“(Language Modeling)Introduction to N-grams - 介绍语言建模中的N-grams技术及其在LLMs(大型语言模型)、AI、人工智能和语言模型中的应用。”
在自然语言处理(NLP)领域,语言建模是一种关键任务,它涉及到计算一个句子或一系列单词的概率。N-grams是实现这一目标的一种统计方法。今天我们要探讨的是N-grams在语言建模中的基本概念以及它们如何被用来提升机器翻译、拼写纠正、语音识别等应用的性能。
首先,让我们理解什么是语言建模。它的主要目标是为给定的句子或单词序列赋予一个概率值。例如,在机器翻译中,我们希望模型能判断出“P(high winds tonight)”的概率大于“P(large winds tonight)”,以选择更合适的翻译。同样,在拼写纠正中,模型应能识别出“P(about fifteen minutes from)”比“P(about fifteen minuets from)”更合理。在语音识别中,模型会倾向于选择概率更高的“P(I saw a van)”而非“P(eyes awe of an)”。
N-grams是解决这一问题的一种统计方法,它基于前n个单词来预测下一个单词的概率。例如,对于二元模型(bigrams),我们可以计算出“P(w5|w1, w2)”——即在给定w1和w2的情况下w5出现的概率。对于三元模型(trigrams),则会考虑三个单词的历史信息:“P(w5|w1, w2, w3)”。更复杂的模型会考虑更多上下文单词,如四元模型(quadgrams)和五元模型(pentagrams)。
