详解Memcached分布式缓存的原理与应用
199 浏览量
更新于2024-08-28
收藏 543KB PDF 举报
Memcached分布式缓存实现原理简介
在高并发环境中,数据库面对海量的读写请求时,磁盘I/O往往会成为性能瓶颈,引发响应延迟。为了解决这个问题,缓存技术应运而生。本文将重点讨论分布式缓存服务Memcached的分布式实现,特别是它如何通过分散负载和提高数据访问速度来提升Web应用的性能。
缓存的本质在于计算机体系中的存储层次结构。按照冯·诺依曼架构,计算机包括运算器、控制器、存储器、输入设备和输出设备。在现代计算机中,CPU内部有三级缓存(如二级缓存3MB、二级缓存precore 256KB等),这些快速但容量有限的存储单元用于存储频繁访问的数据,形成存储金字塔模型,以降低访问慢速存储(如硬盘)的频率。
在应用层面,当应用程序需要数据时,首先尝试从缓存获取,如memcached。Memcached是一个由Danga Interactive开发的分布式内存对象缓存系统,广泛应用于诸如Facebook、Vox和LiveJournal等大型互联网服务,旨在减少对数据库的依赖,提高响应速度。
Memcached的分布式实现基于主从架构,通常包含多个节点服务器,每个节点都运行着一个独立的缓存实例。数据被分散存储在不同的节点上,通过一致性哈希算法确定数据的存储位置,确保数据的高效访问。当接收到请求时,客户端首先会尝试连接最近的节点,如果数据存在且未过期,则返回;否则,请求会被转发到正确的节点并从数据库获取数据,然后更新缓存,同时确保数据的一致性和缓存更新的同步。
为了进一步优化性能,Memcached支持多线程和事件驱动模型,这意味着它可以同时处理多个请求,避免了单线程系统中的阻塞。此外,它还提供了一套命令接口,用于管理缓存项的添加、删除和查询操作。
总结来说,Memcached分布式缓存的实现核心在于利用分布式架构和内存存储的优势,通过一致性哈希、数据分片和高效的通信机制,实现在高并发环境下的快速数据检索,有效缓解数据库压力,显著提升Web应用的性能和扩展性。
Memcached 分布式缓存实现原理简介分布式缓存实现原理简介
摘要摘要
