深图卷积网络:GCNs能像CNNs一样深吗?
需积分: 13 87 浏览量
更新于2024-07-16
收藏 2.66MB PDF 举报
“_DeepGCNs Can GCNs Go as Deep as CNNs.pdf” 是一篇探讨如何使图卷积网络(GCNs)实现深度学习的论文。该论文指出,尽管卷积神经网络(CNNs)在各种领域表现出色,尤其是在处理欧几里得数据时,但它们在处理非欧几里得数据时遇到困难。为了解决这个问题,图卷积网络被提出,利用图结构来表示非欧几里得数据,并借鉴了CNN的一些概念。然而,GCNs通常受限于浅层模型,因为它们在训练过程中容易遇到梯度消失问题。
论文作者Guohao Li、Matthias M¨uller、Ali Thabet和Bernard Ghanem来自沙特阿拉伯KAUST的视觉计算中心。他们针对GCNs的深度学习限制提出了新的解决方案,借鉴了CNN中的残差连接(residual connections)和空洞卷积(dilated convolutions),并将其适应到GCN框架中。
首先,残差连接在CNN中被广泛用于解决深层网络中的梯度消失问题,通过直接在层间添加短路,使得信号可以直接传递,保持每一层的梯度流动。将这一思想应用到GCNs中,可以促进深度GCNs的训练,使得信息能够更容易地在网络的深层传播,克服深度增加带来的性能下降问题。
其次,空洞卷积(也称为扩张卷积)是CNN中用来增加感受野而不增加参数数量的一种技术。在GCNs中,引入空洞卷积可以帮助模型捕捉更广泛的邻域信息,这对于非欧几里得数据尤其重要,因为图的结构可能包含长距离的关系。这不仅可以提升模型的表达能力,也有助于解决深度GCNs中可能遇到的局部视野限制。
通过这些改进,论文作者成功地训练了深度GCNs,挑战了传统观念认为GCNs不能像CNNs那样深的限制。这一研究进展对于处理复杂图结构数据,如社交网络、化学分子结构或地理信息网络等,具有重大意义,它可能开启GCNs在更多领域的广泛应用,包括但不限于计算机视觉、自然语言处理和社会网络分析。
这篇论文展示了如何通过借鉴和调整深度学习中的有效策略,克服图卷积网络在深度上的局限性,为深度GCNs的发展提供了新的理论基础和技术手段。这将推动非欧几里得数据处理领域的研究和实践进一步向前发展。
Input
1x1 Conv
f=1024
1x1 Conv
f=512
1x1 Conv
f=256
1x1 Conv
f=13
Global
Max Pooling
GCN
Backbone
Block
Fusion Block
MLP
Prediction
Block
Output
Add
Concat
k = # of nearest neighbors
