
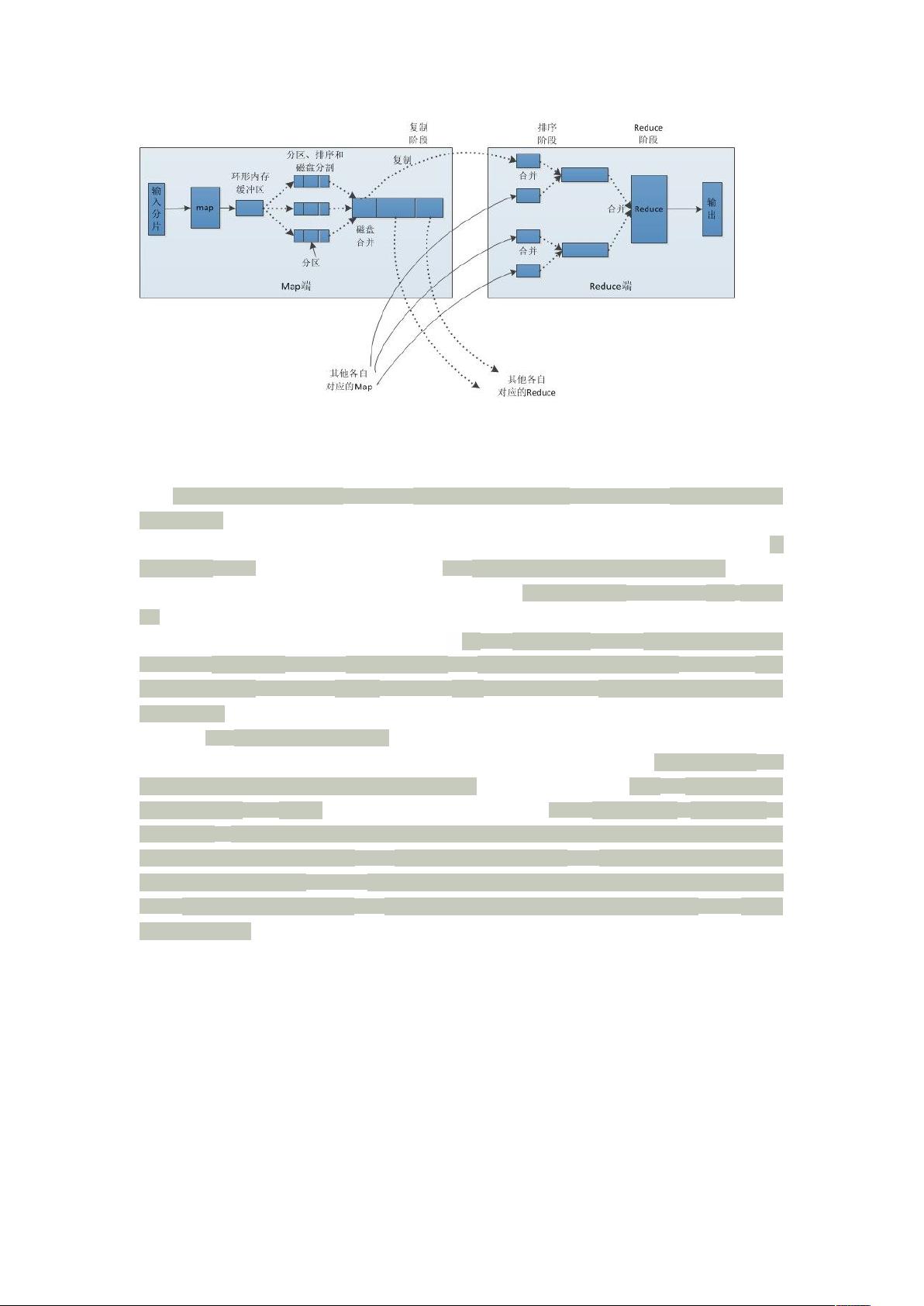
Shuffle 是 MapReduce 过程的核心,指的是 map 的结果输出到 reduce 的输入的过程,包括
map 端的 shuffle 和 reduce 端的 shuffle
Map 会把数据输出到环形缓存区中(100m),当到了一定的阀值 0.8,会把数据输出到磁
盘(一个后台线程就把内容写到(spill)Linux 本地磁盘中的指定目录(mapred.local.dir)下的新建的一个
溢出写文件。),写磁盘前,要先 partition,然后 sort。通过分区,每个分区对应不同的 reduce,
之后对不同分区的数据进行排序,如果有 Combine,还要对排序后的数据进行 combine(相
当于本机的 reduce),这个过程成为 spill(Spill 过程包括输出、排序、溢写、合并等步骤),当
整个 map 输出完成之后会进行 merge 多路归并排序(最大归并路数由 io.sort.factor 控制(默认是
10)),排序是先对 partition 排序,然后在一个 partition 里再排序的,最终 map 会输出一个
分区且排序的文件,等 map 完成之后 (一 个 Map 任 务 完 成 , Reduce 就 开 始 复 制 输 出 , 从
JobTracker 获得有哪些 map task 已执行结束,当 Map 任务完成之后,会通知他们的父 TaskTracker,告
知状态更新,然后 TaskTracker 再转告 JobTracker 或者 Application Master,这些通知信息是通过心跳通
信机制传输的),当 spill 文件归并完毕后,Map 将删除所有的临时 spill 文件,reduce 会拉
去数据(Http 方式得到输出文件的分区), copy 到 reduce 上面,同一个分区的数据会 copy 到
同一个 reduce 上面,然后对拷过来的文件排序,也会有 spill 的过程,(对于经过压缩的 Map
输出,系统会自动把它们解压到内存方便对其执行归并),多路归并和分组(只要 key 相同就属于同一
个组,放在一个 value 迭代器)merge 生成一个最终文件,(merge 有三种形式:1)内存到内存ˆ 2)
内存到磁盘ˆ 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。当内存中的数据量到
