Transformer:自注意力与突破RNN限制的翻译模型
版权申诉
"Self-Attention与Transformer是深度学习领域中用于自然语言处理和机器翻译的重要技术,尤其在序列到序列(Sequence-to-Sequence, Seq2Seq)模型中取代了传统的循环神经网络(RNN)结构,解决了RNN的梯度消失和时间依赖性问题。以下是关于这两个概念的详细介绍:
1. **起源与问题**:
在Transformer出现前,主流的翻译模型是基于RNN的Encoder-Decoder架构,它在编码阶段捕获输入序列的信息,并在解码阶段逐步生成目标语言序列。然而,RNN模型存在两大挑战:首先,RNN的梯度在反向传播过程中容易消失,导致深层网络的学习困难;其次,RNN具有固有的时间顺序,不支持并行计算,限制了模型的效率。Transformer通过自注意力机制(Self-Attention)和多头注意力(Multi-Head Attention)的设计,成功地解决了这些问题。
2. **Transformer的整体框架**:
输入序列中的每个元素(如词或字符)x1,x2...,通过Self-Attention模块进行信息交互。这个过程涉及三个关键矩阵:查询矩阵(Query)、键矩阵(Key)和值矩阵(Value)。通过矩阵运算,每个元素得到一个注意力权重分布,表示与其他元素的相关程度。Self-Attention允许模型在不同位置之间建立直接连接,捕捉全局上下文,从而避免了RNN的时间依赖性。
3. **Self-Attention机制的解释**:
在数学上,假设输入为4维向量,通过矩阵乘法生成对应的查询、键和值向量,然后通过softmax函数计算每个元素对其他元素的关注度得分。这些得分决定了信息如何被加权整合,形成一个新的上下文向量。这种机制使得Transformer能够动态地关注输入序列中的关键信息,实现单词级别的关联,例如在翻译句子时,能正确识别“it”指代的是“animal”而非“street”。
4. **意义与优势**:
自注意力机制的核心价值在于它能够捕捉到输入序列中元素之间的复杂关系,这对于理解句子含义至关重要。例如,在翻译"The animal didn't cross the street because it was too tired"时,Self-Attention有助于模型理解“it”与“animal”的关系,增强翻译的准确性。Transformer的并行计算能力使其在处理大规模数据时效率更高,且模型训练速度更快。
