实时流处理系统:Storm与大数据实时分析
需积分: 10 47 浏览量
更新于2024-07-25
1
收藏 584KB DOC 举报
"实时流处理系统"
在大数据领域,实时流处理系统扮演着至关重要的角色。实时流处理系统,如Apache Storm,允许开发者处理不断产生的无界数据流,提供快速、可靠的实时计算能力。Storm是由Twitter开源的,其设计目标是简化分布式实时计算,支持多种编程语言,尤其是Clojure和Java,同时也允许非JVM语言通过JSON格式的stdin/stdout接口与系统交互。
实时流处理与传统的批处理模式(如MapReduce和Hadoop)不同,后者更适合于离线分析和批量处理固定的数据集。然而,随着数据量的爆炸性增长和业务需求的即时性,实时流处理系统应运而生,它们能够处理源源不断的实时数据,比如传感器数据、社交媒体消息、交易记录等,并且在数据产生时就进行处理,极大地缩短了延迟时间。
数据流计算模型的核心理念是数据的价值随时间递减,因此需要尽快处理。这一模型强调事件驱动,一个事件发生即触发一次处理,避免数据积累和批量处理。数据流模型中的数据元素是在线到达的,无法预知其顺序,且可能无限大。由于数据一旦处理过通常不会被存储,所以系统需要高效地处理和丢弃数据,或者进行必要的归档。
数据流计算的特点包括:
1. 实时性:数据元素在线到达,需要即时处理。
2. 不可控性:系统无法控制数据元素的到达顺序,这可能导致重放的数据流顺序不同。
3. 无界性:数据流可能无穷无尽,处理完的数据通常不再可访问。
4. 状态管理:操作可分为有状态(保留处理历史)和无状态(不保存历史信息)。
Apache Storm提供了一种分布式、容错的平台,用于构建实时计算应用程序。它允许用户定义自定义的计算拓扑,其中包含“spouts”(数据源)和“bolts”(处理组件)。Spouts接收数据流,而bolts执行计算任务,如过滤、聚合、转换等。通过这种方式,Storm可以灵活地构建复杂的实时处理逻辑,适应各种应用场景,如实时分析、在线机器学习、持续计算、分布式RPC和ETL(提取、转换、加载)等。
此外,实时流处理系统还与其他技术相结合,如Apache Kafka作为消息队列,用于缓冲和传输数据流;Apache Flink和Apache Spark Streaming等其他实时处理框架,提供了更丰富的功能和优化。这些系统共同构成了大数据实时处理的生态系统,为企业和研究机构提供了强大的工具来应对实时数据挑战。
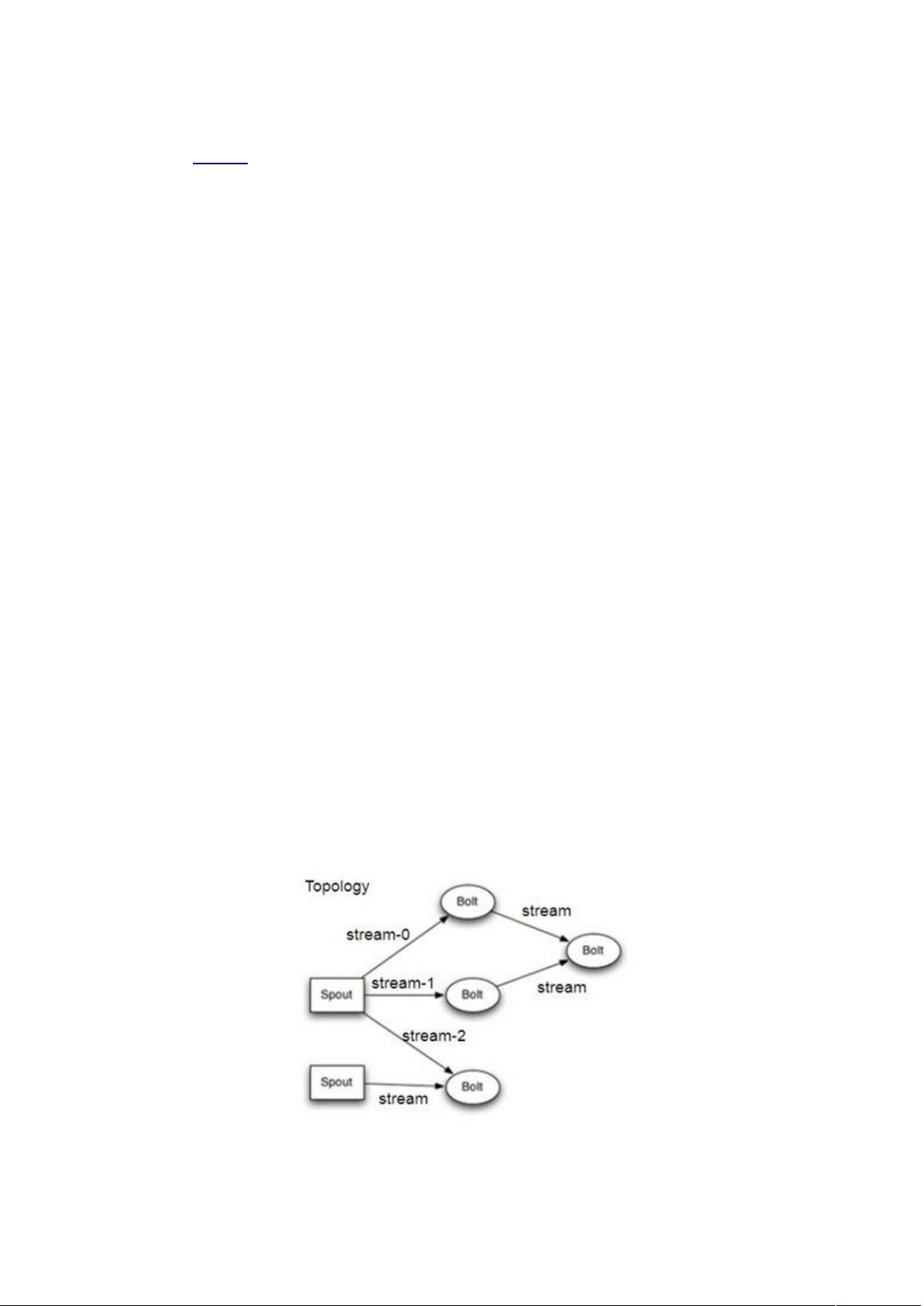
Storm 可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm 之于实时处理,
就好比 Hadoop