达一定阈值,就启动内存到磁盘的 merge(这过程会进行排序)。与 map 端类似,这也是溢写的过程,
这个过程中如果你设置有 Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种
merge 方式一直在运行,直到没有 map 端的数据时才结束,然后启动第三种磁盘到磁盘的 merge 方式生
成最终的那个文件)然后给 reduce 处理,再输出
主要函数是 fetchOutputs(),功能就是将 map 阶段的输出,copy 到 reduce 节点。
环形 buffer:首尾相连的数据结构,专门用来存储 Key-Value 格式的数据,其实就是一个字
节数组。
Buffer 索引是对 key-value 在 kvbuffer 中的索引,是个四元组,占用四个 Int 长度,包括:
value 的起始位置
key 的起始位置
partition 值
value 的长度
分区内的数据排序:快速排序算法(QuickSort)对 key 排序
Spill 文件名像 sipll0.out,spill1.out 等
剩余21页未读,继续阅读

cs1049281836
- 粉丝: 0
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机人脸表情动画技术发展综述
- 关系数据库的关键字搜索技术综述:模型、架构与未来趋势
- 迭代自适应逆滤波在语音情感识别中的应用
- 概念知识树在旅游领域智能分析中的应用
- 构建is-a层次与OWL本体集成:理论与算法
- 基于语义元的相似度计算方法研究:改进与有效性验证
- 网格梯度多密度聚类算法:去噪与高效聚类
- 网格服务工作流动态调度算法PGSWA研究
- 突发事件连锁反应网络模型与应急预警分析
- BA网络上的病毒营销与网站推广仿真研究
- 离散HSMM故障预测模型:有效提升系统状态预测
- 煤矿安全评价:信息融合与可拓理论的应用
- 多维度Petri网工作流模型MD_WFN:统一建模与应用研究
- 面向过程追踪的知识安全描述方法
- 基于收益的软件过程资源调度优化策略
- 多核环境下基于数据流Java的Web服务器优化实现提升性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


