铅卤化物钙钛矿纳米晶的掺杂研究综述:结构、电子、光学与LED的发展
33 浏览量
更新于2024-07-15
收藏 3.46MB PDF 举报
"A comprehensive review of doping in perovskite nanocrystals/quantum dots: evolution of structure, electronics, optics and light-emitting diodes"
这篇研究论文深入探讨了铅卤化物过氧化物纳米晶体(LHP NCs)/量子点(QDs)中的掺杂现象,特别是它们在光发射二极管(LEDs)应用中的结构演变、电子性质、光学性能以及电致发光性能。过氧化物纳米晶体因其直接带隙、窄带宽、可调带隙、长载流子扩散长度和高载流子迁移率等特点,在LED领域取得了显著的发展。掺杂技术被用来调控ABX3过氧化物的晶格结构、电子结构、发光特性、辐射复合动力学和电学性质。
论文首先介绍了掺杂对过氧化物纳米晶体结构的影响。掺杂离子可以改变晶体的晶体结构,如通过引入特定的阳离子或阴离子,可以调整晶格参数,从而影响纳米晶体的形貌和尺寸分布。这种结构调控对于优化材料的光学和电学性能至关重要。
接着,论文讨论了掺杂如何影响过氧化物的电子性质。掺杂可以引入新的能级,改变材料的导电类型(n型或p型),这对于构建高效能的光电设备至关重要。例如,通过掺杂阳离子可以调整电子亲和力,而掺杂阴离子则可能改变带隙宽度,从而优化电子和空穴的重组效率。
在光学性能方面,掺杂可以调节纳米晶体的光发射特性。通过改变内转换和辐射复合过程,掺杂可以改善量子产率,减少非辐射损耗,提高光亮度。此外,掺杂还可以实现颜色的精细调控,这对于全色域显示和照明应用具有重要意义。
论文还关注了掺杂在过氧化物LEDs中的应用。通过掺杂,可以提升器件的电致发光效率,降低电压驱动,增强稳定性,并有可能解决过氧化物LEDs中的一些关键问题,如效率衰退和器件寿命。
这篇论文提供了一个全面的视角,展示了掺杂在过氧化物纳米晶体和量子点中的重要作用,涵盖了从基础的物理化学原理到实际应用的各个方面。通过对这些领域的深入理解,科研人员能够更好地设计和优化基于过氧化物的新型光电设备,推动该领域的发展。
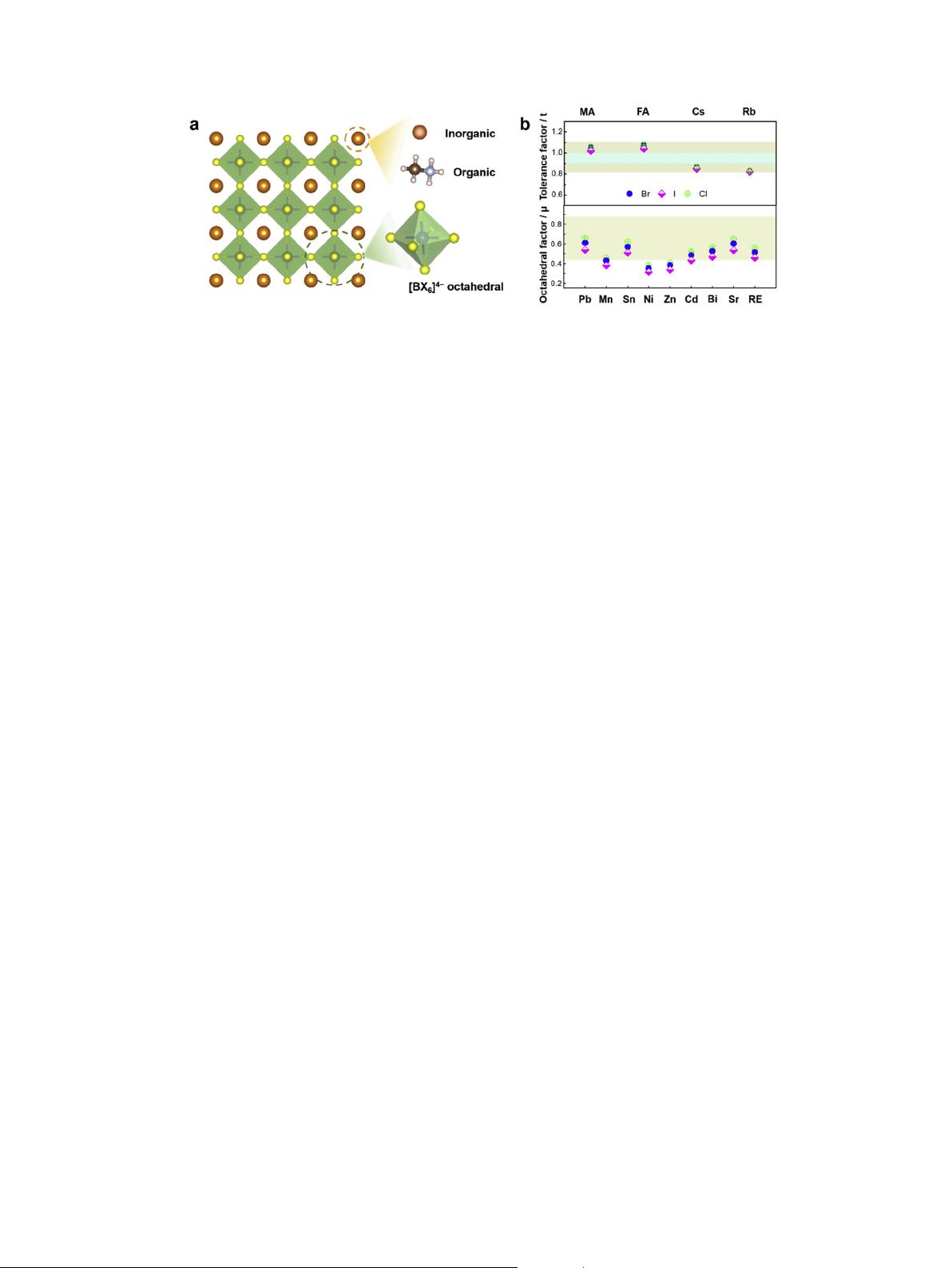
the 3D perovskite framework and solve above problems, which we
will discuss later.
Besides tolerance factor t, the octahedral factor
m
, which is
additional semiempirical geometric parameter, is used to evaluate
the octahedral stability [83]. The
m
is defined as
m
¼ r
B
=r
X
(2)
The range of
m
between 0.442 and 0.895 would be beneficial for
the stable [BX
6
]
4-
octahedral. We compile the
m
value of B-site and
doping B-site (applied in perovskite NCs)erelated octahedron in