f = # of filters or hidden units
d = dilation rate
InputInput
Input
PlainGCN
k=16 f=64
PlainGCN
k=16 f=64
PlainGCN
k=16 f=64
PlainGCN
k=16 f=64
PlainGCN
k=16 f=64
ResGCN
k=16 f=64 d=1
ResGCN
k=16 f=64 d=1
ResGCN
k=16 f=64 d=2
ResGCN
k=16 f=64 d=26
ResGCN
k=16 f=64 d=27
DenseGCN
k=16 f=64 d=1
DenseGCN
k=16 f=32 d=1
DenseGCN
k=16 f=32 d=2
DenseGCN
k=16 f=32 d=26
DenseGCN
k=16 f=32 d=27
PlainGCN
Backbone
ResGCN
Backbone
DenseGCN
Backbone
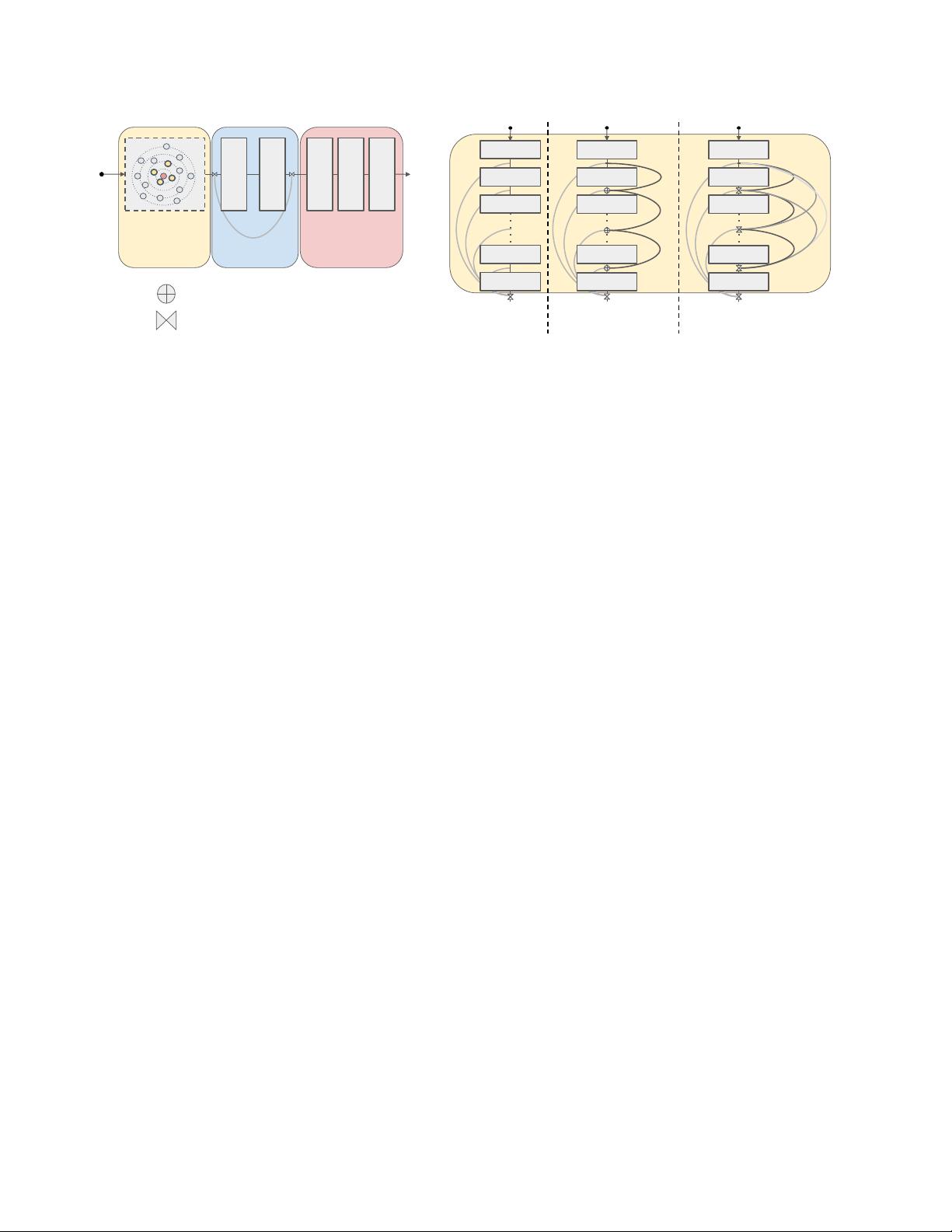
Figure 2. Proposed GCN architecture for point cloud semantic segmentation. (left) Our framework consists of three blocks: a GCN
Backbone Block (feature transformation of input point cloud), a Fusion Block (global feature generation and fusion), and an MLP Predic-
tion Block (point-wise label prediction). (right) We study three types of GCN Backbone Block (PlainGCN, ResGCN and DenseGCN) and
use two kinds of layer connection (vertex-wise addition used in ResGCN or vertex-wise concatenation used in DenseGCN).
we transfer these ideas to GCNs to unleash their full poten-
tial. This enables much deeper GCNs that reliably converge
in training and achieve superior performance in inference.
