深入解析:SparkSQL PhysicalPlan to RDD的转换机制
105 浏览量
更新于2024-08-28
收藏 213KB PDF 举报
在深入理解SparkSQL的Catalyst执行模型后,本文继续探讨PhysicalPlan到RDD的具体实现过程。当我们执行SQL查询时,真正的运行始于用户调用`collect()`方法触发Spark Job的执行,最终返回一个RDD。SparkPlan的核心操作类型分为基础操作(BasicOperator)和更复杂的如Join、Aggregate和Sort。
1. 基础操作:Project (投影)
Project操作是指根据给定的一系列命名表达式(Seq[NamedExpression])对输入的Row进行转换。它首先调用`child.execute()`获取子计划的结果,然后通过`mapPartitions`对每个分区应用`f`函数,这里实际上是创建一个`MutableProjection`对象。`MutableProjection`负责绑定输入表达式到一个预定义的schema,并执行表达式的计算(eval)。如果输入Row已有一个Schema,那么表达式会自动与该Schema关联。
```java
case class Project(projectList: Seq[NamedExpression], child: SparkPlan) extends UnaryNode {
override def output = projectList.map(_.toAttribute)
override def execute(): RDD[Row] = {
val reusableProjection = new MutableProjection(projectList)
child.execute().mapPartitions(iter => iter.map(reusableProjection))
}
}
```
2. 其他操作类型
除了Project,其他复杂操作如Join(合并两个数据集)、Aggregate(聚合操作)和Sort(排序)同样基于`execute()`方法,但它们可能涉及更复杂的逻辑,例如Join会涉及到shuffle操作,而Aggregate则会进行分组计算,通常会生成中间结果,这些中间结果在收集到driver节点前并不会被materialize。
这些操作的共同点在于,它们都遵循了Spark的延迟执行策略,直到真正需要结果(例如`collect()`或类似的触发器)时,才会触发相应的计算并将其转化为RDD。了解这些底层机制有助于开发者更好地优化SQL查询性能,比如理解何时选择使用`persist()`来缓存中间结果,或者如何利用Spark的分布式特性提高处理大规模数据的效率。
总结来说,从PhysicalPlan到RDD的转换是一个逐步细化和执行的过程,每个`SparkPlan`操作都会根据其类型和参数生成适当的RDD转换,确保SQL查询的高效执行。掌握这一系列转化过程对于深入理解SparkSQL的执行模型以及如何优化查询性能至关重要。
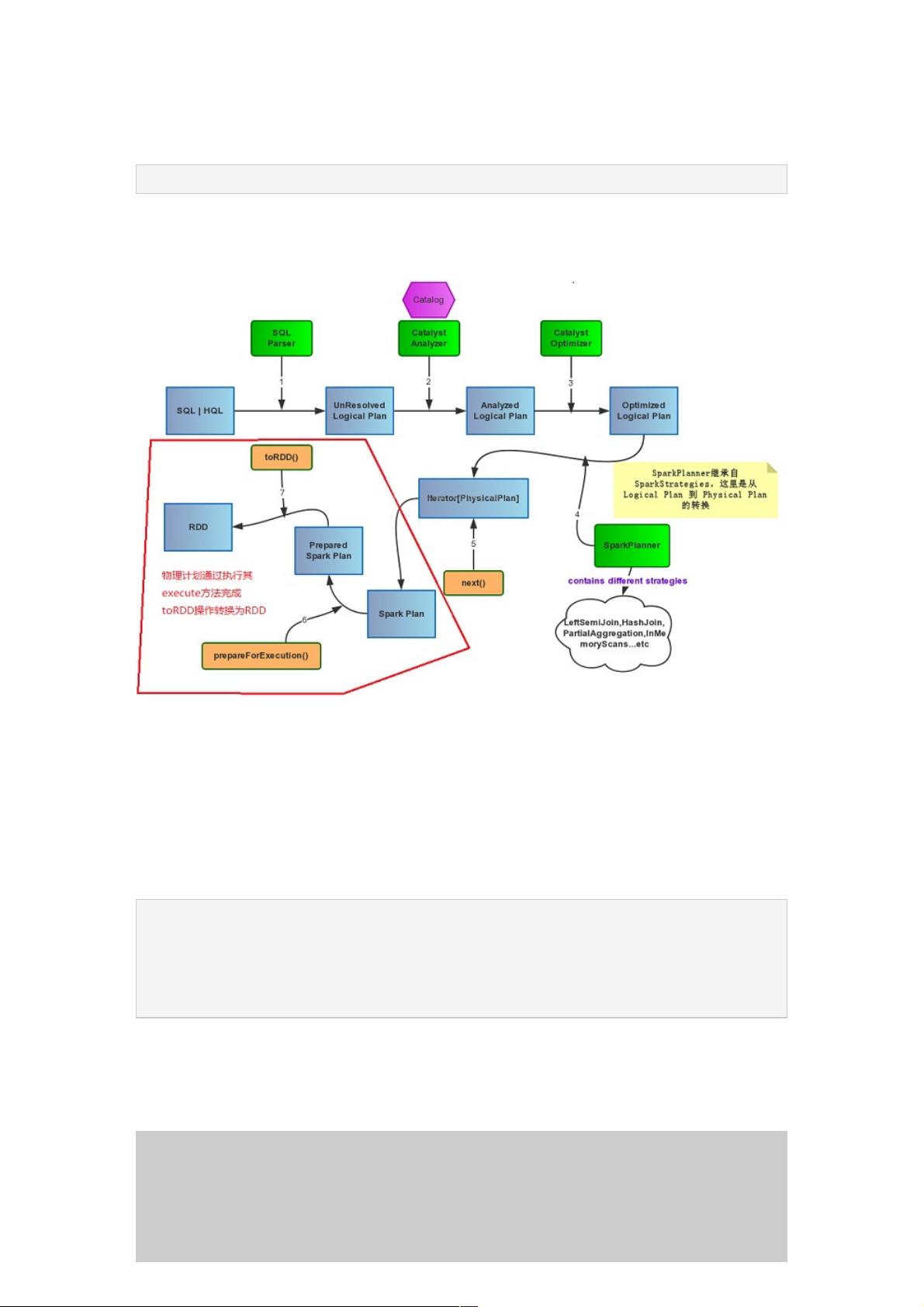
SparkSQL源码分析之源码分析之PhysicalPlan到到RDD的具体实现的具体实现
接上一篇文章Spark SQL Catalyst源码分析之Physical Plan,本文将介绍Physical Plan的toRDD的具体实现细节:
