
Definition 1. Let X
0
be the pruned version of X as in
X
0
¼ X n
v
i
j
v
i
2 V; degreeð
v
i
Þ¼1
fg
; ð1Þ
where degree(
v
i
) denotes the degree of vertex
v
i
in the MST of X.
2.3.2. Constructing a 3-MST graph
An MST describes the intrinsic skeleton of a dataset and accordingly can be used for clustering. In our proposed method, we
use it to guide the splitting and merging processes. However, a single MST loses some neighborhood information that is crucial
for splitting and merging. To overcome this drawback, we combine several MSTs and form a graph G
mst
(X,k) as follows:
Definition 2. Let T
1
= f
mst
(V,E) denote the MST of G(X)=(V,E). The following iterations of an MST are defined as:
T
i
¼ f
mst
V; E n[
i1
j¼1
T
j
; ð2Þ
where f
mst
:(V,E) ? T is a function to compute an MST from graph G(X)=(V, E), and i P 2.
In theory, the above definition of T
i
is not rigorous because E n[
i1
j¼1
T
j
may produce isolated subgraph. For example, if there
exists a vertex
v
in T
1
and the degree of
v
is jVj1,
v
will be isolated in G(V,EnT
1
). Hence, the second MST (T
2
) cannot be
completed in terms of Definition 2. In practice, this is not a problem because the first MST T
1
is still connected and we
can simply ignore it as a minor artefact, because it has no noticeably effect on the performance of the overall algorithm. How-
ever, for the sake of completeness, we solve this minor problem by always connecting such an isolated subgraph with an
edge randomly selected from those connecting the isolated subgraph in T
1
.
Let G
mst
(X,k) denote the k-MST graph, which is defined as a union of the k MSTs: G
mst
(X,k)=T
1
[ T
2
[[T
k
. In this paper,
we use G
mst
(X
0
,k) to determine the initial prototypes in the split stage and to calculate the merge index of a neighboring par-
tition pair in the merge stage. Here, k is set to 3 in terms of the following observation: 1 round of MST is not sufficient for the
criterion-based merge but 3 iterations are. The number itself is a small constant and can be justified from computational
point of view. Additional iterations do not add much to the quality, but only increase processing time. A further discussion
concerning the selection of k can be found in Section 3.4.
2.4. Split stage
In the split stage, initial prototypes are selected as the nodes of highest degree in the graph G
mst
(X
0
,k). K-means is then
applied to the pruned dataset using these prototypes. The produced partitions are adjusted to keep the clusters connected
with respect to the MST.
2.4.1. Application of K-means
The pruned dataset is first split by K-means in the original Euclidean space, where the number of partitions K
0
is set to
ffiffiffiffiffiffiffi
jX
0
j
p
. This is done under the assumption that the number of clusters in a dataset is smaller than the square root of the num-
ber of patterns in the dataset [3,36].If
ffiffiffiffiffiffiffi
jX
0
j
p
6 K, K
0
can be set to K + k(jX
0
jK) to grantee that K
0
is greater than K, where
0<k < 1. Since this is not a normal situation, we do not discuss the parameter k in this paper. Moreover, if jX
0
j 6 K, the split-
and-merge scheme will degenerate into a traditional agglomerative clustering.
However, to determine the K
0
initial prototypes is a tough problem, and a random selection would give an unstable split-
ting result. For example, the method proposed in [30] uses K-means with randomly selected prototypes in its split stage, and
the final clustering results are not unique. We therefore utilize the MST-based graph G
mst
(X
0
,3) to avoid this problem.
