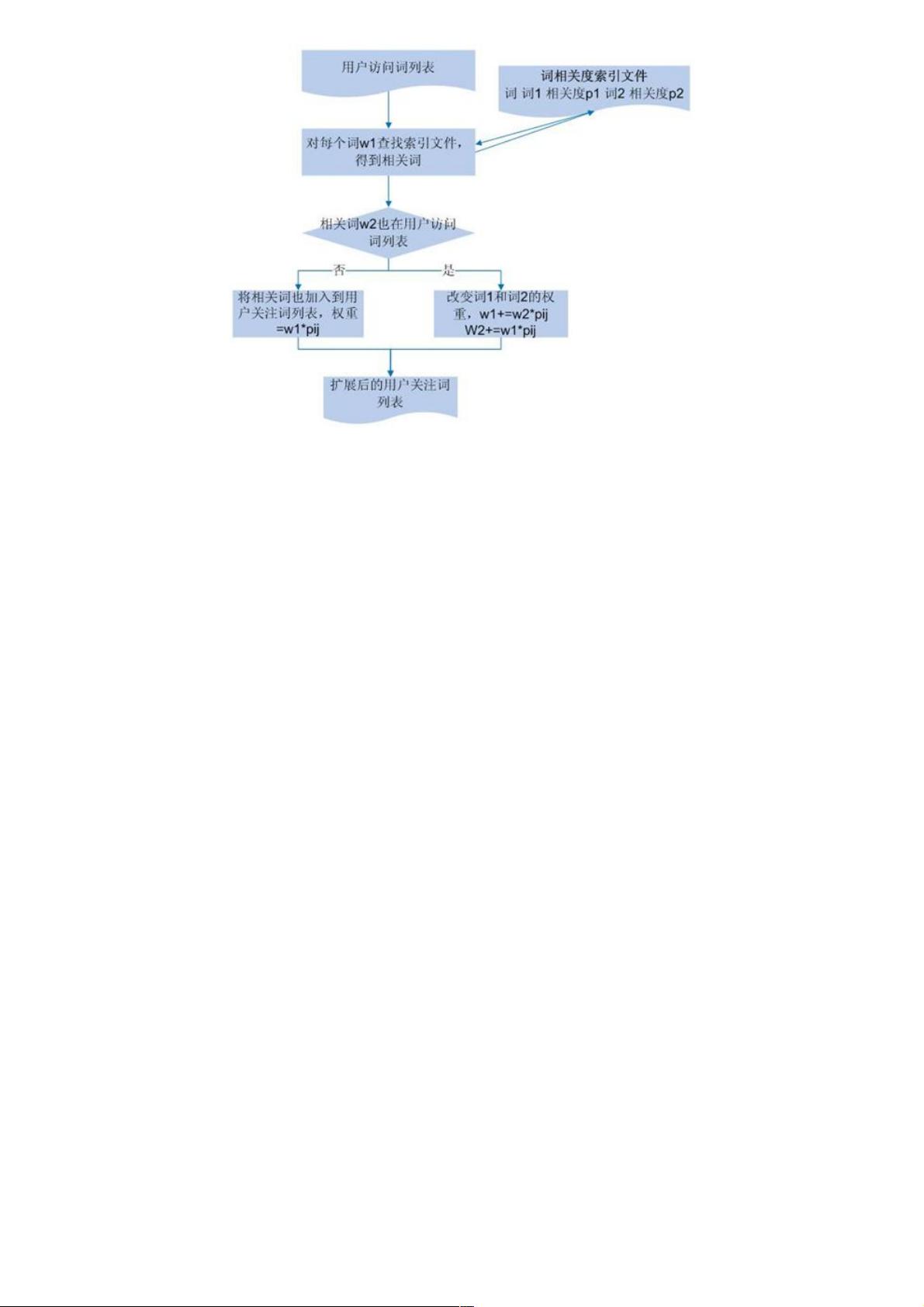
图 4 .用户访问关键词扩展流程图
图 4 描述了将词之间的相关度加入用户访问关键词列表中的流程:首先得到所有词对之间的相关度信息,并以索引形式存
储;然后,对之前得到的用户访问关键词列表中的每个词,查找索引得到相关的词,如果该词未被用户访问过,直接将其加入
到用户访问列表中;否则,对两个词的权重都需进行调整
关键词归约
与关键词扩展相对应的是关键词归约。用户访问的网页中挖掘出的关键词往往是具体的,比如用户关注的网页中提取出的词
是“足球”、“篮球”,而这些词在划分的时候都属于体育类,通过关键词归约,可以推测出该用户对”体育”比较感兴趣。
而分类标准应该如何获得呢?在各大门户网站如新浪、网易的首页,都有诸如天气、新闻、教育、军事等各大类,在每一大类
里又有各小类;在淘宝、易趣等网上交易平台,更是有对商品的多级详细分类。关键词归约,就是根据用户访问的关键词追溯
到用户对哪些类别的内容感兴趣。
无论是关键词扩展还是归约,都会得到更加精确的用户访问关键词列表,对所有词按权重由大到小进行排列,描述的即是用户
的兴趣点。
MapReduce 对用户兴趣挖掘的实现
上一部分介绍了用户兴趣点挖掘的流程,本部分将针对各个模块进行 MapReduce 的实现。整个应用的输入是用户访问网页记
录组成的文件,文件每行表示用户访问网页的一条记录,形为:
“用户 URL”。期望输出为用户的兴趣点文件,文件每行存储每个用户的兴趣点,形为:
“用户 词 1 权重 1 词 2 权重 2 词 3 权重 3 ”。
下面会对三个步骤分别讲解 MapReduce 实现。
单一网页信息挖掘
单一网页信息挖掘的目的是选取出网页中相对重要的关键词。策略为每个词赋予权重,并选取权重较大的词。词的权重获取公
式 v = sum(vi*fi) 由两部分决定:该词在每个特征上的取值和该特征的权重。
每个特征的权重,可由训练得到,输入为给出关键词的系列网页。特征权重训练通常有特定的算法,比如 SCGIS 算法,因为
