SparkSQL物理计划解析:从LogicalPlan到PhysicalPlan
12 浏览量
更新于2024-08-28
收藏 315KB PDF 举报
"SparkSQLCatalyst源码分析之PhysicalPlan"
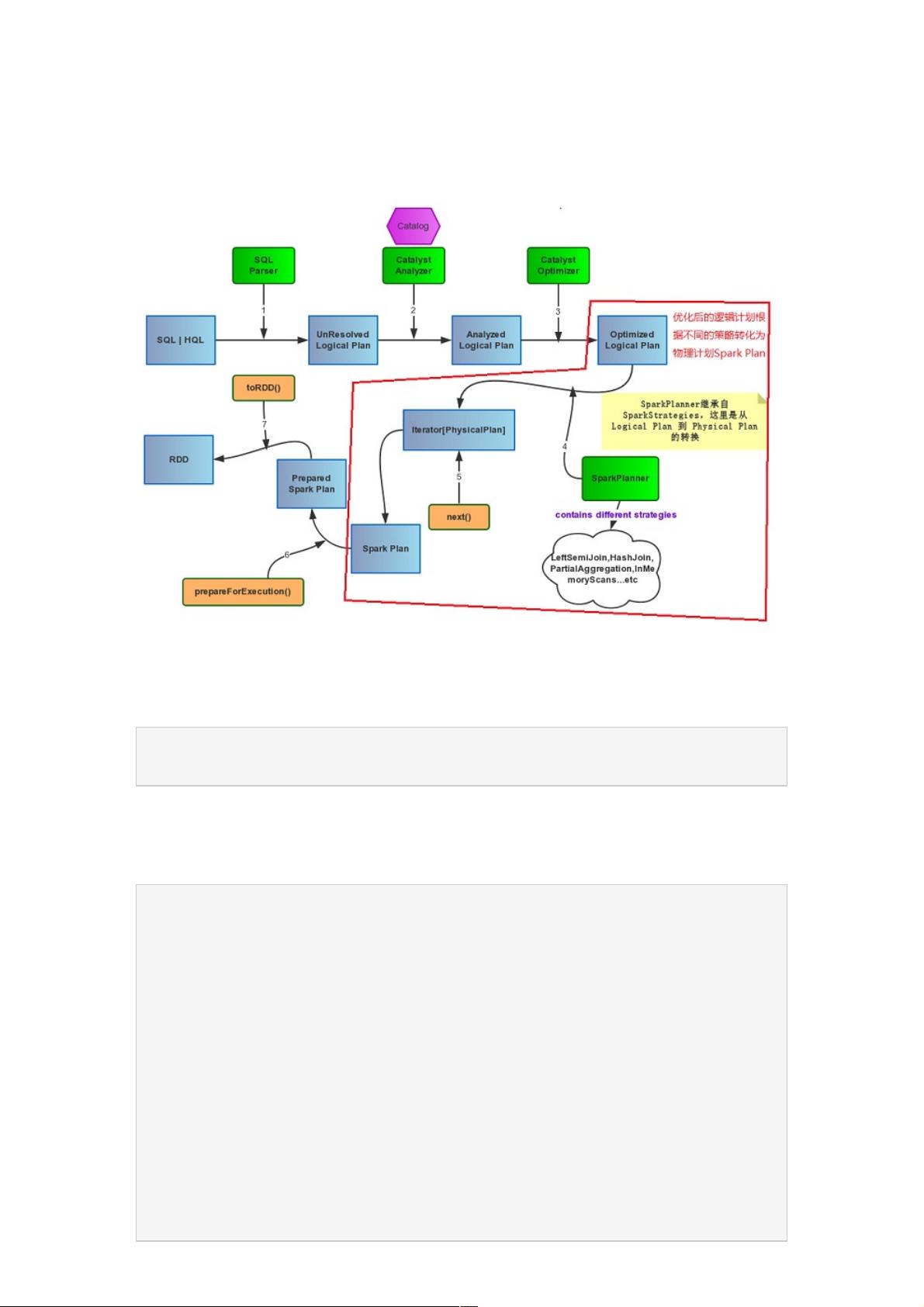
在Spark SQL的执行流程中,Catalyst优化器在解析、分析和优化SQL语句之后,会生成一个Physical Plan,这是Spark作业执行前的最后一个步骤。Physical Plan是逻辑计划(Logical Plan)经过优化后的具体执行方案,它详细描述了数据如何在Spark集群中实际操作和传输。
在Catalyst的框架下,Physical Plan的生成由`SparkPlanner`负责。当`Optimizer`完成了对`AnalyzedLogicalPlan`的优化后,`SparkPlanner`会接手并将其转化为一系列可能的`PhysicalPlan`实例。`SparkPlanner`继承自`SparkStrategies`,而`SparkStrategies`又继承自`QueryPlanner`。
`SparkPlanner`的核心功能在于其内部定义的`strategies`序列,这是一个包含多种策略(Strategy)的集合。每种策略都是`QueryPlanner`中定义的`Strategy`类型的子类,它们接受一个逻辑计划,并生成一个或多个物理计划。这些策略包括:
1. `CommandStrategy`: 处理SQL命令,如创建表、删除表等。
2. `TakeOrdered`: 实现按指定顺序取数据的操作。
3. `PartialAggregation`: 执行部分聚合操作,通常用于分布式计算中的局部预处理。
4. `LeftSemiJoin`: 处理左半连接操作,只保留左表中的匹配行。
5. `HashJoin`: 使用哈希连接算法实现两个表的连接操作。
6. `InMemoryScans`: 处理内存中的数据扫描,如DataFrame或RDD的读取。
7. `ParquetOperation`: 针对Parquet格式的数据进行操作,如读取或写入。
`SparkPlanner`在选择物理计划时,会根据这些策略生成的备选计划,然后根据具体配置和性能考量选取最适合的执行计划。在这个过程中,可能会涉及分区、并行度、数据源特性和内存管理等多个因素。
`SparkPlanner`和其策略集合是将优化后的逻辑计划转化为实际操作指令的关键组件,它们确保Spark SQL能够高效地执行复杂的查询和数据处理任务。理解这一过程对于优化Spark应用的性能和调试SQL查询异常至关重要。
SparkSQLCatalyst源码分析之源码分析之PhysicalPlan
前面几篇文章主要介绍的是spark sql包里的的spark sql执行流程,以及Catalyst包内的SqlParser,Analyzer和Optimizer,最
后要介绍一下Catalyst里最后的一个Plan了,即Physical Plan。物理计划是Spark SQL执行Spark job的前置,也是最后一道计
划。
如图:
一、SparkPlanner
话接上回,Optimizer接受输入的Analyzed Logical Plan后,会有SparkPlanner来对Optimized Logical Plan进行转换,生成
