实时计算平台:Flink基础与实践
版权申诉
149 浏览量
更新于2024-07-05
收藏 7.23MB PDF 举报
"实时计算平台架构与实践"
这篇文档主要探讨了实时计算平台的架构及其在实际应用中的实践,由58大数据平台系列直播的分享人冯海涛进行讲解。内容涵盖了实时计算的基础能力建设、平台化建设,以及对Flink、Storm和Spark Streaming等实时计算框架的比较。
实时计算平台的定位是为集团海量数据提供高效、稳定的一站式服务,包括实时数据存储、计算和转发。平台使用的技术包括Kafka、Storm和Flink,以及DDS数据分发平台和Wstream一站式实时计算平台。基础能力建设方面,Flink因其低延迟、高吞吐量、强大的容错机制(Exactlyonce语义)和状态管理能力而被重视。
Flink的计算模型是streaming,与Storm的微批处理(Micobatching)和Spark Streaming的批处理模型不同,它更适合处理数据乱序和需要低延迟的场景。Flink还具有高可用架构和任务隔离,确保了集群的稳定性。此外,Flink通过细粒度资源管理和易用性的提升,如支持HDFS的LZO压缩、自动处理换行、第三方依赖JAR的管理等,进一步增强了其功能。
流式SQL的引入降低了开发门槛,提供了稳定的语法和易于理解的结构,同时具备自动优化的能力,支持批流统一,满足了数据仓库实时化的需求。该平台基于FlinkSql扩展,支持自定义DDL和UDF语法,实现了流与维表的join,并连接了主流存储和公司内部的实时存储系统。
文档还提到了DDL原理,使用Apache Calcite进行语法解析,遵循SQL:2011TemporalTable标准,以提高性能。此外,Flink通过FlinkAysncI/O、缓存机制(如LRU/ALL)、社区贡献的优化(如topN、Minibatch、ROW_NUMBER高效去重、Local-Global数据热点和MATCH_RECOGNIZEcep支持)等进一步提升了效率。
对于Storm到Flink的迁移,文档指出Storm集群存在的一些问题,而Flink由于其编程模型的简洁性、开发成本较低以及性能优势,成为了一个更优的选择。这份资料详细介绍了实时计算平台的构建和优化,以及Flink在实时计算领域的核心价值和优势。
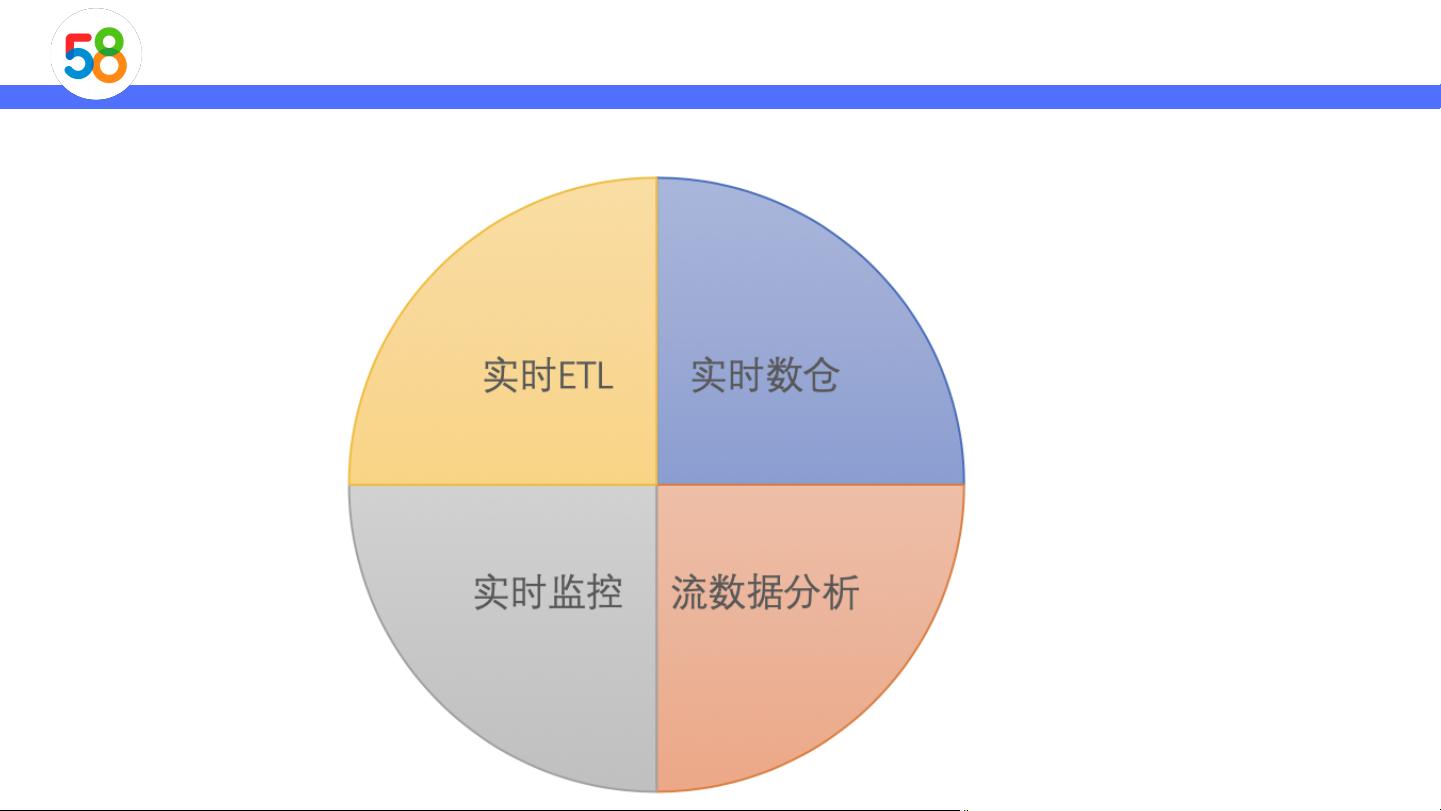
实时计算场景
剩余34页未读,继续阅读
2020-02-06 上传
2023-07-28 上传
2023-07-09 上传
2023-06-21 上传
2023-07-08 上传
2023-06-19 上传
2023-06-21 上传
2024-01-23 上传
2023-07-12 上传

行业报告
- 粉丝: 4
- 资源: 6234
 我的内容管理
展开
我的内容管理
展开







最新资源
- 天池大数据比赛:伪造人脸图像检测技术
- ADS1118数据手册中英文版合集
- Laravel 4/5包增强Eloquent模型本地化功能
- UCOSII 2.91版成功移植至STM8L平台
- 蓝色细线风格的PPT鱼骨图设计
- 基于Python的抖音舆情数据可视化分析系统
- C语言双人版游戏设计:别踩白块儿
- 创新色彩搭配的PPT鱼骨图设计展示
- SPICE公共代码库:综合资源管理
- 大气蓝灰配色PPT鱼骨图设计技巧
- 绿色风格四原因分析PPT鱼骨图设计
- 恺撒密码:古老而经典的替换加密技术解析
- C语言超市管理系统课程设计详细解析
- 深入分析:黑色因素的PPT鱼骨图应用
- 创新彩色圆点PPT鱼骨图制作与分析
- C语言课程设计:吃逗游戏源码分享
