Spark数据框架与数据集性能优化解析
版权申诉
121 浏览量
更新于2024-06-21
收藏 537KB PDF 举报
"藏经阁-Demystifying Data Frame and Dataset"
本文由Kazuaki Ishizaki,一位在IBM Research - Tokyo从事编译器优化研究的专家撰写。他专注于Java虚拟机的即时编译器工作超过20年,并且对Apache Spark的SQL包有所贡献,同时是GPU Enabler项目的提交者,这是一个使Apache Spark能够在Spark上执行GPU代码的插件。
在“Demystifying DataFrame and Dataset”中,作者主要讨论了Spark 2.2版本中DataFrame和Dataset性能的提升。相较于Spark 2.0和2.1,Spark 2.2在处理数据操作时有了显著的加速。例如,对于使用scalar变量的map操作,性能提高了1.6倍;而对于使用原始数组的map操作,性能提升了4.5倍。这些改进归功于Catalyst优化器和代码生成器的增强。
性能提升的实现对不同类型的用户有重大影响:
1. 应用程序员:机器学习管道(ML pipelines)将运行得更快,这意味着开发人员可以更高效地处理大数据分析任务,提高工作效率。
2. 库开发者:推荐使用Dataset而不是RDD(弹性分布式数据集),因为Dataset提供了更强的类型安全性和更好的性能。这将使得开发人员能够编写出更加健壮且运行效率更高的代码。
DataFrame和Dataset是Apache Spark中的核心数据结构,DataFrame是基于Spark SQL的表概念,而Dataset是DataFrame的强类型版本,它结合了DataFrame的易用性和RDD的高性能。在Spark 2.x版本中,DataFrame和Dataset的优化使其成为大数据处理的首选工具。
在实际应用中,使用Dataset可以利用Catalyst优化器进行更高效的查询规划,同时,由于其类型安全的特性,可以减少因类型错误导致的运行时错误。此外,通过代码生成器,Spark可以生成针对特定操作的优化Java或Scala代码,从而提高执行速度。
了解DataFrame和Dataset的性能提升以及如何利用它们的优势,对于任何在Spark平台上构建数据处理应用程序的人来说都是至关重要的。这不仅能够帮助提升现有应用的性能,也为未来的开发工作奠定了基础。为了更好地利用这些功能,开发者应深入理解DataFrame和Dataset的内部工作机制,以及如何在实践中有效地利用它们。
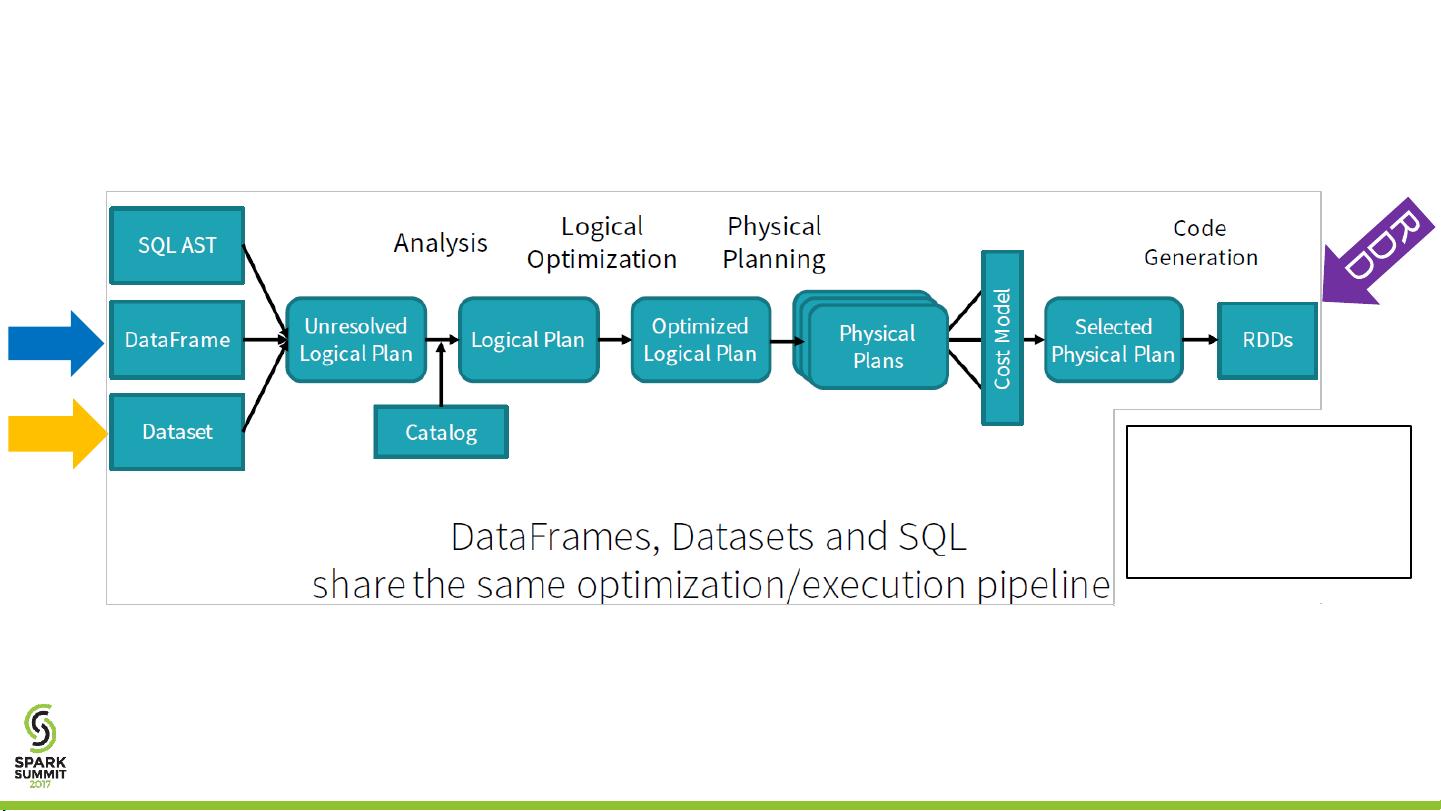
How DF, DS, and RDD Work
• We expect the same performance on DF and DS
From Structuring Apache Spark 2.0: SQL, DataFrames, Datasets And Streaming - by Michael Armbrust
DS
DF
Demystifying DataFrame and Dataset (#SFdev20) / Kazuaki Ishizaki
6
Catalyst
// generated Java code
// for DF and DS
while (itr.hasNext()) {
Row r = (Row)itr.next();
int v = r.getInt(0);
…
}

剩余31页未读,继续阅读
2021-08-22 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传
2024-09-06 上传

weixin_40191861_zj
- 粉丝: 77
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