总结来说,Self-Attention是Transformer的核心组成部分,它革新了序列模型的计算方式,使得模型能够在处理自然语言时更好地理解和建模词语间的依赖关系,从而在机器翻译、文本摘要、问答系统等领域取得了显著的性能提升。"
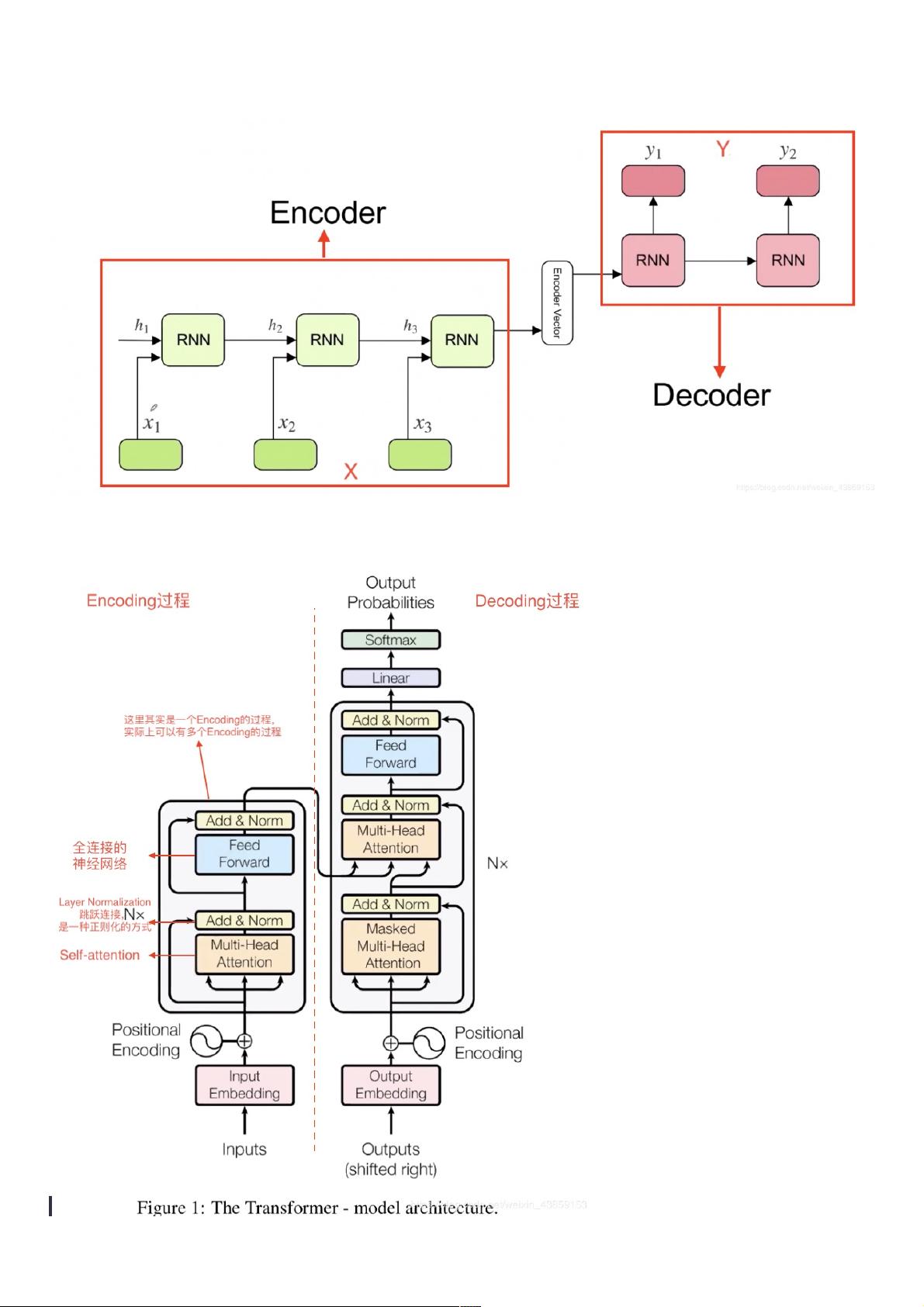
Self-Attention与与Transformer
1.由来由来
在Transformer之前,做翻译的时候,一般用基于RNN的Encoder-Decoder模型。从X翻译到Y。
但是这种方式是基于RNN模型,存在两个问题。
一是RNN存在梯度消失的问题。(LSTM/GRU只是缓解这个问题)
二是RNN 有时间上的方向性,不能用于并行操作。Transformer 摆脱了RNN这种问题。
2.Transformer 的整体框架的整体框架
下载后可阅读完整内容,剩余8页未读,立即下载
2018-08-08 上传
2022-08-03 上传
点击了解资源详情
点击了解资源详情
2024-11-07 上传
2023-09-24 上传
2023-05-15 上传

weixin_38611388
- 粉丝: 10
- 资源: 971
 我的内容管理
展开
我的内容管理
展开







最新资源
- motif-mark:盒式外显子基序可视化
- android-group,java小项目源码,自动售货机软件源码java
- 5de970ee89108da0b7e19eafd4beaaad:应用程序 ID 11155
- dumi
- Machine-Learning-NCF-class:应用机器学习班
- Merge Balls-crx插件
- DOM-Document-Object-Model,java项目源码下载,java免签
- YOLO_V1
- empresa-presentacion-sencilla-1:监控摄像机系统公司,警报器等
- UP
- 利用紫金桥软件完成现场工艺流程图的绘制.zip
- 实现文字的整体变色效果
- test-sample-for-tutorial
- UofI_eyelink_file_analizers
- learning:只是用于学习新事物的小型一次性项目的存储库
- tarena,java获取网页源码,网上教学系统源码java