训练集相对于整体的输入集较小,而算法通常也较复杂,并不适合并行化,可在 MapReduce 任务开始之前进行特征权重训
练。
而词在每个特征维度上对应的取值,视特征的不同,难易程度也不同。比如词的出现位置、大小写、词性等,在对网页进行扫
描时,可以立即获得。而 TF( 词在网页中出现的次数 )、DF(词在所有网页中出现的次数)等特征并不能随词出现时立即获
取,但由于每个词处理的程序都相同,所以可以使用 MapReduce 编程模型并行化。下面进行具体讲述。
单一网页信息挖掘部分的 MapReduce 流程如图 5 所示。
剩余15页未读,继续阅读
394 浏览量
2030 浏览量
点击了解资源详情
240 浏览量
133 浏览量
点击了解资源详情
184 浏览量
点击了解资源详情
点击了解资源详情

weixin_38743481
- 粉丝: 698
- 资源: 4万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- n26aas:n26api即服务
- 酒店保安部年终总结下载
- PHP Pro Bid v5
- Morf-开源
- pandas-gbq-0.2.0.tar.gz
- Autonomous_Guidance_MPC_and_LQR-LMI:自动驾驶汽车的运动学MPC和动态LPV-LQR状态反馈控制
- angular-element-example:使用angular元素创建自定义元素的示例
- nike-shop-practice
- Wallpaper Engine v1.3.141.zip
- hop:HbbTV开放平台-用于创建快速和优化的HbbTV应用程序的TypeScript平台
- OpenAI的代码解释器:open-interpreter
- 值勤细则DOC
- NU454-高级建模技术
- MobileERP
- tech-alchemy-assignment
- 软件开发项目(附评标办法及标准)).rar
