

6
of the same word. Specifically, for N different sentences where a word w is present, ELMo generates N different representations
of w i.e., w
1
, w
2
, ˙,w
N
.
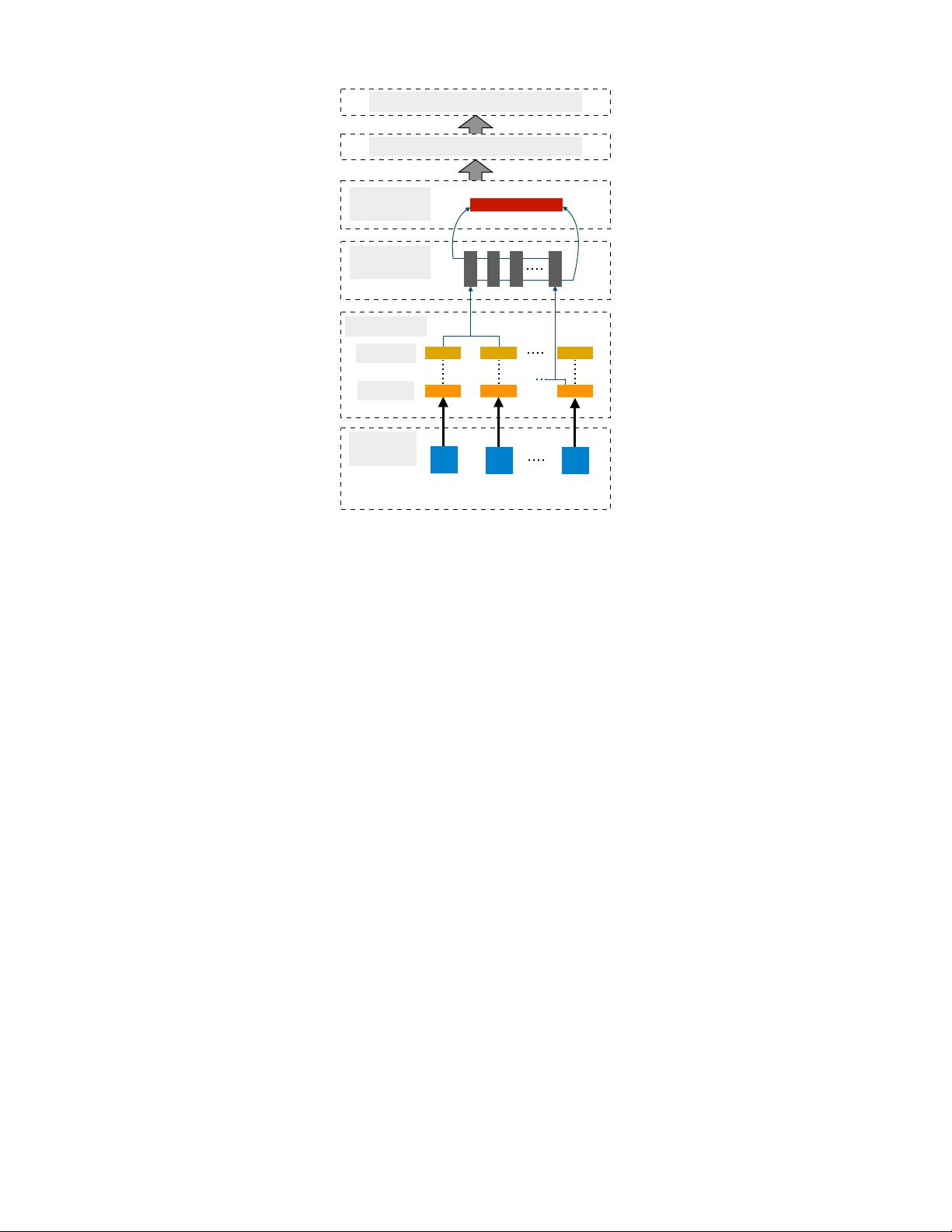
The mechanism of ELMo is based on the representation obtained from a bidirectional language model. A bidirectional
language model (biLM) constitutes of two language models (LM) 1) forward LM and 2) backward LM. A forward LM takes
input representation x
LM
k
for each of the k
th
token and passes it through L layers of forward LSTM to get representations
−→
h
LM
k,j
where j = 1, . . . , L. Each of these representations, being hidden representations of recurrent neural networks, is context
dependent. A forward LM can be seen as a method to model the joint probability of a sequence of tokens: p (t
1
, t
2
, . . . , t
N
) =
Q
N
k=1
p (t
k
|t
1
, t
2
, . . . , t
k−1
). At a timestep k −1 the forward LM predicts the next token t
k
given the previous observed tokens
t
1
, t
2
, ..., t
k
. This is typically achieved by placing a softmax layer on top of the final LSTM in a forward LM. On the other
hand, a backward LM models the same joint probability of the sequence by predicting the previous token given the future
tokens: p (t
1
, t
2
, . . . , t
N
) =
Q
N
k=1
p (t
k
|t
k+1
, t
k+2
, . . . , t
N
). In other words, a backward LM is similar to forward LM which
processes a sequence with the order being reversed. The training of the biLM model involves modeling the log-likelihood of
both the sentence orientations. Finally, hidden representations from both LMs are concetenated to compose the final token
vectors [42].