Fig. 2b. The choice of B-site cation not only has to satisfy the range
of tolerance factor t but also needs to meet the requirements of
octahedral factor
m
. Although a fair amount of efforts has been
made to explore the substitution of Pb, few fungible B-site cations
are available for 3D LHP structures. Apart from the structure sta-
bility, the luminescence characteristics and electronic structure
change a lot owing to the alteration of B-site cations [84e89].Upto
now, lead-free perovskites have not exhibited satisfactory proper-
ties. On the contrary, incorporation of a small of dopants would not
alter the basic characteristics of host LHPs but could remarkably
improve their stability or optical properties. Over the past years,
various metal ions, including Sn
2þ
,Bi
3þ
,Mn
2þ
, and RE ions (e.g.,
Ce
3þ
,Tb
3þ
,Eu
3þ
), have been doped into halide perovskites, and a
broad range of exotic properties have been imparted to this
prominent materials [67,90].
The unsteadiness of phase structure is severer in the I-based
perovskite than in the Br-based and Cl-based perovskite. It is
known that
a
-APbI
3
(cubic) is desirable for superior applications in
light absorption, luminescence, and optoelectronic devices. How-
ever, APbI
3
(with monotypic A-site cation, such as FA, MA or Cs) is
more stable in
d
phase that exhibits hexagonal for larger tolerance
factor (FA) and orthorhombic for small tolerance factor (Cs) [41,42].
