Sqoop在Hadoop与数据库间的数据迁移
版权申诉
178 浏览量
更新于2024-07-02
收藏 1.31MB PPTX 举报
"大数据运维技术第9章 Sqoop组件安装配置.pptx"
Sqoop是Apache软件基金会开发的一个工具,专门用于在Hadoop和关系型数据库之间进行数据传输。随着大数据处理需求的增长,Hadoop生态系统的MapReduce、Hive、HBase等分析工具的兴起,企业和组织面临着如何有效地在Hadoop与传统RDBMS之间迁移数据的问题。Sqoop的出现解决了这一难题,它能够方便地将数据从MySQL、Oracle等关系数据库导入到Hadoop的HDFS,反之亦可导出。
9.2 Sqoop功能应用
Sqoop的功能主要分为两大核心部分:数据导入和数据导出。
9.2.1 Sqoop架构
- 导入过程:Sqoop通过JDBC连接到关系数据库,利用MapReduce的并行处理能力,将数据分片并导入到HDFS。它会将导入操作转化为一系列的MapReduce任务,每个任务负责处理一部分数据。在执行过程中,Sqoop能够自动处理数据类型转换,确保数据库中的数据类型与Hadoop中的数据类型匹配。用户还可以自定义字段映射,以适应特定需求。
- 导出过程:对于导出,Sqoop同样基于MapReduce,将HDFS上的数据转换为适合关系数据库的格式,然后写回到数据库中。这一过程同样支持并行处理,提高效率。
此外,Sqoop提供了丰富的选项和参数,允许用户进行高级配置,比如指定导入导出的字段、过滤条件、数据分隔符等。它还支持增量导入,能够在数据库新增数据时仅导入新数据,保持数据同步。
9.2.2 Sqoop导入原理
Sqoop的导入原理主要依赖于JDBC的ResultSet接口。ResultSet是数据库查询结果的载体, Sqoop通过遍历ResultSet,将每一行数据作为MapReduce任务的一部分,由多个Mapper并行处理。每个Mapper处理一部分数据,然后Reducer将这些部分数据整合成完整的记录,最终写入HDFS。
Sqoop的整个工作流程包括了连接数据库、执行SQL查询、分割数据、启动MapReduce任务、将数据写入HDFS等多个步骤。在整个过程中,Sqoop保证了数据的完整性和一致性,同时提供了灵活的定制选项,以适应不同的业务场景。
Sqoop作为Hadoop生态系统中的重要组成部分,极大地简化了大数据环境与传统数据库之间的数据交换,提高了数据处理的效率和便利性。对于大数据运维人员来说,熟练掌握Sqoop的使用和配置,对于优化数据处理流程、提升数据分析速度具有重要意义。
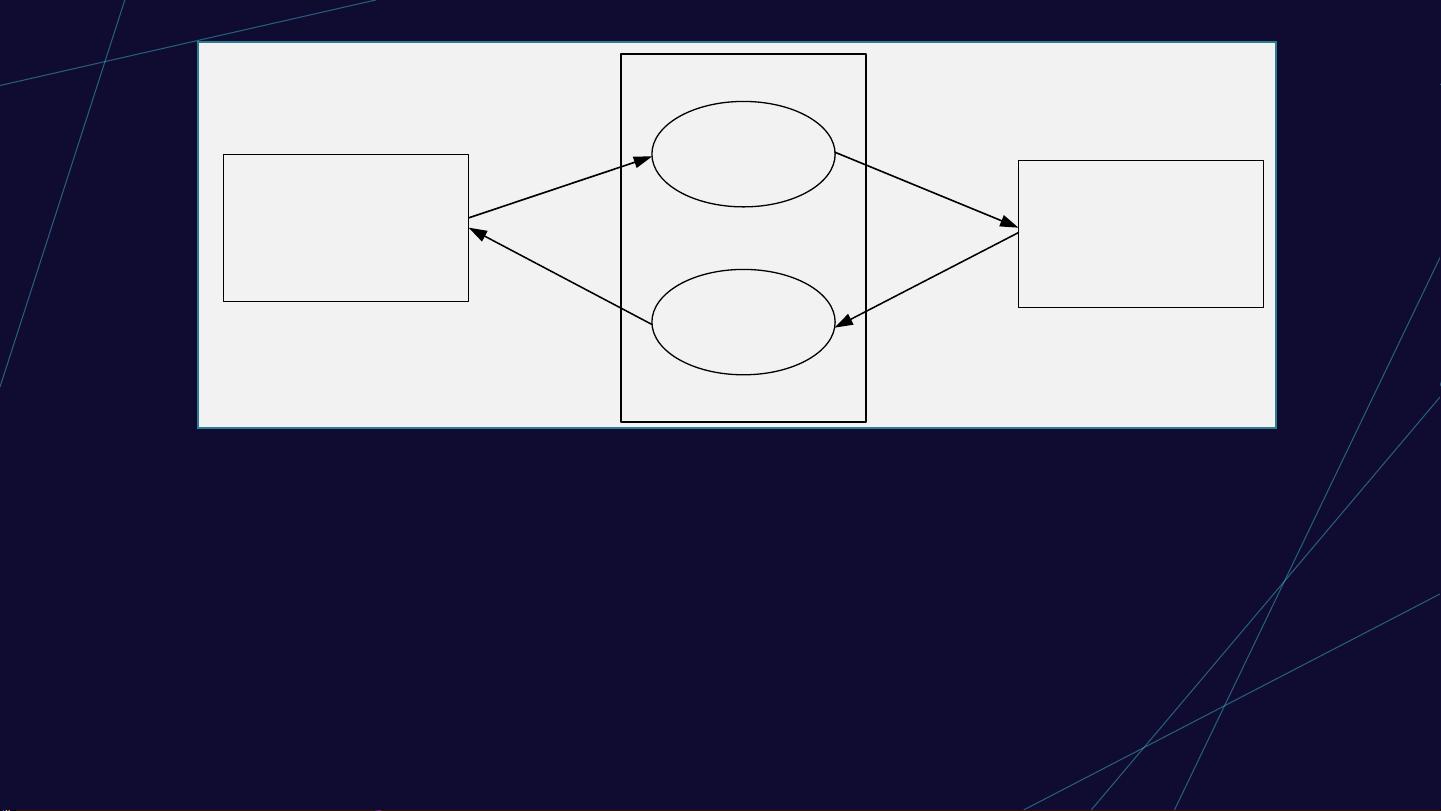
Sqoop 工具接收到客户端的 shell 命令或者 Java API 命令后,通过 Sqoop 中的任务翻译器 (Task
Translator) 将命令转换为对应的 MapReduce 任务,再将关系型数据库和 Hadoop 中的数据进行相
互转移,进而完成数据的拷贝。
Sqoop 架构部署简单、使用方便,但也存在一些缺点,例如命令行方式容易出错,格式紧耦合,无
法支持所有数据类型,安全机制不够完善,例如密码暴漏,安装需要 root 权限, connector 必须符
合 JDBC 模型。
数据导入
数据导出
关系型数据库
(MySQL、Oracle)
Hadoop
(HDFS、Hive、Hbase)
剩余34页未读,继续阅读
2022-12-24 上传
2023-05-27 上传
2023-05-18 上传
2023-11-08 上传
2023-11-21 上传
2023-12-23 上传
2023-06-11 上传
2023-05-24 上传

知识世界
- 粉丝: 366
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
