华为工程师解析HBase二级索引实现与挑战
"华为的工程师分享的关于HBase二级索引的实现资料,详细介绍了HBase二级索引的原理和注意事项,同时涵盖了华为在Hadoop开发中的贡献和HBase的基础知识回顾。"
在HBase中,一级索引是默认提供的,基于行键(Row Key)的排序存储方式。然而,对于复杂的查询需求,如基于列值(Column Value)的条件扫描,一级索引的效率并不理想。这就是二级索引的引入原因。二级索引是一种用户自定义的索引,允许快速访问数据而不必全表扫描。
二级索引在HBase中的实现通常涉及以下步骤:
1. **创建索引表**:二级索引需要创建一个额外的索引表,这个表存储了原表中某个列族的列值与行键的映射关系。这样,当我们需要根据该列值进行查询时,可以通过索引表快速定位到对应的行。
2. **索引更新**:每当原表中的数据发生变化,二级索引表也需要同步更新。这意味着在数据写入时,不仅需要更新主表,还需要更新对应的索引表,增加了写操作的复杂性。
3. **查询优化**:通过二级索引查询时,首先在索引表中查找匹配的行键,然后使用这些行键在原表中读取数据。这减少了扫描整个表的开销,尤其是在处理大量稀疏数据时。
4. **注意问题**:实现二级索引时,需要考虑数据一致性问题。由于更新操作需要同时维护两份数据,可能存在短暂的数据不一致。此外,索引表的维护会增加系统的存储和计算负担,需要合理设计索引策略以平衡查询性能和系统资源。
除了二级索引,资料还提及了华为在Hadoop领域的其他贡献,如HDFS NameNode HA(高可用性)在Hadoop-1和Hadoop-2中的实现,MapReduce的ResourceManager HA,以及Hive的高可用性方案。这些内容展示了华为在大数据处理和分布式系统稳定性方面的努力。
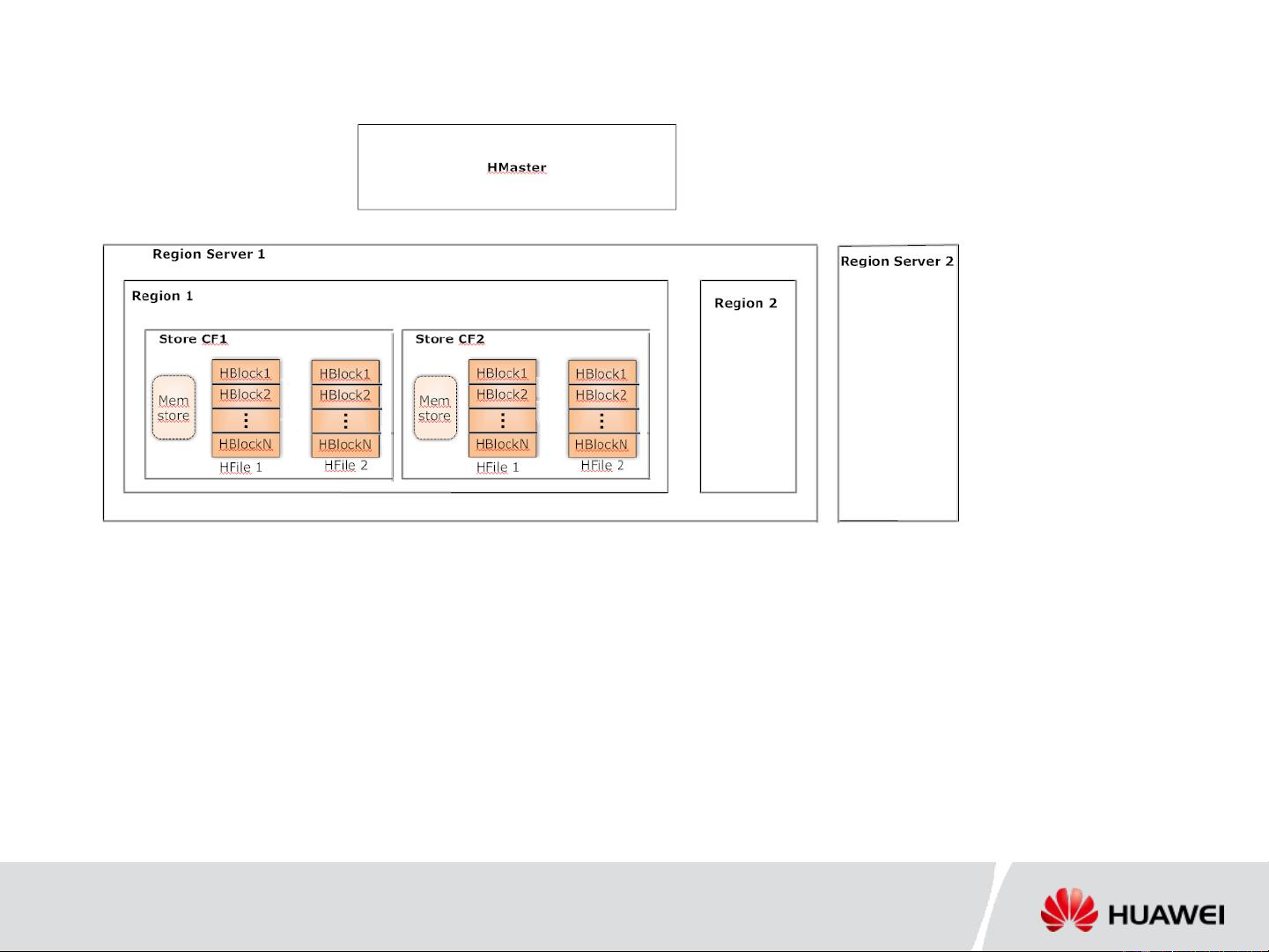
总结HBase的基础知识,HBase是一个分布式的、基于列族的NoSQL数据库,它将大表分割成多个区域(Regions),每个区域由一个Region Server管理。数据以列式存储,每个区域内的数据按照行键排序。内存中的数据存储在Memstore中,当达到一定阈值时,会刷入HDFS成为HFile。HFile逻辑上被划分为块,数据以块为单位进行读写,提高了读取效率。
这份资料提供了对HBase二级索引实现的深入理解,对于那些希望优化HBase查询性能、处理大规模数据的开发者来说,是一份宝贵的参考资料。同时,它也揭示了华为在Hadoop生态中的角色和技术实力。
HUAWEI TECHNOLOGIES CO., LTD.
Slide title :32-35pt
Color: R153 G0 B0
Corporate Font :
FrutigerNext LT Medium
Font to be used by customers
and
partners :
Arial
Slide text :20-22pt
Bullets level 2-5:
18pt
Color:Black
Corporate Font :
FrutigerNext LT Medium
Font to be used by customers
and
partners :
Arial
Top right corner
for field-mark,
customer or partner
logotypes.
----------------
The following nine
groups of colors
are an example of
how our design
colors can be used,
please take note
that you should
only use one
design color group
per slide.
For specific usage
details, refer to the
“Typesetting
Standard”.
Master, Region servers
Table split into regions
Columnar storage, Column family
Memstore, Hfiles in DFS
Hfiles logically split into smaller blocks, data write/read as blocks
HBase Recap
Page 4
剩余17页未读,继续阅读
2018-04-12 上传
2018-01-22 上传
2021-01-07 上传
2023-05-09 上传
2023-06-06 上传
2023-10-18 上传
2023-05-25 上传
2024-06-28 上传
2023-03-05 上传

大神带我来搬砖
- 粉丝: 5
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
