Apache Hadoop YARN:资源调度器的革新
需积分: 10 148 浏览量
更新于2024-07-23
收藏 801KB PDF 举报
"Apache Hadoop YARN:一种新的资源协调者,旨在解决Hadoop初始设计中的局限性,特别是针对编程模型与资源管理的紧密耦合以及调度器的扩展性问题。YARN通过分离资源管理和应用程序控制流程,实现了更高效、灵活的大数据处理框架。"
在大数据处理领域,Apache Hadoop是一个广泛使用的开源框架,最初的设计主要针对大规模的MapReduce作业,以处理网络爬取数据。随着时间的推移,Hadoop逐渐被各种不同的公司采纳,成为数据和计算资源的共享平台。然而,这种广泛的应用也暴露出Hadoop初始设计的一些问题:
1. **编程模型与资源管理的紧密耦合**:Hadoop最初的架构将MapReduce编程模型深度集成到资源管理系统中,这使得开发者在处理非MapReduce任务时必须强行适应这个模型,限制了框架的灵活性。
2. **调度器的扩展性问题**:所有作业的控制流集中在一个调度器中处理,这导致了随着作业数量增加,调度器的可扩展性成为一个严重瓶颈,影响整体性能和效率。
为了解决这些问题,Apache社区提出了Hadoop YARN(Yet Another Resource Negotiator),这是一个全新的资源调度系统。YARN的主要目标是将资源管理和应用程序的执行逻辑分离,从而实现更高效和可扩展的框架:
- **资源管理分离**:YARN引入了一个全局的ResourceManager组件,负责集群资源的分配和监控,而每个应用程序有自己独立的ApplicationMaster,负责协调应用程序的执行和资源请求。这种分离让资源管理更加集中和高效,同时也允许不同的编程模型共存。
- **应用程序控制流的分散**:ApplicationMaster负责单个应用程序的生命周期管理,包括任务分配、监控和故障恢复。这样,调度器只需要关注资源分配,而无需处理每个作业的具体控制逻辑,极大地提高了系统的可扩展性。
- **多租户支持**:YARN允许多个用户和应用程序同时运行,确保资源公平分配,满足不同工作负载的需求。
- **优化的资源利用率**:通过更精细的资源粒度管理和动态调整,YARN能够更好地利用集群资源,减少空闲和浪费。
- **更好的安全性**:YARN提供了增强的安全机制,如认证、授权和审计,以保护数据和计算资源的安全。
YARN的出现极大地推动了Hadoop生态系统的发展,使其能够支持更多类型的工作负载,如交互式查询(如Hive、Pig)、实时流处理(如Storm、Spark)等。此外,YARN也为未来的大数据处理框架提供了更强大的基础设施,促进了大数据处理技术的创新和进步。
总结来说,Hadoop YARN是一个革命性的改进,它重新定义了Hadoop作为一个通用的数据处理平台,通过分离资源管理和应用逻辑,解决了早期Hadoop面临的关键挑战,提升了整个系统的灵活性、可扩展性和资源利用率。
gorithms are better expressed using a bulk-synchronous
parallel model (BSP) using message passing to com-
municate between vertices, rather than the heavy, all-
to-all communication barrier in a fault-tolerant, large-
scale MapReduce job [22]. This mismatch became an
impediment to users’ productivity, but the MapReduce-
centric resource model in Hadoop admitted no compet-
ing application model. Hadoop’s wide deployment in-
side Yahoo! and the gravity of its data pipelines made
these tensions irreconcilable. Undeterred, users would
write “MapReduce” programs that would spawn alter-
native frameworks. To the scheduler they appeared as
map-only jobs with radically different resource curves,
thwarting the assumptions built into to the platform and
causing poor utilization, potential deadlocks, and insta-
bility. YARN must declare a truce with its users, and pro-
vide explicit [R8:] Support for Programming Model
Diversity.
Beyond their mismatch with emerging framework re-
quirements, typed slots also harm utilization. While the
separation between map and reduce capacity prevents
deadlocks, it can also bottleneck resources. In Hadoop,
the overlap between the two stages is configured by the
user for each submitted job; starting reduce tasks later
increases cluster throughput, while starting them early
in a job’s execution reduces its latency.
3
The number of
map and reduce slots are fixed by the cluster operator,
so fallow map capacity can’t be used to spawn reduce
tasks and vice versa.
4
Because the two task types com-
plete at different rates, no configuration will be perfectly
balanced; when either slot type becomes saturated, the
JobTracker may be required to apply backpressure to job
initialization, creating a classic pipeline bubble. Fungi-
ble resources complicate scheduling, but they also em-
power the allocator to pack the cluster more tightly.
This highlights the need for a [R9:] Flexible Resource
Model.
While the move to shared clusters improved utiliza-
tion and locality compared to HoD, it also brought con-
cerns for serviceability and availability into sharp re-
lief. Deploying a new version of Apache Hadoop in a
shared cluster was a carefully choreographed, and a re-
grettably common event. To fix a bug in the MapReduce
implementation, operators would necessarily schedule
downtime, shut down the cluster, deploy the new bits,
validate the upgrade, then admit new jobs. By conflat-
ing the platform responsible for arbitrating resource us-
age with the framework expressing that program, one
is forced to evolve them simultaneously; when opera-
tors improve the allocation efficiency of the platform,
3
This oversimplifies significantly, particularly in clusters of unreli-
able nodes, but it is generally true.
4
Some users even optimized their jobs to favor either map or reduce
tasks based on shifting demand in the cluster [28].