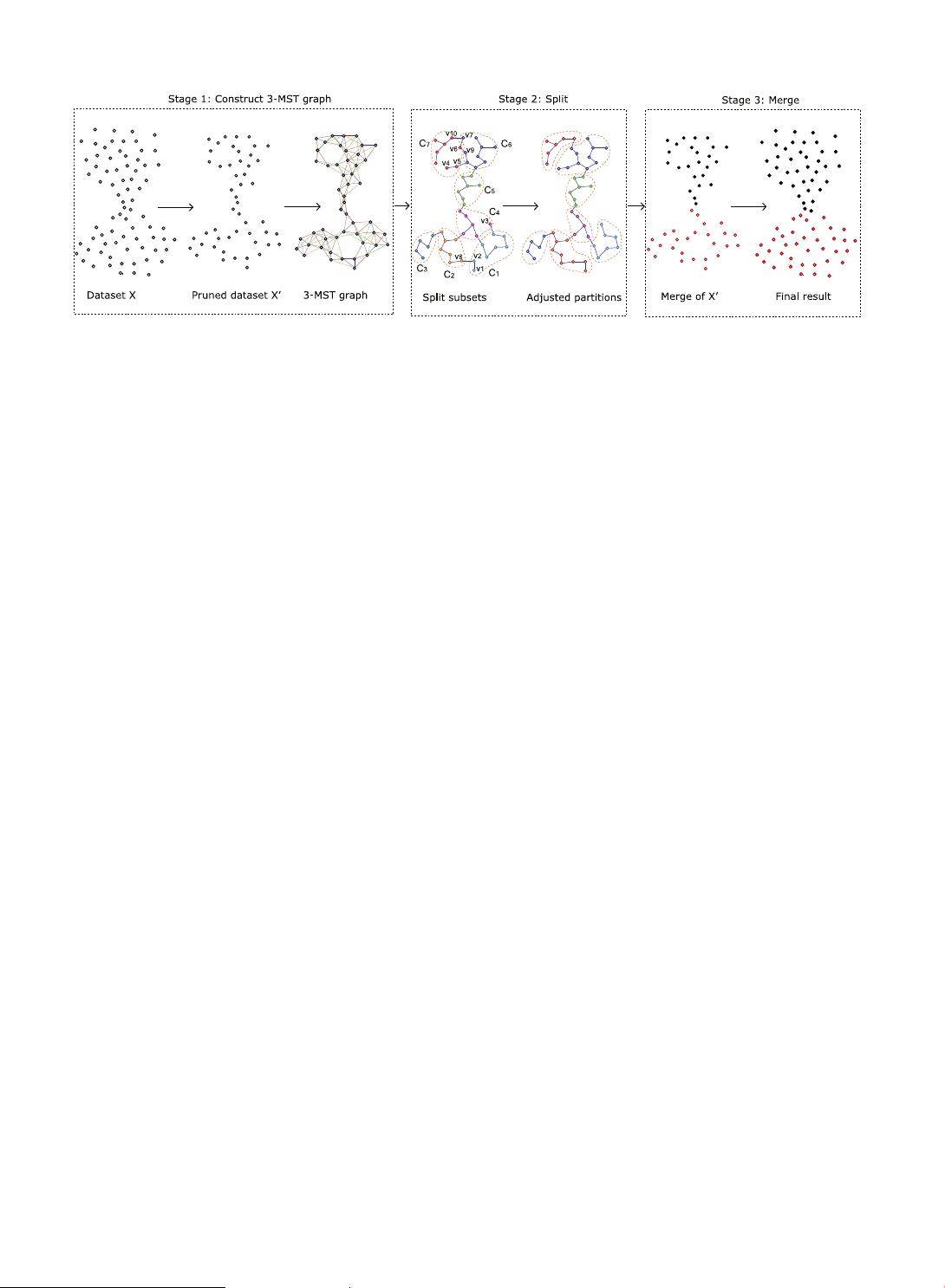
Fig. 1. The overview of split-and-merge. In Stage 1, the dataset X is pruned into X
0
according to the MST of X, and three iterations of MSTs of X
0
are computed
and combined into a 3-MST graph. In Stage 2, X
0
is partitioned by K-means, where the initial prototypes are generated from the 3-MST graph. The partitions
are then adjusted so that each partition is a subtree of the MST of X
0
. In Stage 3, the partitions are merged into the desired number of clusters and the pruned
data points are distributed to the clusters.
C. Zhong et al. / Information Sciences 181 (2011) 3397–3410
3399
剩余13页未读,继续阅读

weixin_38669729
- 粉丝: 7
- 资源: 908
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++标准程序库:权威指南
- Java解惑:奇数判断误区与改进方法
- C++编程必读:20种设计模式详解与实战
- LM3S8962微控制器数据手册
- 51单片机C语言实战教程:从入门到精通
- Spring3.0权威指南:JavaEE6实战
- Win32多线程程序设计详解
- Lucene2.9.1开发全攻略:从环境配置到索引创建
- 内存虚拟硬盘技术:提升电脑速度的秘密武器
- Java操作数据库:保存与显示图片到数据库及页面
- ISO14001:2004环境管理体系要求详解
- ShopExV4.8二次开发详解
- 企业形象与产品推广一站式网站建设技术方案揭秘
- Shopex二次开发:触发器与控制器重定向技术详解
- FPGA开发实战指南:创新设计与进阶技巧
- ShopExV4.8二次开发入门:解决升级问题与功能扩展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


