NVIDIA帕斯卡架构GP100:深度学习与HPC的加速利器
需积分: 0 41 浏览量
更新于2024-07-19
1
收藏 3.08MB PDF 举报
帕斯卡架构白皮书深入探讨了NVIDIA Tesla P100 GPU,这款革命性的数据中心加速器,凭借其卓越的性能和特性,引领了GPU计算的新时代。该白皮书重点介绍了以下几个关键方面:
1. **Pascal GP100GPU:世界最快GPU** - GP100是基于Pascal架构,旨在提供前所未有的速度和效能。它是专为高性能计算和深度学习优化的,支持双精度运算,提升高负载下的计算能力。
2. **极致性能与Deep Learning** - GP100集成了先进的FP16(半精度浮点)算术,这显著提升了深度学习训练的速度,对于大规模神经网络模型的处理效率至关重要。
3. **NVLink高速互连** - 新一代NVLink技术提供了极高的带宽,使得多GPU之间的连接以及GPU与CPU之间的通信更为高效,支持GPU间的数据共享和协同工作。
4. **HBM2高速GPU内存** - GP100采用了HBM2(High Bandwidth Memory 2),这是一种高带宽、低延迟的内存架构,极大地提高了内存访问速度,对性能提升起到了关键作用。
5. **统一内存和Compute Preemption** - 白皮书提到的统一内存设计简化了开发者的编程工作,同时引入了compute preemption功能,允许在不影响全局性能的情况下动态调整任务优先级。
6. **硬件架构详解** - 对GP100 GPU的内部结构进行了深入解析,包括Pascal Streaming Multiprocessor,其优化设计以支持高性能计算任务,以及L1/L2缓存的改进,提升了数据处理速度。
7. **内存冗余和耐久性** - Memory Resilience功能确保了即使在恶劣环境下,系统也能维持稳定运行,增强了数据可靠性。
8. **Tesla P100设计** - 白皮书中详细阐述了P100的设计理念,包括它的独特之处,如NVLink高速互联、GPU散热策略等,确保了设备的高性能和散热性能。
9. **配置选项** - NVLink有多种配置可供选择,以适应不同的系统需求,提供了灵活性和可扩展性。
NVIDIA Tesla P100的帕斯卡架构白皮书不仅介绍了这款GPU的核心技术和优势,还展示了其在现代数据中心和机器学习工作负载中的广泛应用潜力。通过深入理解这些技术细节,开发者可以更有效地利用P100进行高性能计算和深度学习任务。
GP100 Pascal Whitepaper
Tesla P100: Revolutionary Performance and
Features for GPU Computing
NVIDIA Tesla P100 WP-08019-001_v01.1 | 8
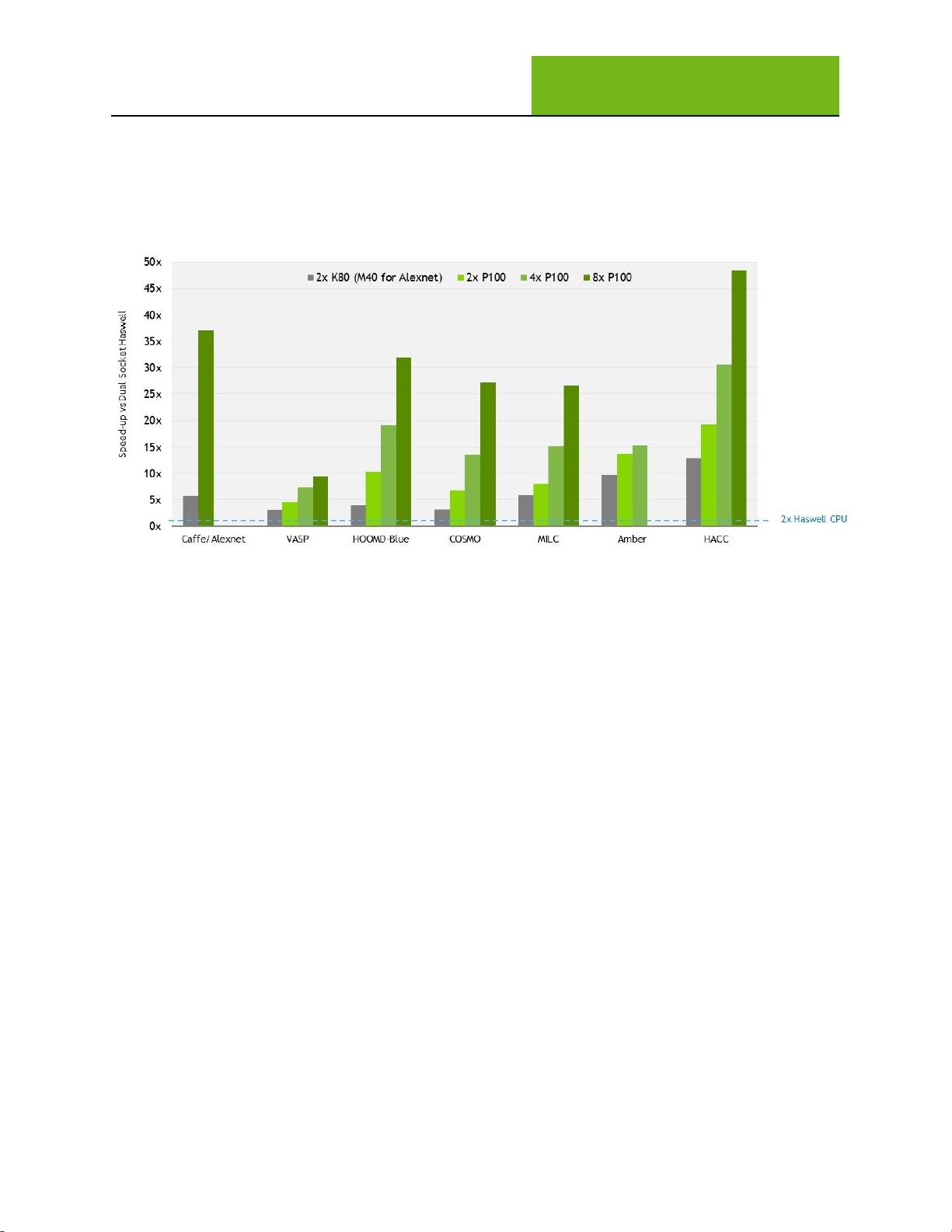
Figure 5 shows the performance for various workloads, demonstrating the performance scalability a
server can achieve with up to eight GP100 GPUs connected via NVLink. (Note: These numbers are
measured on pre-production P100 GPUs.)