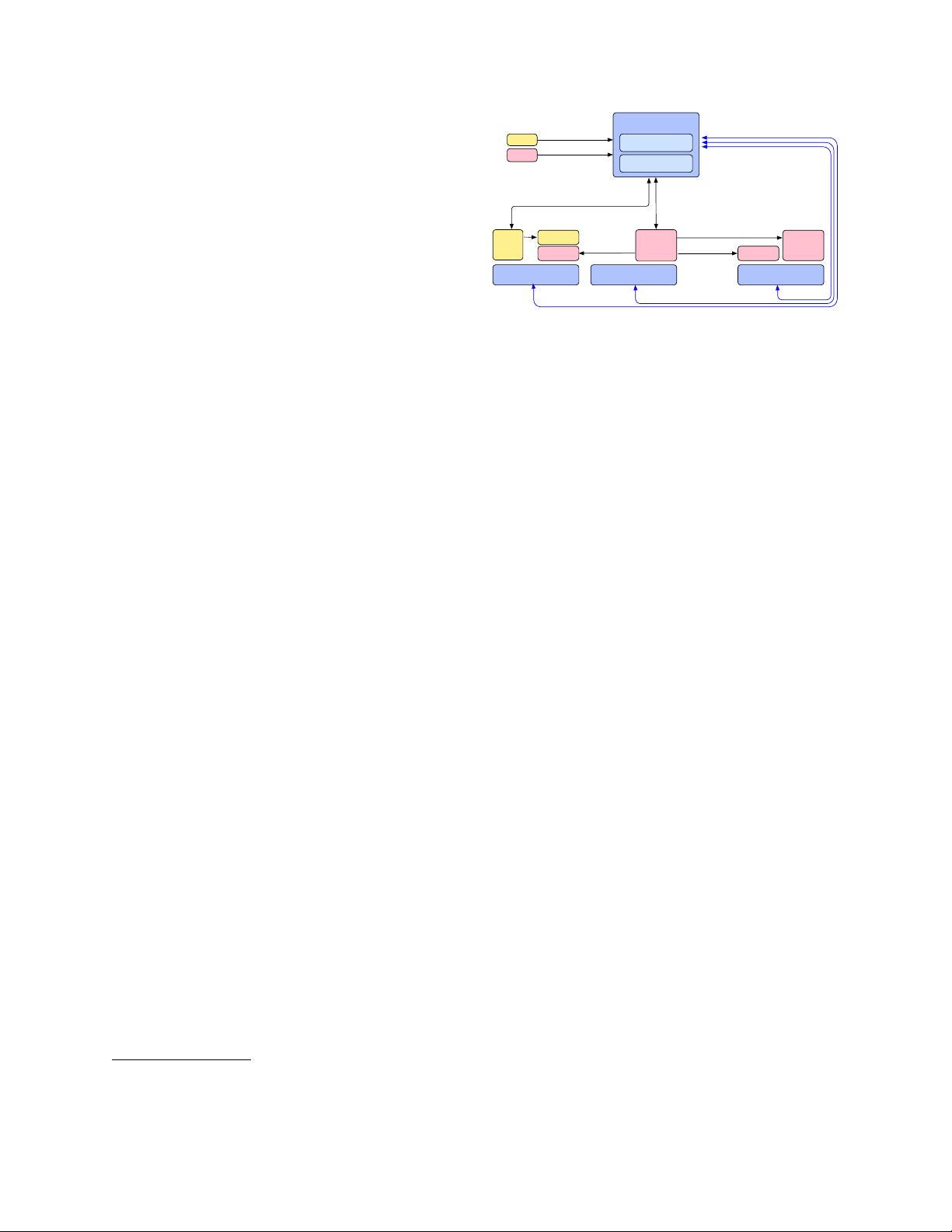
Node ManagerNode Manager Node Manager
ResourceManager
Scheduler
AMService
MR
AM
Container
Container
Container
MPI
AM
..
.
Container
RM -- NodeManager
RM -- AM
Umbilical
client
client
Client -- RM
Figure 1: YARN Architecture (in blue the system components,
and in yellow and pink two applications running.)
users must necessarily incorporate framework changes.
Thus, upgrading a cluster requires users to halt, vali-
date, and restore their pipelines for orthogonal changes.
While updates typically required no more than re-
compilation, users’ assumptions about internal frame-
work details—or developers’ assumptions about users’
programs—occasionally created blocking incompatibil-
ities on pipelines running on the grid.
Building on lessons learned by evolving Apache Ha-
doop MapReduce, YARN was designed to address re-
quirements (R1-R9). However, the massive install base
of MapReduce applications, the ecosystem of related
projects, well-worn deployment practice, and a tight
schedule would not tolerate a radical redesign. To avoid
the trap of a “second system syndrome” [6], the new ar-
chitecture reused as much code from the existing frame-
work as possible, behaved in familiar patterns, and left
many speculative features on the drawing board. This
lead to the final requirement for the YARN redesign:
[R10:] Backward compatibility.
In the remainder of this paper, we provide a descrip-
tion of YARN’s architecture (Sec. 3), we report about
real-world adoption of YARN (Sec. 4), provide experi-
mental evidence validating some of the key architectural
choices (Sec. 5) and conclude by comparing YARN with
some related work (Sec. 6).
3 Architecture
To address the requirements we discussed in Section 2,
YARN lifts some functions into a platform layer respon-
sible for resource management, leaving coordination of
logical execution plans to a host of framework imple-
mentations. Specifically, a per-cluster ResourceManager
(RM) tracks resource usage and node liveness, enforces
allocation invariants, and arbitrates contention among
tenants. By separating these duties in the JobTracker’s
charter, the central allocator can use an abstract descrip-
tion of tenants’ requirements, but remain ignorant of the
剩余15页未读,继续阅读
204 浏览量
2018-11-16 上传
2020-09-23 上传
2023-05-15 上传
2023-10-23 上传
2014-06-17 上传
2018-04-30 上传
2021-07-16 上传