然而,计算一个句子的联合概率“P(w1, w2, w3, w4, w5…wn)”直接会面临“维数灾难”的问题,因为随着单词数量的增加,可能的组合呈指数增长。为了解决这个问题,我们利用概率链规则。链规则允许我们将复杂的联合概率分解为条件概率的乘积,使得我们可以逐步计算每个单词出现的概率,如:
P(w1, w2, w3, w4, ..., wn)= P(w1) * P(w2|w1) * P(w3|w1, w2)* ... * P(wn|w1, w2, ..., wn-1)
语言模型通过这种方式来学习词汇之间的依赖关系,并用这些信息来预测序列中下一个可能出现的词。在实际应用中,我们通常使用平滑技术,如Laplace平滑或Kneser-Ney平滑,来处理未见过的n-gram组合,避免概率为零的问题。
N-grams在现代的大型语言模型(LLMs)中扮演着基础角色,尽管它们已被更复杂的方法,如循环神经网络(RNNs)、长短时记忆网络(LSTMs)、门控循环单元(GRUs)以及Transformer架构所超越。这些深度学习模型能够捕获更长距离的依赖关系,但N-grams仍然在某些任务中作为有效的基线模型,并且在资源有限的环境下尤其有用。
N-grams是语言建模的基础,它们为理解和改进自然语言处理的各种任务提供了统计基础,包括但不限于机器翻译、拼写纠正、语音识别、文本摘要、问答系统等。通过学习和理解N-grams,我们可以更好地构建和评估这些应用的性能。



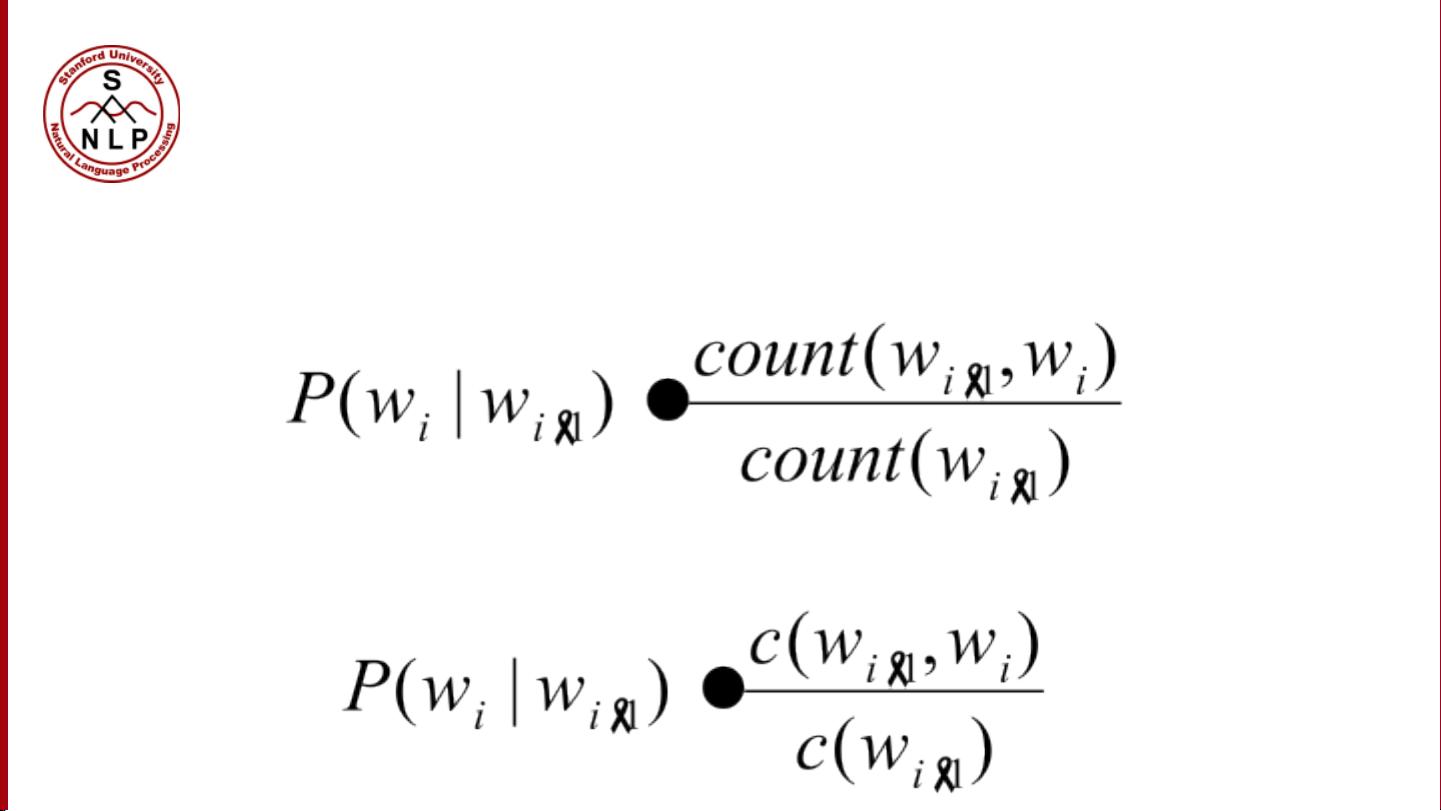
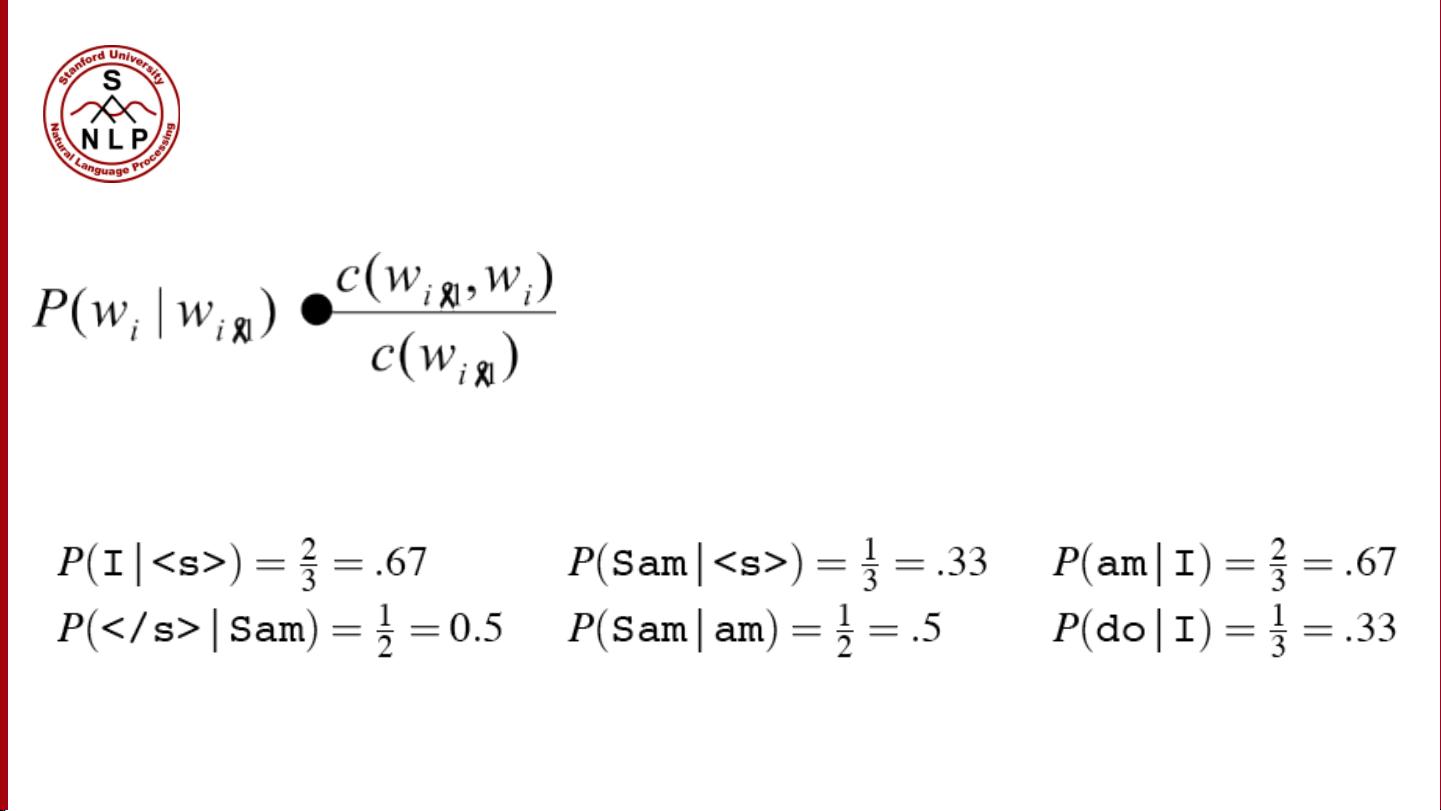

 我的内容管理
展开
我的内容管理
展开









