OpenCV HaarTraining算法详解:特征提取与级联回归应用
需积分: 10 58 浏览量
更新于2024-09-18
收藏 314KB PDF 举报
OpenCV中的HaarTraining算法是一个关键的图像处理技术,它基于Friedman、J.H等人提出的"Additive Logistic Regression: A Statistical View of Boosting"理论,专注于解决2类分类问题下的四种Boost算法:Discrete AdaBoost、RealAdaBoost、LogitBoost和GentleAdaBoost。OpenCV利用扩展的Haar特征,这些特征由Rainer Lienhart等人在"An Extended Set of Haar-like Features for Rapid Object Detection"中介绍,使得算法在实时对象检测中表现出高效性能。
HaarTraining的核心流程分为三个步骤:
1. **样本准备**:为了训练,首先需要准备正负样本。正样本通常需要经过裁剪和规范化处理,确保所有样本具有相同的尺寸,以便输入到算法中。正样本以vec文件的形式存储,需要通过OpenCV的CreateSamples程序构建。
2. **样本集构建**:CreateSamples程序负责生成正样本集,这一步骤是训练的基础,它将原始图像转换为算法可以理解的特征向量。
3. **训练过程**:最后,使用HaarTraining程序进行实际的模型训练,这个过程涉及到迭代和弱分类器的组合,以形成强大的分类器模型。OpenCV采用的是Viola等人在"Robust Real-Time Face Detection"中描述的级联分类器(Cascade of Classifiers)训练方法,这种级联结构允许快速且准确地识别物体。
在整个过程中,版权归属作者周明才,但需要获得其授权才能用于商业用途。同时,作者欢迎读者提出批评指正和交流,以共同提升算法的理解和应用。
在实践中,Haar特征因其简单和高效而被广泛应用在人脸识别、行人检测等领域,但需要注意的是,算法的性能会受到样本质量和数量的影响,以及特征选择和参数调整的合理性。因此,深入理解并掌握HaarTraining算法及其背后的统计学原理对于有效运用OpenCV至关重要。
像数据。
3.2 负样本
负样本图像可以是不含有正样本模式的任何图像,比如一些风景照等。训练时,OpenCV
需要一个负样本描述文件,该文件只需包含所有负样本的文件名及绝对(或相对)路径名。
以下是一个负样本描述文件内容示例:
nonface_200/00001.bmp
nonface_200/00002.bmp