Fig. 3a presents the structure and lattice parameters of
a
-phase and
hexagonal
d
-phase. Compared with
a
-phase,
d
-phase owns the
face-sharing [PbI
6
]
4-
octahedron alignment rather than corner
sharing; this results in the change of lattice distance. Take FAPbI
3
as
an example [41], too large FA cation causes a highly anisotropic
strain of cubic phase lattice (Fig. 3b), leading to the deviation from
the equilibrium interplanar distances, whereas the lattice strain
could be relaxed by alloying smaller MA cation. In a similar way,
double or triple cations of (Cs, FA)PbI
3
or (Cs, MA, FA)PbI
3
show the
same achievements [34,36,43,91,92] in better stability. A-site
doping indeed has revealed a feasible strategy for improving the
stability of phase structure.
In contrast to the A-site, B-site doping faces more challenges
into perovskite lattice, and they also play a big role in phase sta-
bility. On the contrary, most of discussion focused on the cases
whether dopants were introduced into the matrices of LHPs. The
phase structure of doped perovskite does not change generally after
replacing a tiny amount of Pb with Mn, Bi, or other B-site dopants
but may induce the lattice contraction/expansion or change the size
of crystal particles [46,60,61,93e95]. Zou et al [48] reported that
doping traces of Mn
2þ
(with an actual concentration of 2.08 mol %)
brought about the lattice contraction in CsPbBr
3
QDs. They calcu-
lated the three-dimensional stacking diagram of the CsPbBr
3
:Mn
crystal by density functional theory (DFT) (Fig. 3c); the much
shorter Mn-Br bonds compared with Pb-Br bonds were responsible
for the lattice distortions. They thought such kind of lattice con-
tractions are favorable for better thermal stabilities of perovskite
QDs. Similar results were also found by Akkerman et al [96] in Mn-
doped CsPbI
3
(inset of Fig. 3d); the metal-I bonds decreased from
3.14 Å (Pb-I) to 2.97 Å (Mn-I), which contributed to the cell
contraction. DFT (Fig. 3d) was also used to demonstrate the lattice
contraction as well as the negligible variation of the electronic
structures at the band edges. These changes in phase structure
induced by introduced dopants also verify the success incorpora-
tion of them into the perovskite lattice in turn.
3. Doping induced optoelectronic properties
3.1. Bandgap
The quintessential effects of doping to perovskite are on their
tunable bandgap and luminescence based on adjustable compo-
nents. Generally, A-site doping will slightly increase or decrease the
bandgaps depending on the size of the introduced cations. Taking
CsPbX
3
as the host, incorporation of larger impurities (such as FA or
MA) will decrease the bandgap, whereas smaller (such as Rb or K)
dopants will increase the bandgap (Fig. 4a). Meanwhile, partial
replacement of Cs
þ
by these doping cations will not alter their
phase structure of the initial CsPbX
3
NCs [97], which is of great
significance to the applications of photoelectric devices. Chen et al
[28] demonstrated that the bandgap of Cs
x
FA
1-x
PbBr
3
QDs gradu-
ally decreased with the increasing ratio of FA, reflected in the UV
spectra (Fig. 4b). The effect on bandgap is due to the altered Pb-Br
bond lengths and angles in the [PbX
6
]
4-
caused by the incorporation
of larger FA
þ
. The same trend has been found in Cs
x
MA
1-x
PbBr
3
and
Cs
x
FA
1-x
PbI
3
system [98]. The opposite trend has been observed
when smaller cations are introduced. For example, Amgar et al [27]
synthesized Rb
x
Cs
1-x
PbX
3
QDs with blue-shifting absorption band
edge with the increasing ratio of Rb (Fig. 4c). Similarly, other re-
ports [33,99] about incorporation of K
þ
into CsPbBr
3
and CsPbCl
3
QDs brought in the blue shift of absorption spectrum. Overall,
doping to A-site adjusts the bandgap of perovskite in a tiny range
(within 0.1 eV) owing to the altered Pb-X band lengths and angles
in the [PbX
6
]
4-
octahedron caused by the impurities size.
Fig. 2. Perovskite structures and structure factors. (a) Breakdown diagram of perovskite structure. (b) The tolerance factor of 3D lead halide perovskite with general A-site cations,
X-site anions, and octahedral factor of [BX
6
]
4-
octahedra with possible B-site cations.
L. Xu et al. / Materials Today Nano 6 (2019) 100036 3
剩余14页未读,继续阅读
2021-02-08 上传
2021-01-27 上传
2024-06-21 上传
2023-03-29 上传
2023-03-29 上传
2023-03-29 上传
2024-09-06 上传

weixin_38605604
- 粉丝: 3
- 资源: 853
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