Figure 5. Largest Performance Increase with Eight P100s connected via NVLink
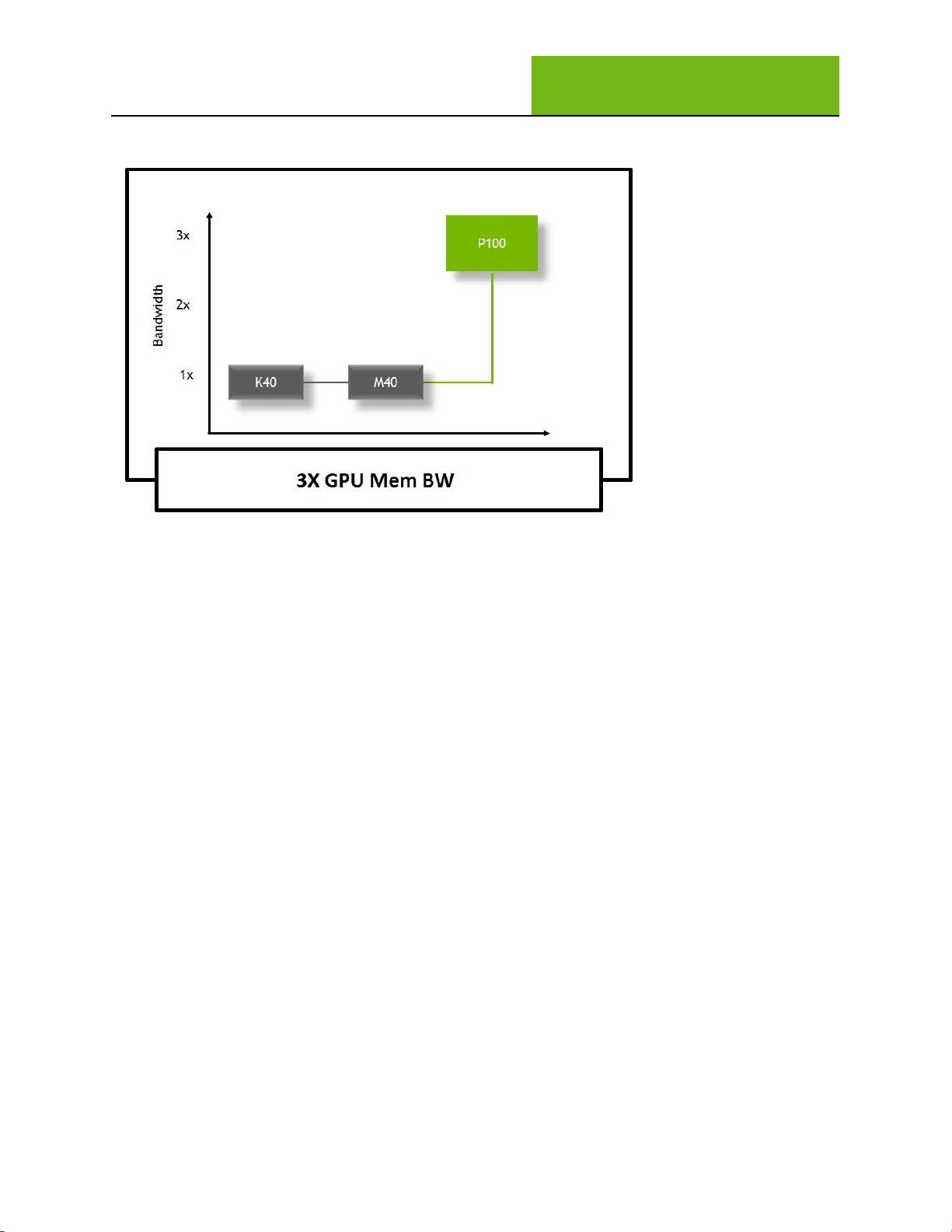
HBM2 High-Speed GPU Memory Architecture
Tesla P100 is the world’s first GPU architecture to support HBM2 memory. HBM2 offers three times (3x)
the memory bandwidth of the Maxwell GM200 GPU. This allows the P100 to tackle much larger working
sets of data at higher bandwidth, improving efficiency and computational throughput, and reduce the
frequency of transfers from system memory.
Because HBM2 memory is stacked memory and is located on the same physical package as the GPU, it
provides considerable space savings compared to traditional GDDR5, which allows us to build denser GPU
servers more easily than ever before.
剩余44页未读,继续阅读
2017-12-25 上传
2018-12-25 上传
2024-01-18 上传
2023-03-25 上传
2023-05-11 上传
2023-04-13 上传
2023-04-01 上传
2023-04-10 上传

lalalala256
- 粉丝: 28
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
