深度学习卷积详解:可分离卷积与3D卷积在视频处理中的应用
需积分: 0 43 浏览量
更新于2024-08-05
收藏 3.25MB PDF 举报
深度学习中的卷积是一种核心概念,特别是在卷积神经网络(CNN)中,它极大地促进了计算机视觉、自然语言处理等领域的发展。本文主要介绍了深度学习中几种常见的卷积类型及其特点。
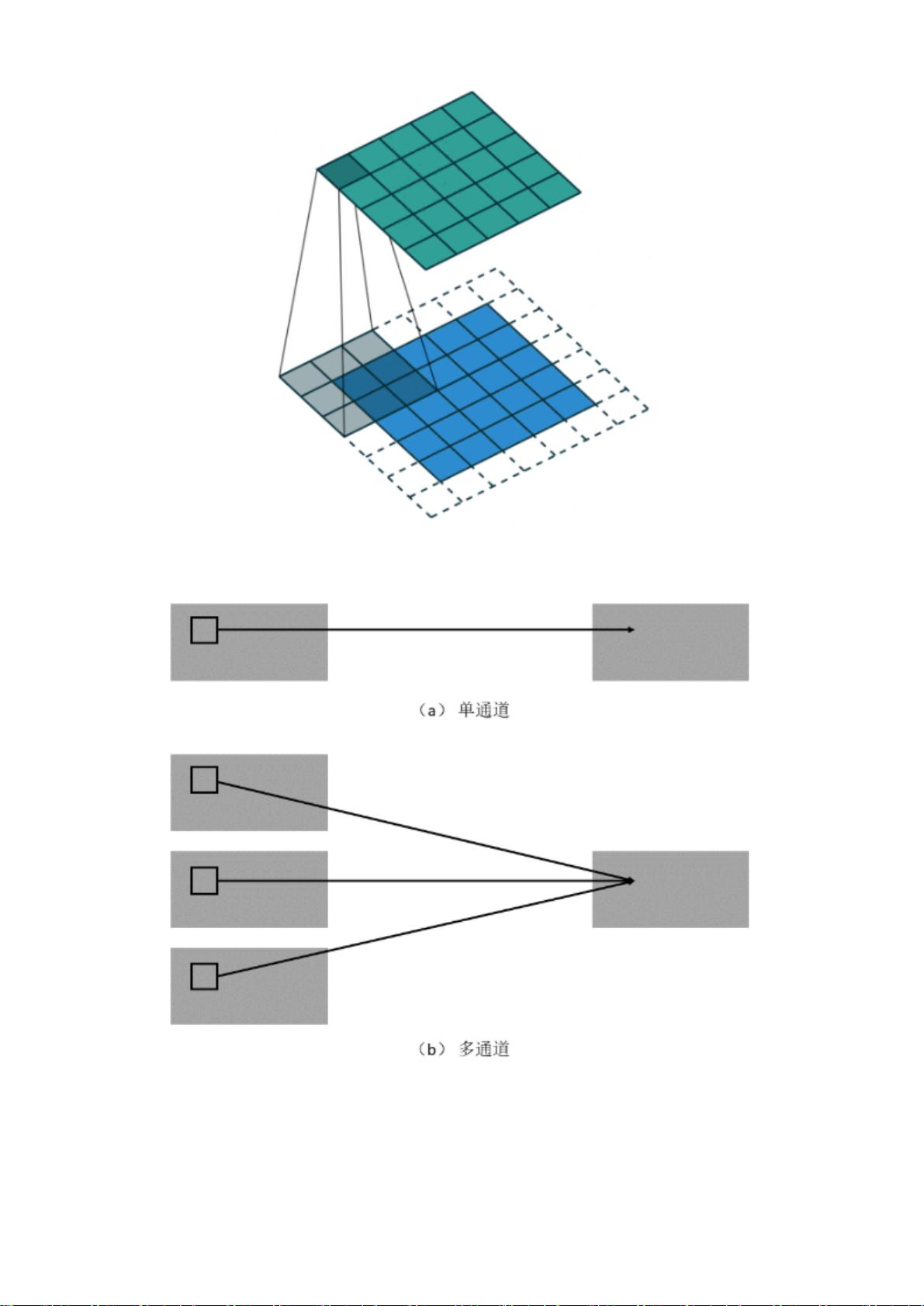
首先,普通卷积(2D Convolution)是最基础的卷积形式,用于图像处理时提取特征。它使用一个固定大小的滤波器(也称卷积核)在输入图像上进行滑动,对每个位置的像素进行加权求和,生成新的特征图。在多通道情况下,卷积操作会在每个通道上独立进行,形成具有丰富信息的特征表示。
3D卷积是对2D卷积的扩展,适用于处理三维数据,如视频。它增加了时间维度,使得网络能够捕捉连续帧之间的时空关系,这对于视频分析、动作识别等任务至关重要。
接下来,空洞卷积(Dilated Convolution 或 Atrous Convolution)是一种特殊的卷积方式,通过在滤波器元素间插入空洞(扩张),保持滤波器的大小不变,但扩大了感受野。这样做可以有效地增加网络的覆盖范围,而不会显著增加参数数量,有助于保持模型的效率,特别适合于语义分割等需要大视野的场景。
最后,可分离卷积(Separable Convolution)是为了减少参数量而提出的。它将传统的卷积分解为两个步骤:第一部分是一个点wise卷积,对每个通道分别进行操作,增加了非线性;第二部分是一个标准的1D或2D卷积,只在空间维度上进行。这种方法在图像分类和卷积层较多的网络中尤其有效,因为它大大减少了参数,提高了计算效率。
总结起来,理解这些不同类型的卷积及其应用场景对于深入学习深度学习至关重要。在实践中,选择合适的卷积类型取决于任务需求、数据维度以及对模型复杂度和性能的要求。通过掌握这些基础知识,开发者可以在构建深度学习模型时更高效地应用卷积操作,提升模型的性能和泛化能力。
剩余11页未读,继续阅读
2018-02-01 上传
2018-03-09 上传
2021-08-19 上传
2023-06-07 上传
2023-07-15 上传
2023-11-04 上传
2024-04-02 上传
2023-05-04 上传
2023-06-06 上传

俞林鑫
- 粉丝: 19
- 资源: 288
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决本地连接丢失无法上网的问题
- BIOS报警声音解析:故障原因与解决方法
- 广义均值移动跟踪算法在视频目标跟踪中的应用研究
- C++Builder快捷键大全:高效编程的秘密武器
- 网页制作入门:常用代码详解
- TX2440A开发板网络远程监控系统移植教程:易搭建与通用解决方案
- WebLogic10虚拟内存配置详解与优化技巧
- C#网络编程深度解析:Socket基础与应用
- 掌握Struts1:Java MVC轻量级框架详解
- 20个必备CSS代码段提升Web开发效率
- CSS样式大全:字体、文本、列表样式详解
- Proteus元件库大全:从基础到高级组件
- 74HC08芯片:高速CMOS四输入与门详细资料
- C#获取当前路径的多种方法详解
- 修复MySQL乱码问题:设置字符集为GB2312
- C语言的诞生与演进:从汇编到系统编程的革命