nonface_200/00003.bmp
…
负样本描述文件的生成方法可参照正样本描述文件生成方法。
负样本图像的大小只要不小于正样本就可以,在使用负样本时,OpenCV 自动从负样本
图像中抠出一块和正样本同样大小的区域作为负样本,具体可查看函数
icvGetNextFromBackgroundData()。具体抠图过程为:
1) 确定抠图区域的左上角坐标(Point.x, Point.y)
2) 确定一个最小缩放比例,使得原负样本图像缩放后恰好包含选中负样本区域
3) 对原负样本图象按计算好的缩放比例进行缩放
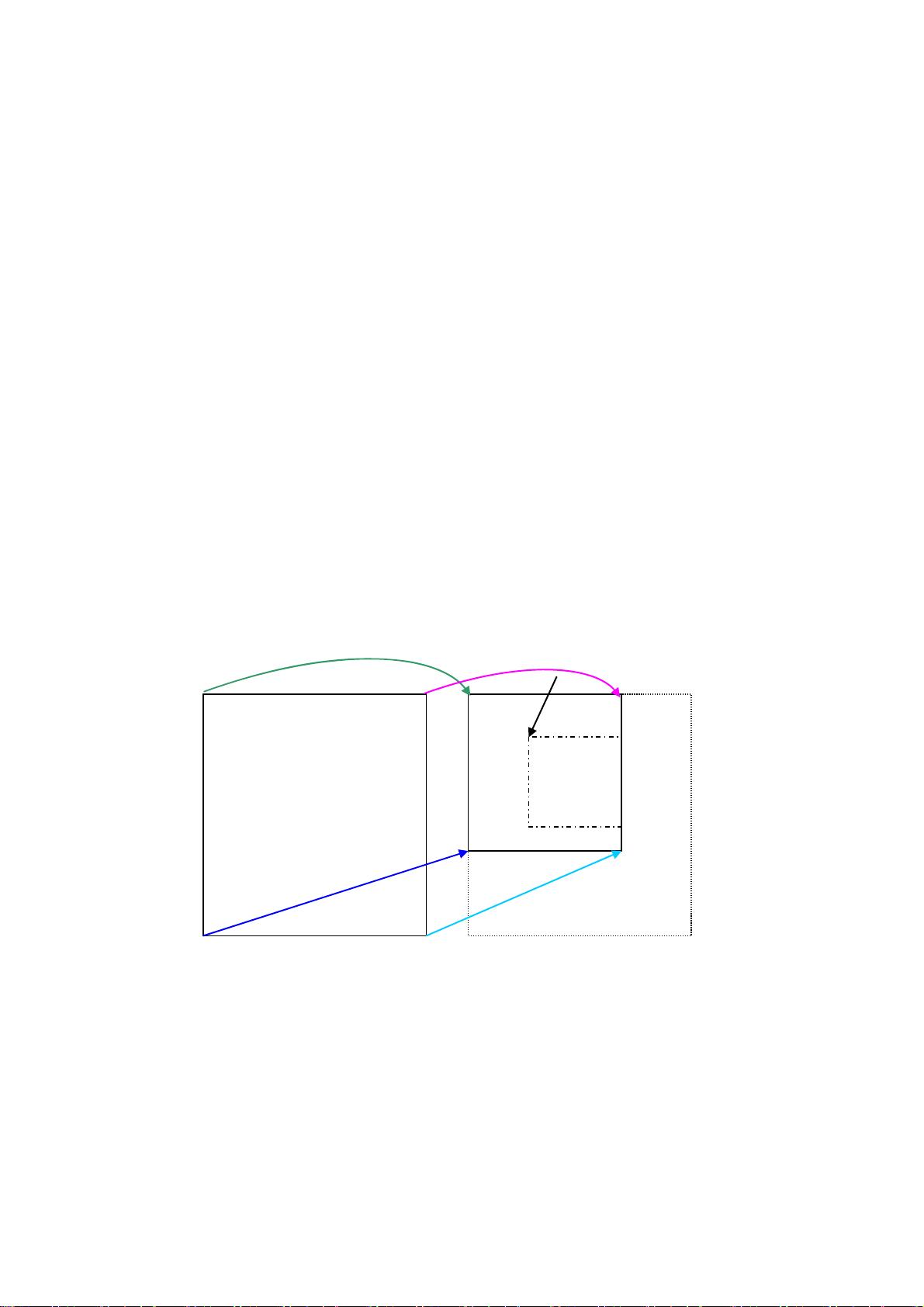
4) 在缩放后的图像上抠出负样本,如图 3.2 左半部分的虚线框所示。
Reader->img
Reader->src
(Point.x,Point.y)
图 3.2 抠图示意图
3
剩余11页未读,继续阅读
2013-06-02 上传
2014-04-01 上传
2013-08-19 上传
2024-10-25 上传
2023-04-07 上传
2023-04-07 上传
2024-09-12 上传
2023-10-11 上传
2023-08-21 上传

zjtongyong
- 粉丝: 0
- 资源: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- 作业1:cst438_assign1
- z.js:via通过Unicode的ZW(N)Js隐藏文本
- 基于Linux、QT、C++的点餐系统
- zerg:小程序教程源码-源码程序
- glogIntroduce,c语言会员积分管理系统源码,c语言程序
- 最新时时地震信息程序 V1.0
- studienarbeit2021:Niclas Mummert,斯图加特DHBW和Bertrandt Technologie GmbH的研究
- 全功能11-26A.zip
- 将Excel文件动态导入到SQL Server
- 信用卡养卡app开发HTML5模板
- Android应用源码之项目实例 商业项目源代码.zip项目安卓应用源码下载
- wx-computed2:几乎照搬vue原始码为小程序增加计算和观看特性-源码程序
- matlab 图片中隐藏信息以及提取的程序代码.zip
- level-0-module-1-alysiaroh:GitHub Classroom创建的level-0-module-1-alysiaroh
- easy_roles:轻松管理Rails的角色
- queue,c语言制作图书管理软件源码,c语言程序
