
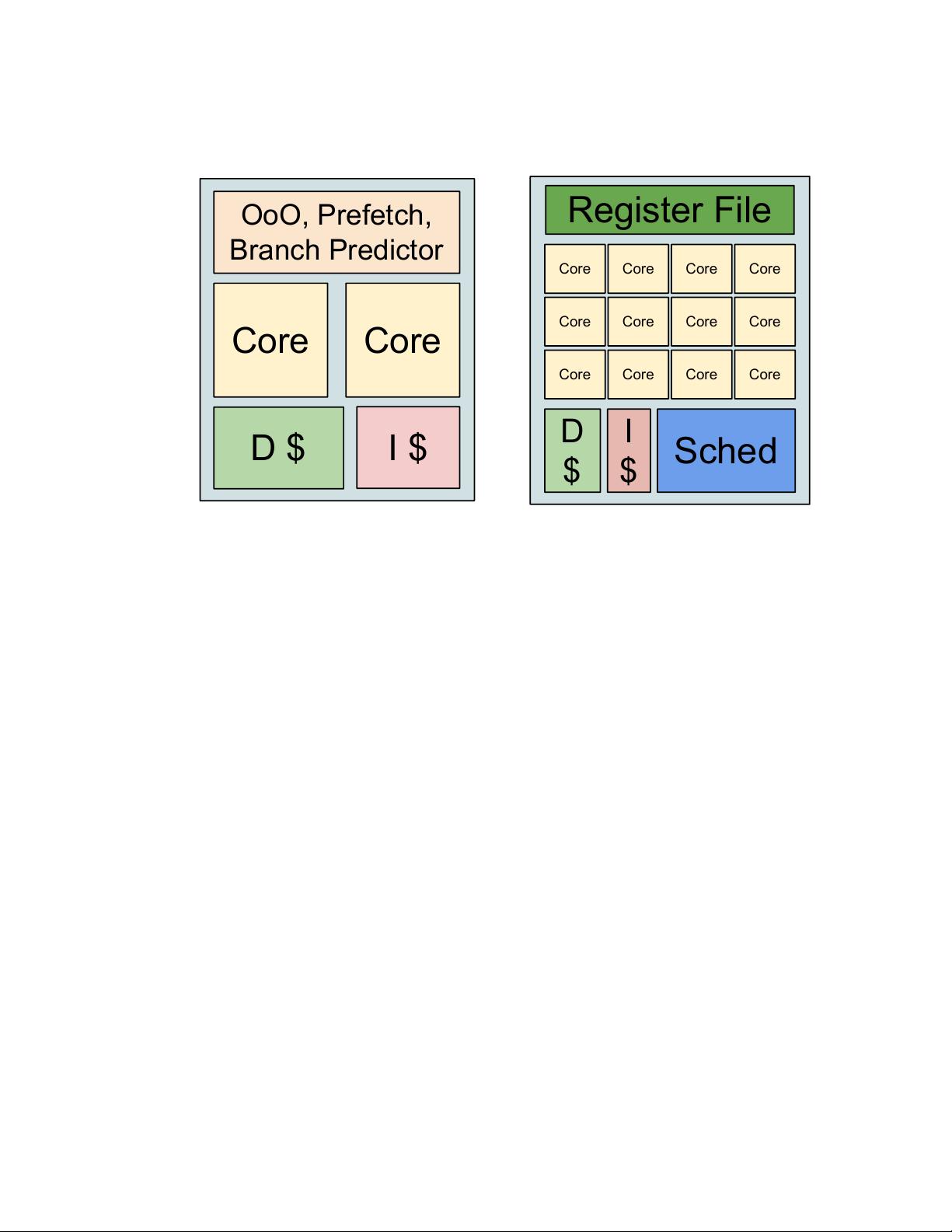
CHAPTER 1. INTRODUCTION
Core Core
D $
OoO, Prefetch,
Branch Predictor
I $
(a) CPU Architecture
Core Core Core Core
Core Core Core Core
Core Core Core Core
Register File
D
$
Sched
I
$
(b) GPU Architecture
Figure 1.2: CPU & GPU Architecture Comparison
space occupied by the big cache and branch predictor can be used to place more in-order cores on
chip. Hence, more threads can run in parallel. Even though latency for each thread becomes much
bigger, the overall throughput is much better compared to CPU. Moreover, without the big cache,
branch predictor and out-of-order execution (all of them are very power-hungry), this design also
consumes much less power, resulting in much better power efficiency.
However to benefit from this design, applications need to have a huge amount of inherent
parallelism. One great example of throughput-oriented design is GPU, which is traditionally cus-
tomized for running graphics applications. Graphics applications inherently have a lot of parallelisms
as there is a large number of pixels in each image/frame. Also, operations on each pixel are usually
similar and independent from each other. Besides graphics applications, many other applications also
have inherent parallelism, such as particle simulation, weather simulation, etc. These applications
are ideal candidates for GPUs acceleration. However, programming GPUs was not easy before
since all objects need to be described as triangles and actions need to be converted to graphics
operations on those triangles. This process is a very counter-intuitive and time-consuming. Later,
with the introduction of general-purpose GPUs programming model such as CUDA [
1
] and OpenCL
[
2
], we see a significant boost in GPUs adoption. Effectively, CUDA / OpenCL is an extension to
high-level language such as C/C++, enabling programmers to use GPUs by writing their algorithms
3



剩余75页未读,继续阅读

ysastro
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++标准程序库:权威指南
- Java解惑:奇数判断误区与改进方法
- C++编程必读:20种设计模式详解与实战
- LM3S8962微控制器数据手册
- 51单片机C语言实战教程:从入门到精通
- Spring3.0权威指南:JavaEE6实战
- Win32多线程程序设计详解
- Lucene2.9.1开发全攻略:从环境配置到索引创建
- 内存虚拟硬盘技术:提升电脑速度的秘密武器
- Java操作数据库:保存与显示图片到数据库及页面
- ISO14001:2004环境管理体系要求详解
- ShopExV4.8二次开发详解
- 企业形象与产品推广一站式网站建设技术方案揭秘
- Shopex二次开发:触发器与控制器重定向技术详解
- FPGA开发实战指南:创新设计与进阶技巧
- ShopExV4.8二次开发入门:解决升级问题与功能扩展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