在高并发环境下,大量的读、写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生。无论是单机缓存还是分布式缓存都有其适
应场景和优缺点,当今存在的缓存产品也是数不胜数,最常见的有redis和memcached等,既然是分布式,那么他们是怎么实现分布式的呢?本文主要介绍分布式缓
存服务mencached的分布式实现原理。
缓存本质
计算机体系缓存计算机体系缓存
什么是缓存,我们先看看计算机体系结构中的存储体系,根据冯·诺依曼计算机体系结构模型,计算机分为五大部分:运算器、控制器、存储器、输入设备、输出设
备。结合现代计算机,CPU包含运算器和控制器两个部分,CPU负责计算,其需要的数据由存储提供,存储分为几个级别,就拿我当前的PC举个例子,我的机器存
储清单如下:
1.356G的磁盘
2.4G的内存
3.3MB三级缓存
4.256KB二级缓存(pre core)
除了上述部分,还有CPU内的寄存器,当然有的计算机还有一级缓存等。CPU运算器工作的时候需要数据,数据哪里来?首先从距离CPU最近的二级缓存去拿,这块
缓存速度最快,通常也是体积最小,因为价格最贵:
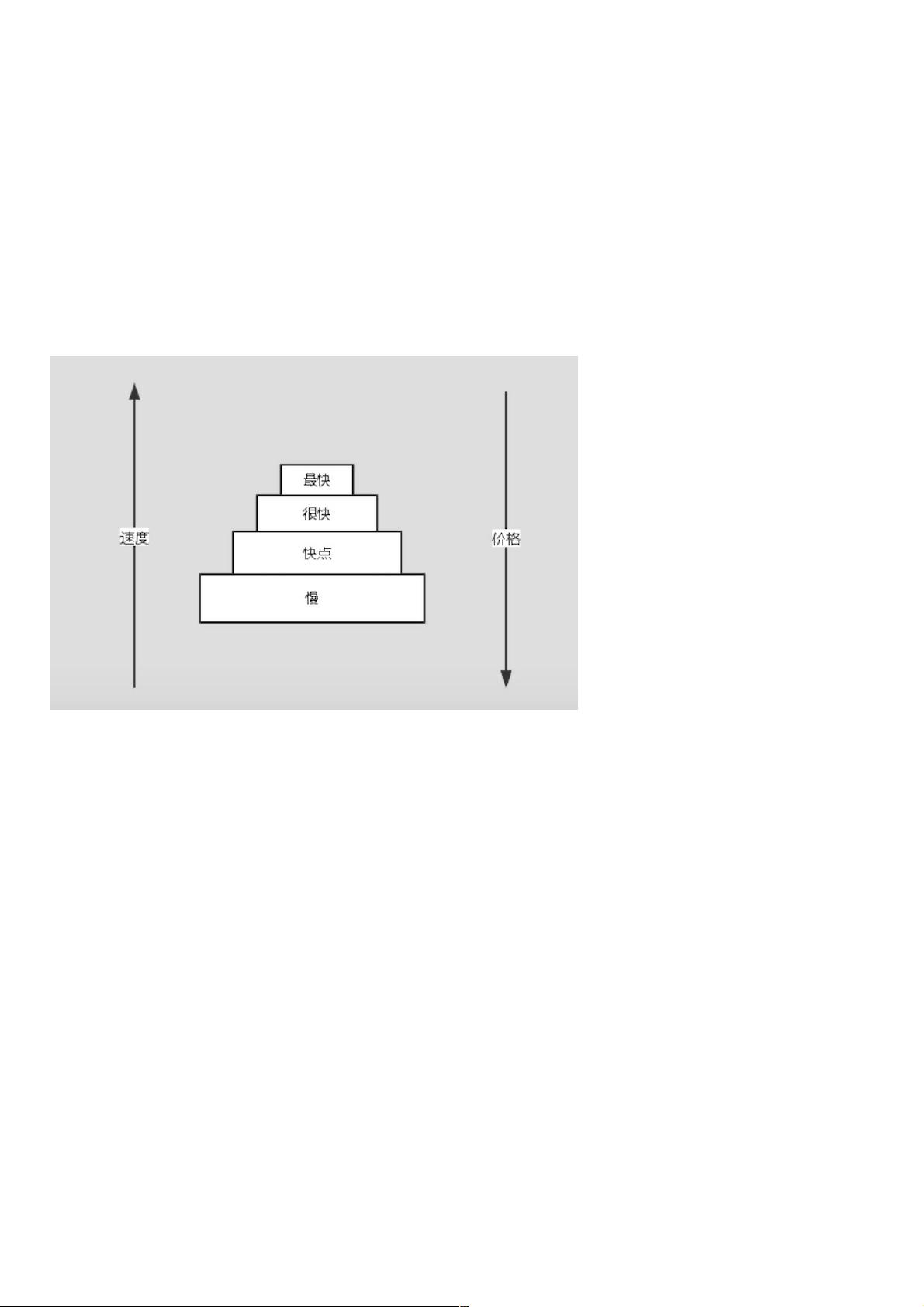
存储金字塔存储金字塔
如上图所示,存储体系就像个金子塔,最上层最快,价格最贵,最下层最慢,价格也最便宜,CPU的数据源优先级一层层从上到下去寻找数据。
很显然,除了最慢的那块存储,在计算机体系中,相对较快的那些存储都可以被称为缓存,他们解决的问题是让存储访问更快。让存储访问更快。
缓存应用系统缓存应用系统
计算机体系存储系统模型扩展到应用也是一样,应用需要数据,数据哪里来?缓存(更快的存储)->DB(较慢的存储),他们的工作流程大致如下图所示:
下载后可阅读完整内容,剩余5页未读,立即下载
2022-08-04 上传
2012-08-16 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38728347
- 粉丝: 4
- 资源: 912
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