Physical plans。
lazy val optimizedPlan = optimizer(analyzed)
// TODO: Don't just pick the first one...
lazy val sparkPlan = planner(optimizedPlan).next()
SparkPlanner继承了SparkStrategies,SparkStrategies继承了QueryPlanner。
SparkStrategies包含了一系列特定的Strategies,这些Strategies是继承自QueryPlanner中定义的Strategy,它定义接受一个
Logical Plan,生成一系列的Physical Plan
@transient
protected[sql] val planner = new SparkPlanner
protected[sql] class SparkPlanner extends SparkStrategies {
val sparkContext: SparkContext = self.sparkContext
val sqlContext: SQLContext = self
def numPartitions = self.numShufflePartitions //partitions的个数
val strategies: Seq[Strategy] = //策略的集合
CommandStrategy(self) ::
TakeOrdered ::
PartialAggregation ::
LeftSemiJoin ::
HashJoin ::
InMemoryScans ::
ParquetOperations ::
BasicOperators ::
CartesianProduct ::
BroadcastNestedLoopJoin :: Nil
etc......
}
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-02-21 上传
2021-03-03 上传
2021-01-30 上传
2021-01-30 上传
点击了解资源详情
2024-12-20 上传

weixin_38654415
- 粉丝: 4
- 资源: 1015
 我的内容管理
展开
我的内容管理
展开







最新资源
- CoreOS部署神器:configdrive_creator脚本详解
- 探索CCR-Studio.github.io: JavaScript的前沿实践平台
- RapidMatter:Web企业架构设计即服务应用平台
- 电影数据整合:ETL过程与数据库加载实现
- R语言文本分析工作坊资源库详细介绍
- QML小程序实现风车旋转动画教程
- Magento小部件字段验证扩展功能实现
- Flutter入门项目:my_stock应用程序开发指南
- React项目引导:快速构建、测试与部署
- 利用物联网智能技术提升设备安全
- 软件工程师校招笔试题-编程面试大学完整学习计划
- Node.js跨平台JavaScript运行时环境介绍
- 使用护照js和Google Outh的身份验证器教程
- PHP基础教程:掌握PHP编程语言
- Wheel:Vim/Neovim高效缓冲区管理与导航插件
- 在英特尔NUC5i5RYK上安装并优化Kodi运行环境