In the original graph learning framework, the underlying
mapping F, which takes a graph as an input and outputs
a new graph representation (see Equation (1)), is learned.
Here, we propose a graph residual learning framework that
learns an underlying mapping H by fitting another mapping
F. After G
l
is transformed by F, vertex-wise addition is
performed to obtain G
l+1
. The residual mapping F learns
to take a graph as input and outputs a residual graph repre-
sentation G
res
l+1
for the next layer. W
l
is the set of learnable
parameters at layer l. In our experiments, we refer to our
residual model as ResGCN.
G
l+1
= H(G
l
, W
l
)
= F(G
l
, W
l
) + G
l
= G
res
l+1
+ G
l
.
(3)
3.3. Dense Connections in GCNs
DenseNet [13] was proposed to exploit dense connectiv-
ity among layers, which improves information flow in the
network and enables efficient reuse of features among lay-
ers. Inspired by DenseNet, we adapt a similar idea to GCNs
so as to exploit information flow from different GCN layers.
In particular, we have:
G
l+1
= H(G
l
, W
l
)
= T (F(G
l
, W
l
), G
l
)
= T (F(G
l
, W
l
), ..., F(G
0
, W
0
), G
0
).
(4)
The operator T is a vertex-wise concatenation function that
densely fuses the input graph G
0
with all the intermedi-
ate GCN layer outputs. To this end, G
l+1
consists of all
the GCN transitions from previous layers. Since we fuse
GCN representations densely, we refer to our dense model
as DenseGCN. The growth rate of DenseGCN is equal to
the dimension D of the output graph (similar to DenseNet
for CNNs [13]). For example, if F produces a D dimen-
sional vertex feature, where the vertices of the input graph
G
0
are D
0
dimensional, the dimension of each vertex fea-
ture of G
l+1
is D
0
+ D × (l + 1).
3.4. Dilated Aggregation in GCNs
Dilated wavelet convolution is an algorithm originating
from the wavelet processing domain [12, 33]. To allevi-
ate spatial information loss caused by pooling operations,
Yu et al. [51] propose dilated convolutions as an alternative
to applying consecutive pooling layers for dense prediction
tasks, e.g. semantic image segmentation. Their experiments
demonstrate that aggregating multi-scale contextual infor-
mation using dilated convolutions can significantly increase
the accuracy of semantic segmentation tasks. The reason
behind this is the fact that dilation enlarges the receptive
field without loss of resolution. We believe that dilation can
also help with the receptive fields of deep GCNs. Therefore,
we introduce dilated aggregation to GCNs. There are many
possible ways to construct a dilated neighborhood. We use
a Dilated k-NN to find dilated neighbors after every GCN
layer and construct a Dilated Graph. In particular, for an
input graph G = (V, E) with Dilated k-NN and d as the di-
lation rate, the Dilated k-NN returns the k nearest neighbors
within the k × d neighborhood region by skipping every d
neighbors. The nearest neighbors are determined based on
a pre-defined distance metric. In our experiments, we use
the `
2
distance in the feature space of the current layer.
Let N
(d)
(v) denote the d-dilated neighborhood of vertex
v. If (u
1
, u
2
, ..., u
k×d
) are the first sorted k × d nearest
neighbors, vertices (u
1
, u
1+d
, u
1+2d
, ..., u
1+(k−1)d
) are the
d-dilated neighbors of vertex v (see Figure 3), i.e.
N
(d)
(v) = {u
1
, u
1+d
, u
1+2d
, ..., u
1+(k−1)d
}.
4
剩余16页未读,继续阅读
2021-05-04 上传
2020-11-20 上传
2023-06-09 上传
2023-06-11 上传
2023-04-01 上传
2023-04-01 上传
2023-06-05 上传
2023-03-30 上传


weixin_38313113
- 粉丝: 7
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
