Memcached分布式缓存原理详解:高性能应对高并发
50 浏览量
更新于2024-09-02
收藏 540KB PDF 举报
Memcached分布式缓存实现原理简介
在高并发的现代互联网环境中,数据库面临着巨大的压力,尤其是当大量的读写请求频繁地冲击时,磁盘I/O成为性能瓶颈,这导致了响应时间的显著增加。为了解决这个问题,缓存技术应运而生。单机缓存和分布式缓存各有适用场景,其中Memcached作为常见的分布式缓存解决方案,其分布式实现原理成为关注焦点。
首先,理解缓存的本质至关重要。计算机体系结构中,按照冯·诺依曼模型,存储体系由多个层次组成,包括快速但容量有限的二级缓存、更慢但容量更大的三级缓存,甚至包括CPU内的寄存器。这些都遵循“存储金字塔”原则,即越靠近CPU的数据访问速度越快。在应用层面,缓存系统通过存储快速的缓存来加速对数据的访问,如果数据不在缓存中,才会查询较慢的数据库。
Memcached本身是由Danga Interactive公司开发的,最初是为LiveJournal服务,后来被广泛应用于许多大型网站,如mixi、hatena、Facebook等。它是一个键值对存储系统,设计目标是提供一个轻量级、内存密集型的缓存服务,用于存储小数据对象,以便减少数据库查询次数。
Memcached的分布式实现原理主要包括以下几个关键点:
1. **一致性哈希算法**:Memcached采用一致性哈希算法来分配键值对到不同的服务器节点。当数据插入或删除时,通过哈希函数确定其在缓存中的位置,即使添加或移除服务器,也能保持数据分布的相对稳定,降低数据迁移的开销。
2. **复制策略**:为了提高可用性和容错性,Memcached支持数据的多副本存储。每个键值对可以在多个节点上进行冗余存储,这样即使某个节点故障,其他节点仍能提供服务。
3. **负载均衡**:通过轮询、随机选择或其他策略,请求被均匀地分发到各个节点,避免单点过载。当节点间性能差异较大时,可以动态调整节点权重,进一步优化请求处理。
4. **心跳检测与失效机制**:节点之间定期交换心跳信息,监控节点状态。如果节点不可用,其上的数据会被标记为失效,并从其他节点接管。此外,Memcached还支持TTL(Time To Live)过期策略,自动清理不再需要的数据。
5. **通信协议**:Memcached使用简单、高效的二进制协议进行通信,减少了网络开销,提高了数据传输效率。
Memcached的分布式实现是通过一致性哈希、复制、负载均衡和失效管理等机制,确保在高并发环境下,为应用提供快速的数据访问,同时保持数据的一致性和可用性。学习和理解这些原理对于优化分布式系统性能和提高应用水平至关重要。