For each tokem, ELMo extracts the intermediate layer representations from the biLM and performs a linear combination
based on the given downstream task. A L-layer biLM contains 2L + 1 set of representations as shown below -
R
k
=
n
x
LM
k
,
−→
h
LM
k,j
,
←−
h
LM
k,j
|j = 1, . . . , L
o
=
h
LM
k,j
|j = 0, . . . , L
(6)
Here, h
LM
k,0
is the token representation at the lowest level. One can use either character or word embeddings to initialize
h
LM
k,0
. For other values of j,
h
LM
k,j
=
h
−→
h
LM
k,j
,
←−
h
LM
k,j
i
∀j = 1, . . . , L. (7)
ELMo flattens all layers in R in a single vector such that -
ELMo
task
k
= E
R
k
; Θ
task
= γ
task
L
X
j=0
s
task
j
h
LM
k,j
(8)
In Eq. 8, s
task
j
is the softmax-normalized weight vector to combine the representations of different layers. γ
task
is a hyper-
parameter which helps in optimization and task specific scaling of the ELMo representation. ELMo produces varied word
representations for the same word in different sentences. According to Peters et al. [41], it is always beneficial to combine
ELMo word representations with standard global word representations like Glove and Word2Vec.
Off-late, there has been a surge of interest in pre-trained language models for myriad of natural language tasks [43].
Language modeling is chosen as the pre-training objective as it is widely considered to incorporate multiple traits of natual
language understanding and generation. A good language model requires learning complex characteristics of language involving
syntactical properties and also semantical coherence. Thus, it is believed that unsupervised training on such objectives would
infuse better linguistic knowledge into the networks than random initialization. The generative pre-training and discriminative
fine-tuning procedure is also desirable as the pre-training is unsupervised and does not require any manual labeling.
Radford et al. [44] proposed similar pre-trained model, the OpenAI-GPT, by adapting the Transformer (see section IV-E).
Recently, Devlin et al. [45] proposed BERT which utilizes a transformer network to pre-train a language model for extracting
contextual word embeddings. Unlike ELMo and OpenAI-GPT, BERT uses different pre-training tasks for language modeling.
In one of the tasks, BERT randomly masks a percentage of words in the sentences and only predicts those masked words. In
the other task, BERT predicts the next sentence given a sentence. This task in particular tries to model the relationship among
two sentences which is supposedly not captured by traditional bidirectional language models. Consequently, this particular
pre-training scheme helps BERT to outperform state-of-the-art techniques by a large margin on key NLP tasks such as QA,
Natural Language Inference (NLI) where understanding relation among two sentences is very important. We discuss the impact
of these proposed models and the performance achieved by them in section VIII-I.
The described approaches for contextual word embeddings promises better quality representations for words. The pre-trained
deep language models also provide a headstart for downstream tasks in the form of transfer learning. This approach has been
extremely popular in computer vision tasks. Whether there would be similar trends in the NLP community, where researchers
and practitioners would prefer such models over traditional variants remains to be seen in the future.
III. CONVOLUTIONAL NEURAL NETWORKS
Following the popularization of word embeddings and its ability to represent words in a distributed space, the need arose
for an effective feature function that extracts higher-level features from constituting words or n-grams. These abstract features
would then be used for numerous NLP tasks such as sentiment analysis, summarization, machine translation, and question
answering (QA). CNNs turned out to be the natural choice given their effectiveness in computer vision tasks [46, 47, 48].
剩余31页未读,继续阅读

NLP_victor
- 粉丝: 110
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Lombok 快速入门与注解详解
- SpringSecurity实战:声明式安全控制框架解析
- XML基础教程:从数据传输到存储解析
- Matlab实现图像空间平移与镜像变换示例
- Python流程控制与运算符详解
- Python基础:类型转换与循环语句
- 辰科CD-6024-4控制器说明书:LED亮度调节与触发功能解析
- AE particular插件全面解析:英汉对照与关键参数
- Shell脚本实践:创建tar包、字符串累加与简易运算器
- TMS320F28335:浮点处理器与ADC详解
- 互联网基础与结构解析:从ARPANET到多层次ISP
- Redhat系统中构建与Windows共享的Samba服务器实战
- microPython编程指南:从入门到实践
- 数据结构实验:顺序构建并遍历链表
- NVIDIA TX2系统安装与恢复指南
- C语言实现贪吃蛇游戏基础代码
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


