NT3947B TFT LCD驱动器V1.0:2004年特性与规格
需积分: 5 154 浏览量
更新于2024-07-15
收藏 652KB PDF 举报
NT3947B是一款专为TFT液晶显示屏设计的驱动器,该文档是其V1.0版本,发布日期为2004年2月13日。该驱动器的主要特性包括:
1. **功能特性**:
- 支持TFT LCD面板的驱动,提供480(RGBx160)或402(RGBx134)通道输出的选择。
- 内置双采样和保持电路,提高图像稳定性。
- 提供三种或单个时钟信号选择,适应不同的显示需求。
- 动态范围广泛,支持从0.1到4.9伏的电压输出,输出电压偏差控制在+20毫伏以内。
- 配备级联功能,用于像素扩展,提高分辨率。
- 右移和左移功能,方便处理数据流。
- 具有可切换的R、G、B信号,适应不同类型的彩色滤镜。
- 支持数字和模拟两种电源输入:2.5~5.5V的数字电源和3~5.5V的LCD电源。
- 设计为裸芯片,配备金质封装,适用于COG( Chip-on-Glass)集成解决方案。
- 输出使能信号具有选择性。
2. **电气特性**:
- 包括直流电(D-C)和交流电(A-C)的电气参数,如最大工作电流、上升时间和下降时间等,这些数据对于驱动器的性能和系统设计至关重要。
- 提供了详细的波形图,展示了时序特性和操作条件下的信号行为。
3. **结构与尺寸**:
- 文件还包含芯片的引脚分配图和布局描述,这对于硬件工程师在板级设计中确定连接方式和封装要求非常有用。
- 芯片的物理尺寸信息,包括封装类型和外部组件的安装空间。
4. **修订历史**:
- 文档列出了从1.0版本到1.04版本的更新内容,表明产品持续优化以满足用户需求和市场变化。
总体而言,NT3947B是一款功能强大且灵活的TFT LCD驱动器,适用于多种应用场景,对设计者来说,它提供了全面的技术规格和性能参数,便于理解和集成到各种显示系统中。
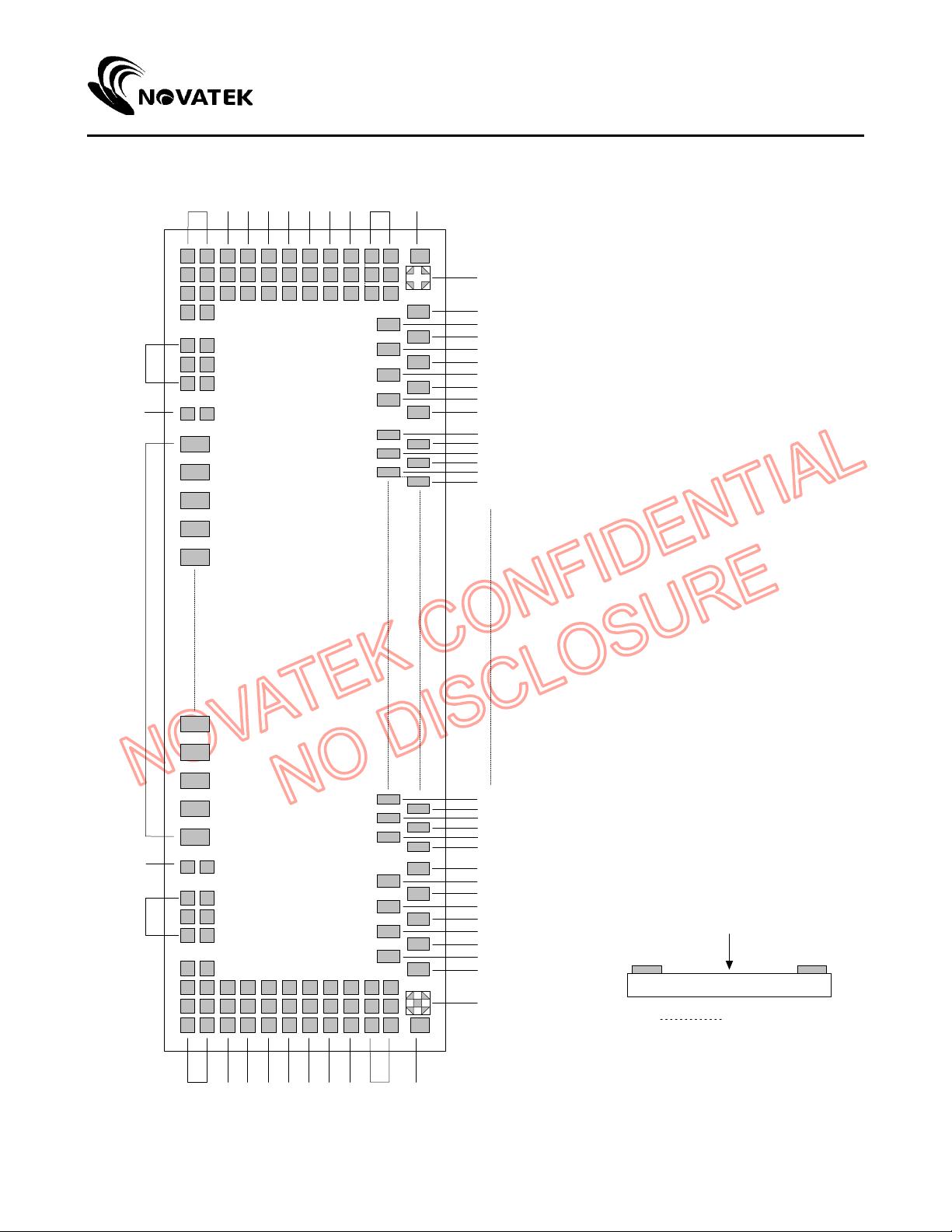
NT3947
2004/2/13 Ver 1.0
5
Pin Assignment ( IC face view )
Bumper Bumper
View
Output channel
Alignment
mark
DUMMY
Dummy line (160)
AGND
CPH3
CPH2
CPH1
VCC
GND
VA
VB
VC
AVDD
AGND
DUMMY
CPH3
CPH2
CPH1
VCC
GND
VA
VB
VC
AVDD
Alignment
mark
Q
A
1
Q
B
1
Q
C
1
Q
A
2
Q
B
2
Q
C
2
S
T
H
1
P
A
S
S
Q
2
H
O
E
Q
1
H
M
O
D
R
/
L
E
D
G
S
L
C
H
N
S
L
S
T
H
2
P
A
S
S
Q
2
H
O
E
Q
1
H
M
O
D
R
/
L
E
D
G
S
L
C
H
N
S
L
Q
C
1
6
0
Q
B
1
6
0
Q
A
1
6
0
Q
B
1
5
9
Q
C
1
5
9
Q
A
1
5
9
TP1
TP2
TP3
TP4
剩余22页未读,继续阅读
2020-09-19 上传
2021-02-16 上传
2021-02-16 上传
2023-06-09 上传
2023-06-03 上传
2023-06-13 上传
2023-06-11 上传
2023-06-12 上传
2024-11-04 上传
2023-06-06 上传

u010365054
- 粉丝: 5
- 资源: 1237
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