我们都知道一段sql,真正的执行是当你调用它的collect()方法才会执行Spark Job,最后计算得到RDD。
lazy val toRdd: RDD[Row] = executedPlan.execute()
Spark Plan基本包含4种操作类型,即BasicOperator基本类型,还有就是Join、Aggregate和Sort这种稍复杂的。
如图:
一、BasicOperator
1.1、Project
Project 的大致含义是:传入一系列表达式Seq[NamedExpression],给定输入的Row,经过Convert(Expression的计算
eval)操作,生成一个新的Row。
Project的实现是调用其child.execute()方法,然后调用mapPartitions对每一个Partition进行操作。
这个f函数其实是new了一个MutableProjection,然后循环的对每个partition进行Convert。
case class Project(projectList: Seq[NamedExpression], child: SparkPlan) extends UnaryNode {
override def output = projectList.map(_.toAttribute)
override def execute() = child.execute().mapPartitions { iter => //对每个分区进行f映射
@transient val reusableProjection = new MutableProjection(projectList)
iter.map(reusableProjection)
}
}
通过观察MutableProjection的定义,可以发现,就是bind references to a schema 和 eval的过程:
将一个Row转换为另一个已经定义好schema column的Row。
如果输入的Row已经有Schema了,则传入的Seq[Expression]也会bound到当前的Schema。
下载后可阅读完整内容,剩余7页未读,立即下载
139 浏览量
221 浏览量
920 浏览量
159 浏览量
点击了解资源详情
175 浏览量
104 浏览量
点击了解资源详情
146 浏览量

weixin_38748580
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Web远程教学系统需求分析指南
- 禅道6.2版本发布,优化测试流程,提高安全性
- Netty传输层API中文文档及资源包免费下载
- 超凡搜索:引领搜索领域的创新神器
- JavaWeb租房系统实现与代码参考指南
- 老冀文章编辑工具v1.8:文章编辑的自动化解决方案
- MovieLens 1m数据集深度解析:数据库设计与电影属性
- TypeScript实现tca-flip-coins模拟硬币翻转算法
- Directshow实现多路视频采集与传输技术
- 百度editor实现无限制附件上传功能
- C语言二级上机模拟题与VC6.0完整版
- A*算法解决八数码问题:AI领域的经典案例
- Android版SeetaFace JNI程序实现人脸检测与对齐
- 热交换器效率提升技术手册
- WinCE平台CPU占用率精确测试工具介绍
- JavaScript实现的压缩包子算法解读