Memcached 分布式缓存实现原理简介分布式缓存实现原理简介
主要介绍了Memcached 分布式缓存实现原理简介,具有参考价值,需要的朋友可以参考下。
摘要摘要
在高并发环境下,大量的读、写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生。无论是单机缓存还是分布式缓存都有其适
应场景和优缺点,当今存在的缓存产品也是数不胜数,最常见的有redis和memcached等,既然是分布式,那么他们是怎么实现分布式的呢?本文主要介绍分布式缓
存服务mencached的分布式实现原理。
缓存本质
计算机体系缓存计算机体系缓存
什么是缓存,我们先看看计算机体系结构中的存储体系,根据冯·诺依曼计算机体系结构模型,计算机分为五大部分:运算器、控制器、存储器、输入设备、输出设
备。结合现代计算机,CPU包含运算器和控制器两个部分,CPU负责计算,其需要的数据由存储提供,存储分为几个级别,就拿我当前的PC举个例子,我的机器存
储清单如下:
1.356G的磁盘
2.4G的内存
3.3MB三级缓存
4.256KB二级缓存(pre core)
除了上述部分,还有CPU内的寄存器,当然有的计算机还有一级缓存等。CPU运算器工作的时候需要数据,数据哪里来?首先从距离CPU最近的二级缓存去拿,这块
缓存速度最快,通常也是体积最小,因为价格最贵:
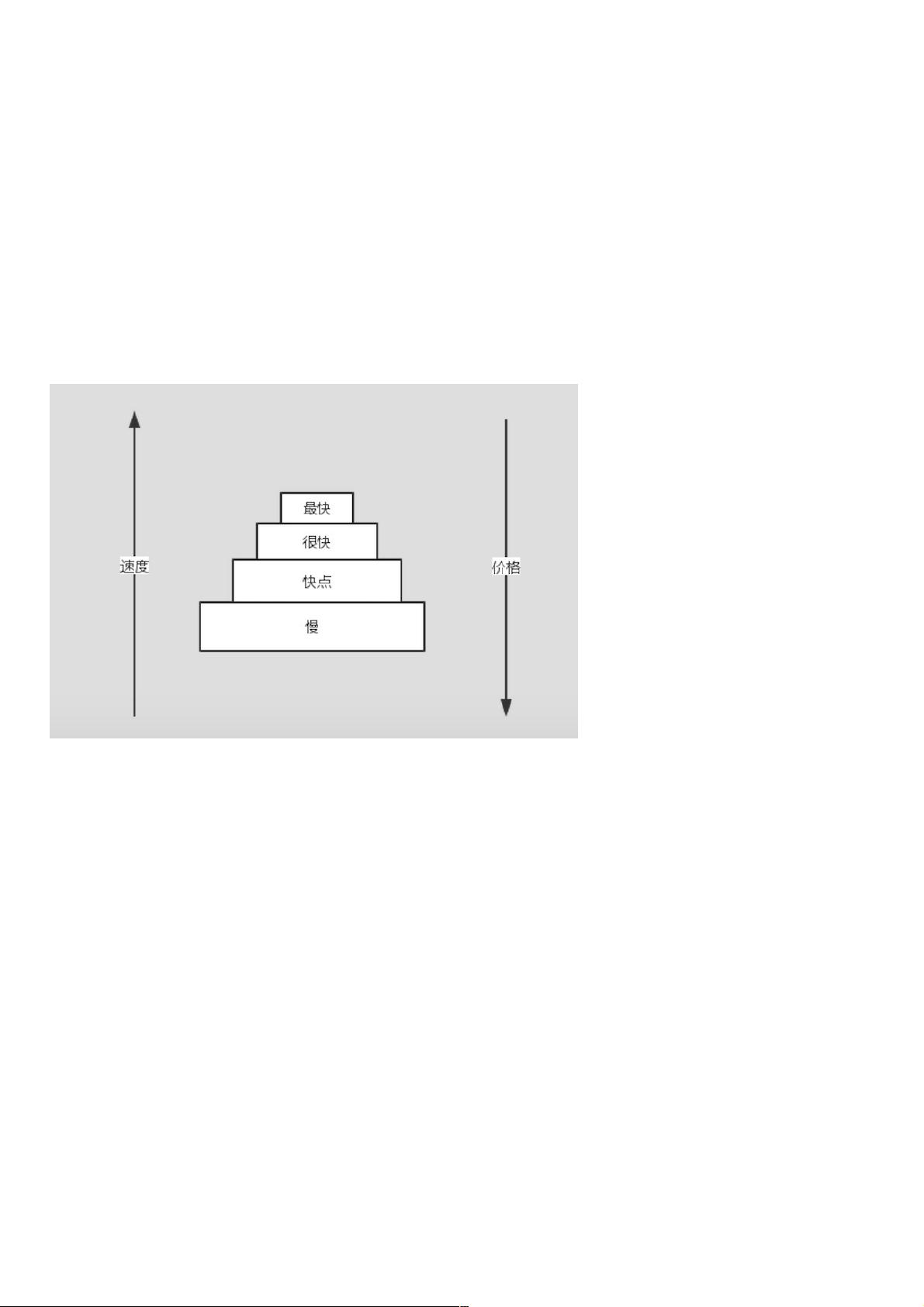
存储金字塔存储金字塔
如上图所示,存储体系就像个金子塔,最上层最快,价格最贵,最下层最慢,价格也最便宜,CPU的数据源优先级一层层从上到下去寻找数据。
很显然,除了最慢的那块存储,在计算机体系中,相对较快的那些存储都可以被称为缓存,他们解决的问题是让存储访问更快。让存储访问更快。
缓存应用系统缓存应用系统
计算机体系存储系统模型扩展到应用也是一样,应用需要数据,数据哪里来?缓存(更快的存储)->DB(较慢的存储),他们的工作流程大致如下图所示:
下载后可阅读完整内容,剩余5页未读,立即下载
2022-08-04 上传
2012-08-16 上传
点击了解资源详情
点击了解资源详情
2017-07-26 上传
2011-11-29 上传
2012-04-01 上传
2012-01-02 上传
点击了解资源详情

weixin_38725086
- 粉丝: 6
- 资源: 910
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