之于批处理。Storm 保证每个消息都会得到处理,而且它很快——在一个小
集群中,每秒可以处理数以百万计的消息。更棒的是你可以使用任意编程语言来做开发。
Storm 的应用场景主要有以下三类:
信息流处理(Stream processing)
Storm 可用来实时处理新数据和更新数据库,兼顾容错性和可扩展性。
持续计算(Continuous computation)
Storm 可进行持续 Query 并把结果即时反馈给客户端。比如把 Twitter 上的热门话题发送
到浏览器中。
分布式远程程序调用(Distributed RPC)
Storm 可用来并行处理密集查询。Storm 的拓扑结构是一个等待调用信息的分布函数,当
它收到一条调用信息后,会对查询进行计算,并返回查询结果。例如 Distributed RPC 可以
做并行搜索或者处理大集合的数据。
Storm 的主要特点如下:
简单的编程模型
类似于 MapReduce 降低了并行批处理复杂性,Storm 降低了进行实时处理的复杂性。
支持各种编程语言
可以在 Storm 之上使用各种编程语言。默认支持 Clojure、Java、Ruby 和 Python。要增加
对其他语言的支持,只需实现一个简单的 Storm 通信协议即可。
支持容错
Storm 会管理工作进程和节点的故障。
支持水平扩展
计算是在多个线程、进程和服务器之间并行进行的。
可靠的消息处理
Storm 保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息 。
Storm 使用一种比较巧妙的方式判断 tuple 是否丢失,即发送方和应答方都需要向系统内部
的第三方 acker 异或一个随机数,如果在超时时间内 acker 上记录的消息随机数为 0 则认为
消息已被正确处理,否则 acker 将通知 spout 进行重放。
高效消息处理
系统的设计保证了消息能得到快速的处理,使用 ØMQ 作为底层消息队列。
Storm 数据流处理
示意图
Storm 并不提供
消息的去重和算子
状态的持久化,如
果有这方面的需求,
需要在应用层面进
行处理。这两点也
符 合 Storm 的 设 计
初衷,消息重复是
其为了容错和保证消息不丢而带来的副作用,但是对大多数实时计算来说,并不会要求达
到批处理的那种准确度,所以大多数应用都不会对消息重复比较敏感;如果应用对消息重
剩余18页未读,继续阅读
2021-03-04 上传
2019-08-29 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

woodmoon1
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
